













機器學習團隊需要更好的特征工程技術
特征工程技能是為機器學習優化的數據特征,它與數據科學本身一樣歷史悠久。但我注意到,這一技能正變得越來越被忽視。對機器學習的高需求產生了大量的數據科學家,他們在工具和算法方面擁有專業知識,但缺乏特性工程所需的經驗和特定行業的領域知識。他們試圖用更好的工具和算法來彌補這一點。然而,算法現在是一種商品,不產生企業知識產權。
像Amazon ML和谷歌AutoML這樣的通用數據正在變得商品化,基于云計算的機器學習服務(MLaaS),如Amazon ML和Google AutoML,現在可以讓毫無經驗的團隊在幾分鐘內運行數據模型并獲得預測。因此,主導權正在轉向那些在收集或制造專有數據方面發展組織能力的公司,通過特征工程實現。簡單的數據采集和模型構建已不再適用。
企業團隊可以從建模競賽的獲獎者那里學到很多東西,例如KDD杯和遺產提供者網絡健康獎,他們認為特色工程是他們成功的關鍵因素。
一、特征工程技術
為了支持特征工程,數據科學家開發了一系列技術。它們可以被廣泛地視為:
1、語境轉換
一組方法涉及將各個特征從原始集轉換為針對每個特定模型的更多上下文有意義的信息。
例如,在處理分類特征時,“未知”可能會在特定情況的上下文中傳達特殊信息。但是,在模型中,它看起來只是另一個類別值。在這種情況下,團隊可能希望引入“has_value”的新二進制功能,以將“未知”與所有其他選項分開。例如,“顏色”功能允許輸入“has_color”用于未知顏色的內容。
另一種方法是使用單熱編碼將分類特征轉換為一組變量。在上面的示例中,將“顏色”類別轉換為三個特征(“紅色”,“綠色”和“藍色”各一個)可以根據模型的目標實現更好的學習過程。
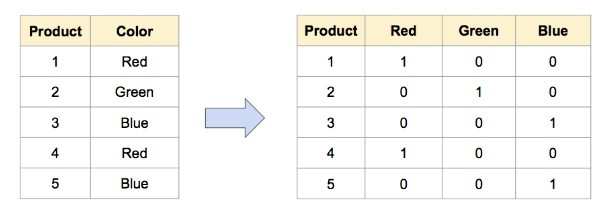
機器學習團隊還經常使用分級作為將單個特征轉換為多個特征的方法,以獲得更好的洞察力。例如,將'age'特征分為'young'為<40,'middle_age'為40-60,'old'為> 60。
其他一些轉換的例子是:
將變量的最小值 - 最大值(例如年齡)之間的值縮放到[0,1]的范圍內
將每種類型的餐廳的訪問次數除以美食的“興趣”指標
2、多特征算術
特征工程的另一種方法是將算術公式應用于一組現有數據點。公式可以基于特征,比率和其他關系之間的相互作用來創建衍生物。
這種類型的特征工程可以提供高價值,但需要對模型的主題和目標有充分的了解。
示例包括使用公式:
從“學校評級”和“犯罪率”的組合計算“鄰里質量”
通過比較訪客的“實際支出”和“預期支出”來確定“賭場運氣因素”
通過將信用卡“余額”除以“限制”來產生“利用率”
從特定時間范圍內的“最近交易”,“交易頻率”和“花費的金額”的組合中獲取RFM分數(新近度,頻率,貨幣)以對客戶進行分段。
3、先進的技術
團隊還可以選擇更高級的算法方法來分析現有數據,以尋找創建新功能的機會。
主成分分析(PCA)和獨立成分分析(ICA)將現有數據映射到另一個特征空間
深度特征合成(DFS)允許從神經網絡中的中間層轉移中間學習
二、設置成功的框架
團隊必須不斷尋找更有效的功能和模型。但是,為了取得成功,這項工作必須在有條不紊和可重復的框架內完成。以下是任何功能工程工作的六個關鍵步驟:
1.明確模型用法。首先澄清模型的主要目標和用例。整個團隊必須保持同步并以單一目的工作。否則,你會減少努力并浪費資源。
2.設置標準。構建高性能模型的過程需要仔細探索和分析可用數據。但是工作計劃也需要適應現實世界的障礙。在特征化過程中考慮諸如成本,可訪問性,計算限制,存儲約束和其他要求等因素。團隊必須盡早調整這些偏好或限制。
3.構思新功能。廣泛思考如何創建新數據以更好地描述和解決問題。此時,領域知識和主題專家的參與將確保您的特征工程的結果增加價值。
4.構造要素作為輸入。一旦確定了新的特征概念,請從可用數據中選擇最有效的技術來構建它們。選擇正確的技術是確保新功能有用性的關鍵。
5.研究影響。評估新功能對模型性能的影響。關于新特征增加值的結論直接取決于如何測量模型的功效。
模型性能度量必須與業務度量相關才能有意義。如今,團隊擁有大量的測量選項,遠遠超出準確性,例如精度,召回率,F1分數和接收器操作特性(ROC)曲線。
6.優化功能。特征工程是一個涉及測試,調整和改進新特征的迭代過程。此過程中的優化循環有時會導致刪除低性能特征或使用緊密變體替換,直到識別出最高影響特征。
總結
特征工程是我們現代世界的新煉金術,成功的團隊將通用數據轉化為其組織的增值知識產權。
幾項重要原則有助于推動這項工作取得成功:
- 包括主題專業知識,以確保計劃從明確了解業務目標和模型有效性的相關措施開始
- 通過迭代和系統的過程
- 考慮可用的許多可能的特征選項
- 了解并監控功能選擇如何影響模型性能
- 將數據轉換為驅動有意義模型的專有功能的這種能力可以創造重要價值并確保組織的競爭優勢。


















