圖像文字識別—人工智能的慧眼
前言
人類對世界的感知大約80%是通過視覺獲取的,因此,如何讓計算機具備甚至超越人類的視覺能力一直以來都是科學研究的重要方向。圖像文字識別技術是計算機視覺技術的重要組成部分,在日常生活中具有重要的價值和意義。
現狀
圖像文字識別是指識別圖像中的文字。傳統的文字識別的一般框架如圖1所示,包括預處理、特征提取、分類器設計三個主要模塊[1]。首先經過預處理操作,形成規定的圖片大小,使字符位置在圖片中心,然后對預處理后的圖片提取字符特征,***分類器根據提取的特征對字符進行分類。圖像文字識別的預處理部分主要包括樣本歸一化、平滑去噪、偽樣本生成技術;特征提取部分可以分為結構特征和統計特征兩種,結構特征主要是對文字結構、筆畫或部件來進行提取,統計特征目前比較常用的是Garbor特征和Gradient特征;分類器常用的有SVM、HMM、二次判決函數等。
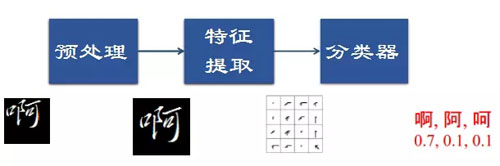
圖1 傳統文字識別框架圖
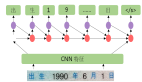
近幾年,基于上述方法在識別性能上的研究進展不大,主要是字符分類結果主要依賴于提取的特征,但是很難設計出比較穩健的特征。而自從有了深度學習技術,文字識別又有了新的活力,我們可以利用深度學習技術如CNN、DNN、RNN可以把文字識別問題解決的很好并且識別過程也不像傳統方法那么復雜,不用做預處理和手工設計特征、提取特征操作,直接將文字圖像作為網絡的輸入。并且文字識別一直是深度學習一個主要的應用方向,上世紀90年代,深度學習的先驅者如Y. Lecun和Bengio合作設計了LeNet5解決了手寫數字識別問題,圖2是他們在貝爾實驗室做的Demo。
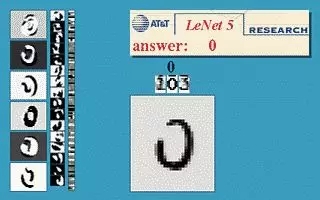
圖2 手寫數字識別demo圖
而簡單利用深度學習解決漢字識別,效果并不是很理想,近幾年研究者針對漢字識別問題也做了大量的工作,發現加上一些領域的知識并結合CNN的方法可以更好地解決中文識別問題。如使用數據生成技術生成大量的樣本數據來防止過擬合問題[2]和傳統特征提取方法結合CNN方法提高識別效果。Zhong[3]等人提出用特征提取+CNN的方法來識別手寫漢字,提取的特征是八方向的Garbor特征、梯度特征和HOG特征,積字的特征圖如圖3所示。他們改進的AlexNet和GoogleNet網絡結構如圖4與圖5所示,和原先結構相比他們在輸入層做了改進,將特征圖像也作為輸入層,***的集成網絡結構的識別結果在CASIA-HWDB數據集上達到96.74%,***超過人類的識別水平(96.13%)。
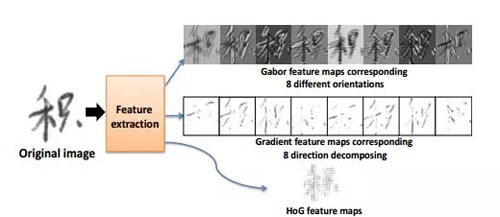
圖3“積”字特征圖
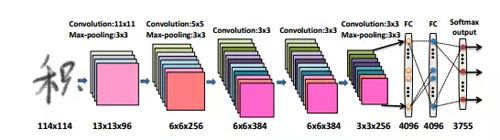
圖4 離線手寫體漢字識別AlexNet結構圖
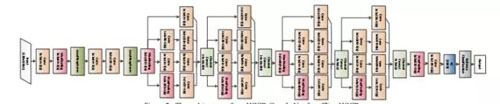
圖5 離線手寫體漢字識別GoogleNet結構圖
目前,使用深度學習技術進行單字符識別在某種程度上取得了很好的效果,大量學者開始研究含序列信息的文本行的識別[4]。針對此問題,有極大潛力的解決方法是應用神經回歸網絡(RNN)模型、LSTM、BLSTM(Bidirectional long short term memory)等模型,因為這些模型對序列數據有很好的建模能力,因此它們適合解決有時序先后順序信息的文字行識別的問題。基于LSTM-RNN方法在英文、拉丁文等西方語言的文本行識別中取得了很好的效果[5-7],文獻[8]***將LSTM-RNN模型用于中文的文本行識別,也達到此領域先進的水平。總之RNN+CNN可以訓練端到端的深度學習模型,也是研究文字識別的主要方法。
應用
文字識別在生活中有廣泛的應用。例如我們比較熟悉的移動設備上的手寫文字識別,手寫輸入功能已成為移動設備(手機、pad)的標配。
圖6 移動設備手寫識別
文字識別實現辦公自動化將紙質文件轉換為電子文檔。還有證件的識別和郵政地址的識別也早已得到應用。
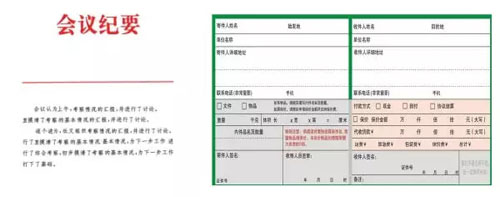
圖7 文檔圖像識別
此外,文字識別還有很多有趣的應用,比如可以輔助我們進行圖像的搜索和分類,AR眼鏡實現實時場景包括街景文字的翻譯。
圖8 場景文字識別
在未來,文字識別也有很大的應用市場,如在圖像搜索引擎、自動駕駛、金融保險、AR、智能機器人、教育醫療等方面都有很多的應用[9]。并且還可以產生很多的創新應用,如可以讓盲人看懂世界、盲人看大片等。
結語
目前的人工智能中有不同的識別引擎,也就相當于用不同的眼睛來解決視覺感知問題,并且文字識別作為人工智能中一個典型的模式識別問題,雖經歷了幾十年的發展取得了很好的成就,但做的還不夠智能和通用。其在許多方面都還值得研究,如把手寫、表單、名片、場景文字等用一個通用的統一的方案來解決這個問題,這樣文字識別這個眼睛才能真正稱得上是人工智能中一只智慧的眼睛。
參考文獻:
[1] 金連文, 鐘卓耀, 楊釗,等. 深度學習在手寫漢字識別中的應用綜述[J]. 自動化學報, 2016, 42(8):1125-1141.
[2] Yang W, Jin L, Liu M. Chinese character-level writer identification using path signature feature, DropStroke and deep CNN[J]. 2015:546-550.
[3] Zhong Z, Jin L, Xie Z. High performance offline handwritten Chinese character recognition using GoogLeNet and directional feature maps[C]// International Conference on Document Analysis and Recognition. IEEE Computer Society, 2015:846-850.
[4] Liao M, Shi B, Bai X, et al. TextBoxes: A Fast Text Detector with a Single Deep Neural Network[J]. 2016.
[5] Frinken V, Uchida S. Deep BLSTM neural networks for unconstrained continuous handwritten text recognition[C]// International Conference on Document Analysis and Recognition. IEEE Computer Society, 2015:911-915.
[6] Rawls S, Cao H, Kumar S, et al. Combining Convolutional Neural Networks and LSTMs for Segmentation-Free OCR[C]// Iapr International Conference on Document Analysis and Recognition. IEEE Computer Society, 2017:155-160.
[7] Simistira F, Ulhassan A, Papavassiliou V, et al. Recognition of historical Greek polytonic scripts using LSTM networks[C]// International Conference on Document Analysis and Recognition. 2015:766-770.
[8] Messina R, Louradour J. Segmentation-free handwritten Chinese text recognition with LSTM-RNN[C]// International Conference on Document Analysis and Recognition. IEEE, 2015:171-175.
[9] https://v.qq.com/x/page/u0516hq8ql5.html.

【本文為51CTO專欄作者“中國保密協會科學技術分會”原創稿件,轉載請聯系原作者】