這幾個案例以前是給一些想進入Python行業的朋友寫的,看到大家都比較滿意,所以就再次拿了出來,如果你已經開始學python,對爬蟲沒有頭緒,不妨看看這幾個案例!
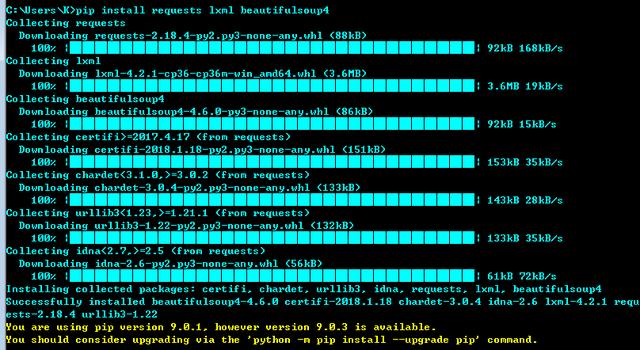
二、環境準備
Python 3
requests庫 、lxml庫、beautifulsoup4庫
pip install XX XX XX一并安裝。
三、Python爬蟲小案例
1、獲取本機的公網IP地址
利用python的requests庫+公網上查IP的接口,自動獲取IP地址

2、利用百度的查找接口,Python編寫url采集工具
需要用到requests庫、BeautifulSoup庫,觀察百度搜索結構的URL鏈接規律,繞過百度搜索引擎的反爬蟲機制的方法為在程序中設置User-Agent請求頭。

Python源代碼:
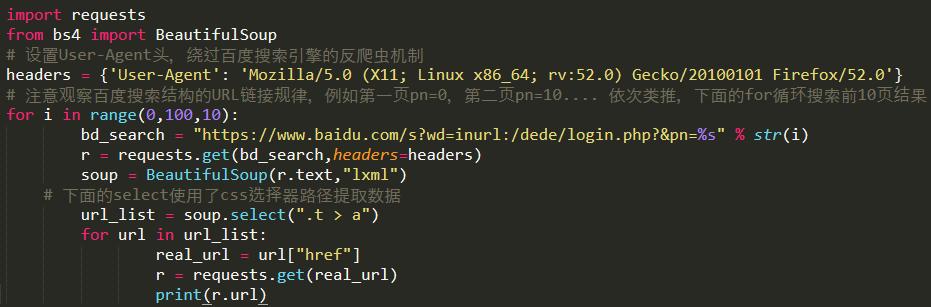
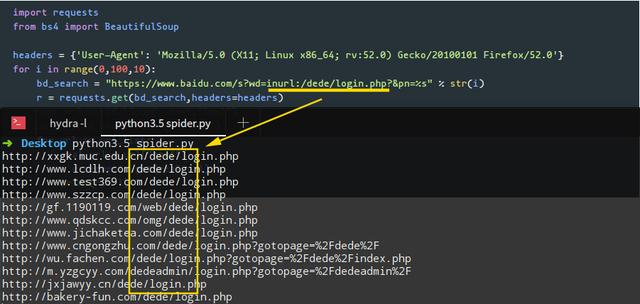
Python語言編寫好程序后,利用關鍵詞inurl:/dede/login.php 來批量提取某網cms的后臺地址:
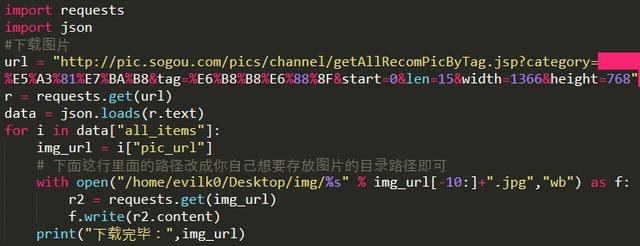
3、利用Python打造搜狗壁紙自動下載爬蟲
搜狗壁紙的地址是json格式,所以用json庫解析這組數據,爬蟲程序存放圖片的磁盤路徑改成欲存圖片的路徑就可以了。
效果圖:
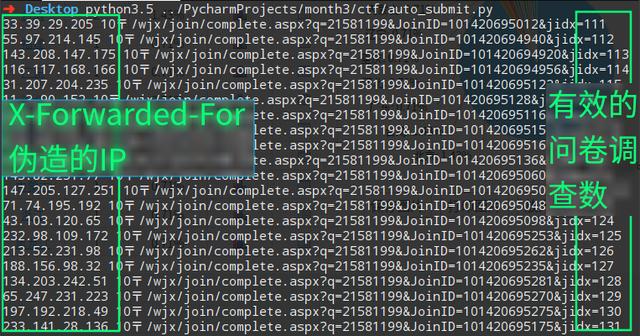
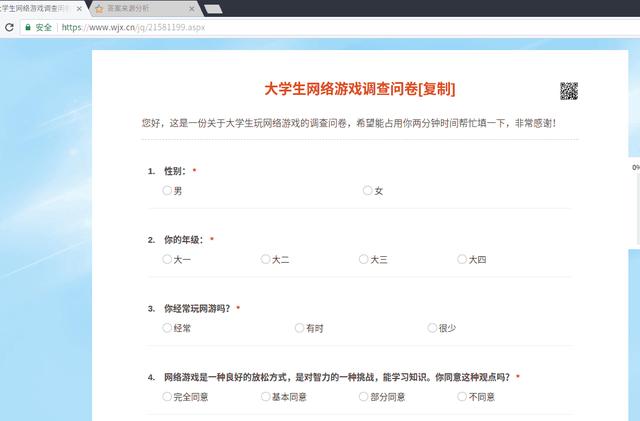
4、Python自動填寫問卷調查
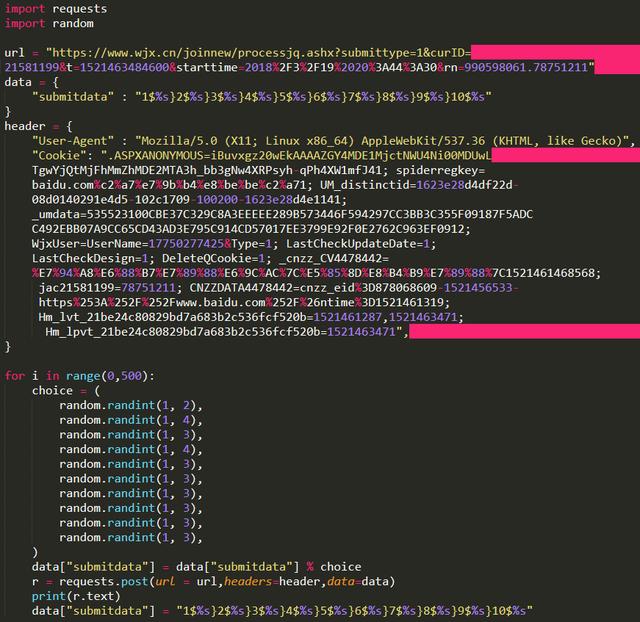
與一般網頁一樣,多次提交數據會要輸入驗證碼,這就是反爬機制。
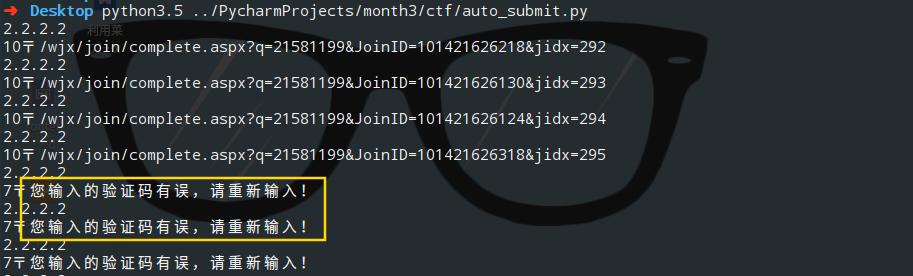
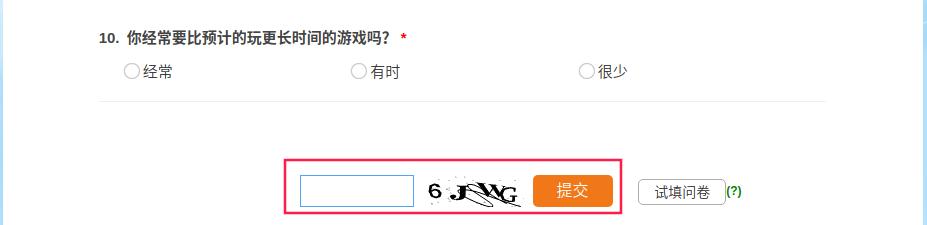
如圖:
那么如何繞過驗證碼的反爬措施?利用X-Forwarded-For偽造IP地址訪問即可,Python代碼如下:
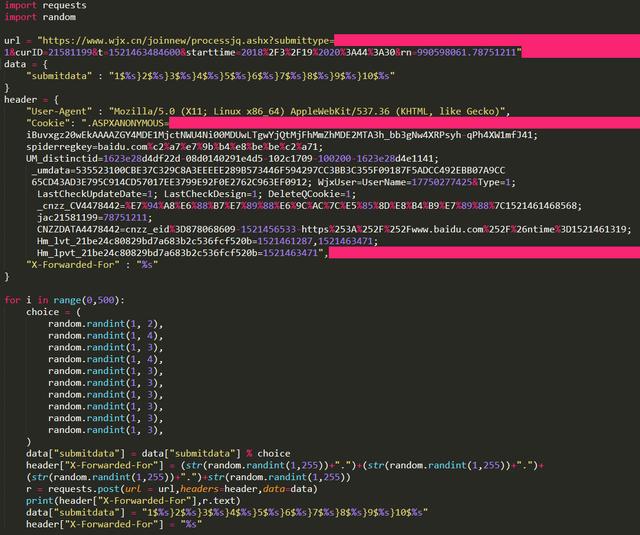
效果:
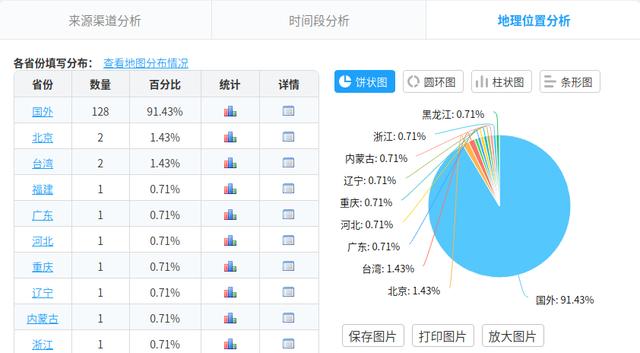
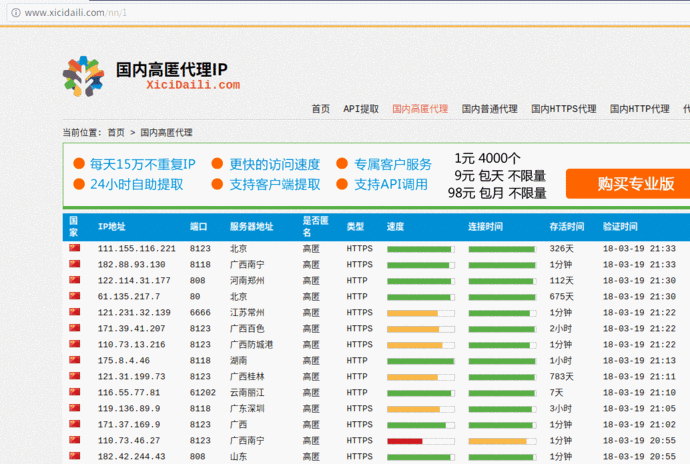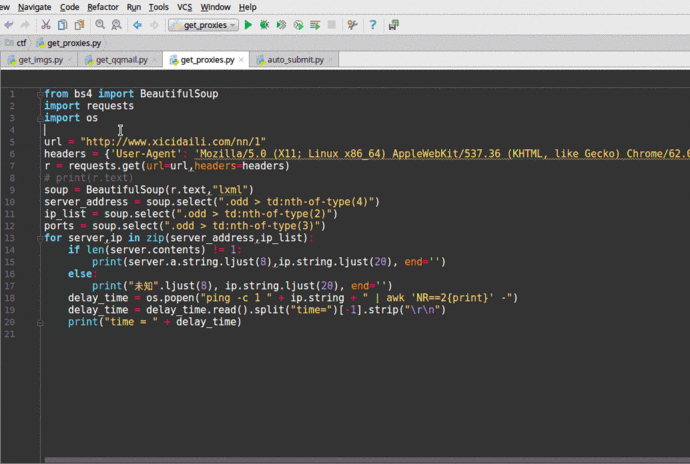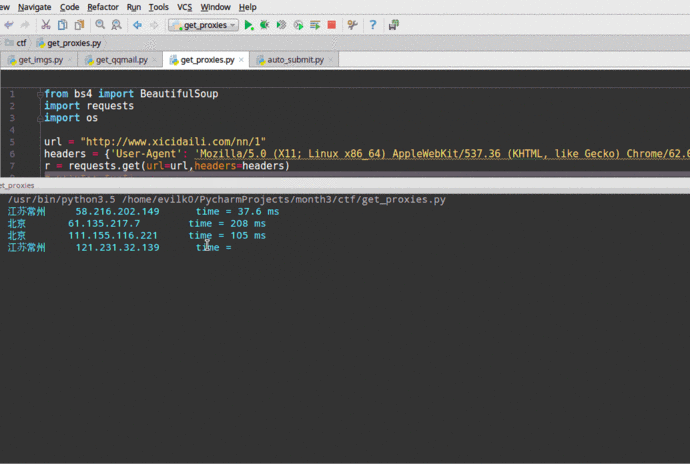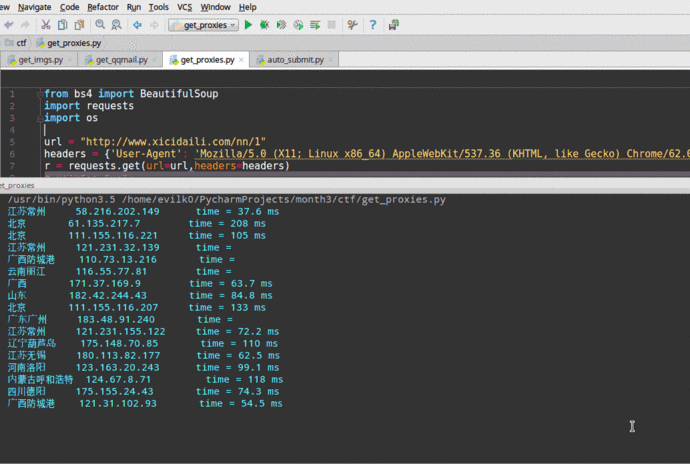
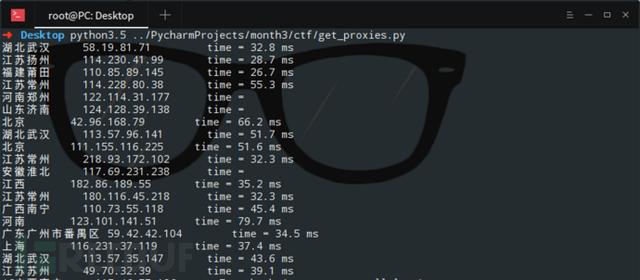
5、獲取西刺代理上的IP,驗證這些代理被封禁掉的可能性與延遲時間
可以把Python爬取的代理IP添加到proxychain里面,就可以進行一般的滲透任務了。這里直接調用了linux的系統命令ping -c 1 " + ip.string + " | awk 'NR==2{print}' - ,在Windows中運行此程序需要修改倒數第三行os.popen里的命令,修改為Windows能夠執行的就可以了。
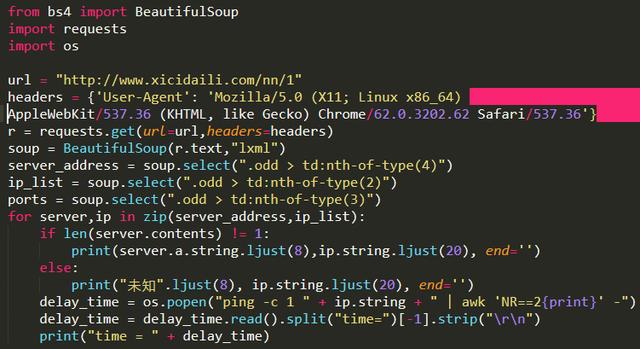
爬取到的數據如圖:
演示: