













終于把機器學習中的特征工程搞懂了!!
特征工程是機器學習中的重要步驟之一,其目的是通過對原始數據進行處理、變換或生成新的特征,以增強模型的學習能力和預測性能。


特征工程直接影響機器學習模型的表現,因為模型的效果很大程度上取決于輸入數據的質量和特征的選擇。
下面,我們來分享10個常用的特征工程技術。
1.插補
插補是處理數據集中的缺失值的一種常用方法。
大多數機器學習算法無法直接處理缺失值,因此在特征工程中必須解決這個問題。
插補方法根據已有的數據推測或生成合理的替代值,以填補缺失的數據。
常見插補方法:
- 均值插補,將缺失值用該特征的均值替代,適用于數值型數據。
- 中位數插補,用中位數替代缺失值,適用于具有異常值的數值數據,因為中位數對極端值不敏感。
- 眾數插補,對于類別型數據,使用該特征的眾數(最常出現的值)進行插補。
- K近鄰插補,基于 K 最近鄰算法,用與缺失值最近的 K 個相似樣本的平均值進行插補。
- 插值,對時間序列或連續數據,可以使用線性插值或多項式插值方法進行插補。
優缺點
- 插補可以讓數據集保持完整,但如果插補策略不當,可能會引入偏差或噪聲,影響模型的性能。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import gensim.downloader as api
from gensim.models import Word2Vec
from sklearn.pipeline import Pipeline
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
data = pd.DataFrame({
'doors': [2, np.nan, 2, np.nan, 4],
'topspeed': [100, np.nan, 150, 200, np.nan],
'model': ['Daihatsu', 'Toyota', 'Suzuki', 'BYD','Wuling']
})
doors_imputer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value=0))
])
topspeed_imputer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median'))
])
pipeline = ColumnTransformer(
transformers=[
('doors_imputer', doors_imputer, ['doors']),
('topspeed_imputer', topspeed_imputer, ['topspeed'])
],
remainder='passthrough'
)
transformed = pipeline.fit_transform(data)
transformed_df = pd.DataFrame(transformed, columns=['doors', 'topspeed', 'model'])
2.分箱
分箱是將連續型數值特征離散化的過程,通過將數值范圍劃分為多個區間或“箱”,將原始數值轉換為離散的類別。
常見的分箱方法
- 等寬分箱,將數值區間按等寬度分成若干個區間,適合均勻分布的數據。
- 等頻分箱,將數值按頻數分箱,每個箱中的樣本數大致相同,適用于不均勻分布的數據。
- 自定義分箱,根據業務邏輯或數據特點,自定義分箱的邊界。
應用場景
- 在信用評分等領域,通過分箱處理連續型變量,可以減少數據的噪聲,增加模型的穩健性。
np.random.seed(42)
data = pd.DataFrame({'age' : np.random.randint(0, 100, 100)})
data['category'] = pd.cut(data['age'], [0, 2, 11, 18, 65, 101], labels = ['infants', 'children', 'teenagers', 'adults', 'elders'])
print(data)
print(data['category'].value_counts())
data['category'].value_counts().plot(kind='bar')
3.對數變換
對數變換是一種數值轉換方法,用于處理數據中呈現偏態分布的特征,將其轉換為更接近正態分布的數據形式。
對數變換可以減小大值的影響,壓縮特征的數值范圍。
應用場景
- 處理右偏分布的特征,如收入、價格等數據。
- 適用于減少數據中極大值的影響,避免模型對大值的過度關注。
rskew_data = np.random.exponential(scale=2, size=100)
log_data = np.log(rskew_data)
plt.title('Right Skewed Data')
plt.hist(rskew_data, bins=10)
plt.show()
plt.title('Log Transformed Data')
plt.hist(log_data, bins=20)
plt.show()
4.縮放
縮放是將特征的數值范圍轉換到某一固定區間內的過程。
常見的縮放方法
- 標準化將特征值縮放為均值為 0,標準差為1的標準正態分布。公式為:
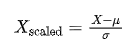
其中,μ是均值,σ是標準差。
- 歸一化
將特征縮放到 [0, 1] 范圍內。
公式為:
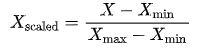
應用場景
- 縮放對于基于距離的算法(如KNN、SVM)和梯度下降優化的算法特別重要,因為特征值的尺度會影響模型的性能。
data = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
scaler = MinMaxScaler()
minmax = scaler.fit_transform(data)
scaler = StandardScaler()
standard = scaler.fit_transform(data)
df = pd.DataFrame({'original':data.flatten(),'Min-Max Scaling':minmax.flatten(),'Standard Scaling':standard.flatten()})
df
5.獨熱編碼
獨熱編碼是一種將類別型變量轉換為二進制特征的編碼方式。
每個類別值被轉換為一個獨立的二進制特征,這些特征值為0或1,表示該樣本是否屬于對應的類別。
舉例
對于類別型特征 “顏色” = {紅,藍,綠},獨熱編碼會將其轉換為三個新特征
- 紅:1, 0, 0
- 藍:0, 1, 0
- 綠:0, 0, 1
應用場景
- 獨熱編碼適用于無序的類別型數據,如國家、城市、產品種類等。
- 適用于不具備自然排序關系的特征。
優缺點
- 優點:可以避免類別之間的錯誤關系,適合沒有順序的分類變量。
- 缺點:當類別數過多時,會導致維度爆炸
data = pd.DataFrame({'models':['toyota','ferrari','byd','lamborghini','honda','tesla'],
'speed':['slow','fast','medium','fast','slow','medium']})
data = pd.concat([data, pd.get_dummies(data['speed'], prefix='speed')],axis=1)
data
6.目標編碼
目標編碼是一種處理類別型變量的編碼方式,通過用該類別與目標變量的統計信息(如均值、概率)來替代類別值。
通常用于高基數的類別變量,避免獨熱編碼導致維度過高的問題。
舉例
假設目標是二分類問題,對于類別型特征“城市”,可以用每個城市對應的目標變量均值來替換原始的類別值。
例如,城市A的目標變量均值為0.7,城市B的均值為0.3,城市C的均值為0.5。
應用場景
- 適用于高基數類別型變量(如用戶ID、產品ID等),特別是在類別與目標變量有顯著關系時。
注意事項
- 為了避免數據泄露(即使用目標值信息),需要對訓練集和測試集分別進行編碼,或者使用交叉驗證技術。
fruits = ['banana','apple','durian','durian','apple','banana']
price = [120,100,110,150,140,160]
data = pd.DataFrame({
'fruit': fruits,
'price': price
})
data['encoded_fruits'] = data.groupby('fruit')['price'].transform('mean')
data
7.主成分分析
PCA 是一種線性降維方法,通過將高維數據投影到一個低維空間,同時盡量保留原始數據的方差信息。
PCA 通過計算數據的協方差矩陣,找到數據的主成分(特征向量),然后選擇前幾個主成分作為新的特征。
步驟
- 標準化數據。
- 計算協方差矩陣。
- 計算協方差矩陣的特征值和特征向量。
- 根據特征值大小選擇前K個特征向量作為主成分。
- 將原始數據投影到新的主成分上。
應用場景
- PCA常用于高維數據集的降維,如圖像、基因數據,目的是減少特征數量,降低計算復雜度,同時保留最重要的信息。
iris_data = load_iris()
features = iris_data.data
targets = iris_data.target
pca = PCA(n_compnotallow=2)
pca_features = pca.fit_transform(features)
for point in set(targets):
plt.scatter(pca_features[targets == point, 0], pca_features[targets == point,1], label=iris_data.target_names[point])
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.title('PCA on Iris Dataset')
plt.legend()
plt.show()
8.特征聚合
特征聚合是一種通過聚合現有特征來生成新特征的技術。
聚合可以通過多種方式實現,如計算平均值、總和、最大值、最小值等。
特征聚合特別適合處理時間序列數據或分組數據。
應用場景
- 在時間序列數據中,可以對某一特征在多個時間窗口上計算統計量,如移動平均、累計總和等。
- 在分組數據中,可以對每個用戶的購買記錄進行聚合,生成新的特征(如總購買金額、平均購買頻率等)。
quarter = ['Q1','Q2','Q3','Q4']
car_sales = [10000,9850,13000,20000]
motorbike_sales = [14000,18000,9000,11000]
sparepart_sales = [5000, 7000,3000, 10000]
data = pd.DataFrame({'car':car_sales,
'motorbike':motorbike_sales,
'sparepart':sparepart_sales}, index=quarter)
data['avg_sales'] = data[['car','motorbike','sparepart']].mean(axis=1).astype(int)
data['total_sales'] = data[['car','motorbike','sparepart']].sum(axis=1).astype(int)
data
9.TF-IDF
TF-IDF 是一種衡量文本中詞匯重要性的特征工程技術,廣泛應用于自然語言處理(NLP)任務。
它通過計算詞頻(TF)和逆文檔頻率(IDF)來評估某個詞在文本中的重要性:
- 詞頻(TF),某個詞在文檔中出現的頻率。
- 逆文檔頻率(IDF),表示詞在所有文檔中出現的稀有程度,常見詞會被削弱。
TF-IDF 公式:
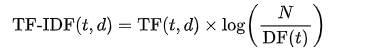
其中 N 是文檔總數, 是詞 t 出現在多少個文檔中的次數。
texts = ["I eat rice with eggs.",
"I also love to eat fried rice. Rice is the most delicious food in the world"]
vectorizer = TfidfVectorizer()
tfidfmatrix = vectorizer.fit_transform(texts)
features = vectorizer.get_feature_names_out()
data = pd.DataFrame(tfidfmatrix.toarray(), columns=features)
print("TF-IDF matrix")
data
10.文本嵌入
文本嵌入是將文本數據轉化為數值向量的技術,目的是將語義信息保留在低維向量空間中,使其能夠被機器學習模型處理。
常見的文本嵌入方法有:
- Word2Vec,將詞映射為向量,類似語義的詞會在向量空間中更接近。
- GloVe,基于共現矩陣生成詞向量,保持詞語之間的全局關系。
- BERT,上下文感知的詞向量模型,能夠捕捉詞在不同上下文中的含義。
文本嵌入可以捕捉文本中的語義信息,使模型能夠理解文本間的關系。
corpus = api.load('text8')
model = Word2Vec(corpus)
dog = model.wv['dog']
print("Embedding vector for 'dog':\n", dog)






























