MSSQL · 特性分析 · 列存儲技術做實時分析
數據分析指導商業行為的價值越來越高,使得用戶對數據實時分析的要求變得越來越高。使用傳統RDBMS數據分析架構,遇到了***的挑戰,高延遲、數據處理流程復雜和成本過高。這篇文章討論如何利用SQL Server 2016列存儲技術做實時數據分析,解決傳統分析方法的痛點。
傳統RDBMS數據分析
在過去很長一段時間,企業均選擇傳統的關系型數據庫做OLAP和Data Warehouse工作。這一節討論傳統RDBMS數據分析的結構和面臨的挑戰。
傳統RDBMS分析架構
傳統關系型數據庫做數據分析的架構,按照功能模塊可以劃分為三個部分:
OLTP模塊:OLTP的全稱是Online Transaction Processing,它是數據產生的源頭,對數據的完整性和一致性要求很高;對數據庫的反應時間(RT: Response Time)非常敏感;具有高并發,多事務,高響應等特點。
ETL模塊:ETL的全稱是Extract Transform Load。他是做數據清洗、轉化和加載工作的。可以將ETL理解為數據從OLTP到Data Warehouse的“搬運工”。ETL***的特定是具有延時性,為了***限度減小對OLTP的影響,一般會設計成按小時,按天或者按周來周期性運作。
OLAP模塊:OLAP的全稱是Online Analytic Processing,它是基于數據倉庫(Data Warehouse)做數據分析和報表呈現的終端產品。數據倉庫的特點是:數據形態固定,幾乎或者很少發生數據變更,統計查詢分析讀取數據量大。
傳統的RDBMS分析模型圖,如下圖展示(圖片直接截取自微軟的培訓材料):
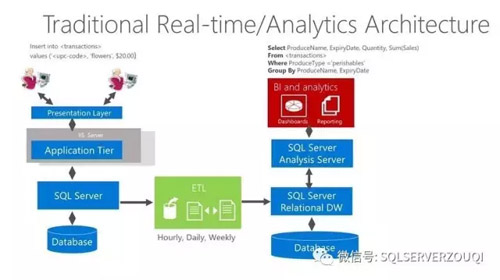
從這個圖,我們可以非常清晰的看到傳統RDBMS分析模型的三個大的部分:在圖的最左邊是OLTP業務場景,負責采集和產生數據;圖的中部是ETL任務,負責“搬運”數據;圖的右邊是OLAP業務場景,負責分析數據,然后將分析結果交給BI報表展示給最終用戶。企業使用這個傳統的架構長達數年,遇到了不少的挑戰和困難。
面臨的挑戰
商場如戰場,戰機隨息萬變,數據分析結果指導商業行為的價值越來越高,使得數據分析結果變得越來越重要,用戶對數據實時分析的要求變得越來越高。使用傳統RDBMS分析架構,遇到了***的挑戰,主要的痛點包括:
- 數據延遲大
- 數據處理流程冗長復雜
- 成本過高
數據延遲大:為了減少對OLTP模塊的影響,ETL任務往往會選擇在業務低峰期周期性運作,比如凌晨。這就會導致OLAP分析的數據源Data Warehouse相對于OLTP有至少一天的時間差異。這個時間差異對于某些實時性要求很高的業務來說,是無法接受的。比如:銀行卡盜刷的檢查服務,是需要做到秒級別通知持卡人的。試想下,如果你的銀行卡被盜刷,一天以后才收到銀行發過來的短信提醒,會是多么糟糕的體驗。
數據處理流程冗長復雜:數據是通過ETL任務來抽取、清洗和加載到Data Warehouse中的。為了保證數據分析結果的正確性,ETL還必須要解決一系列的問題。比如:OLTP變更數據的捕獲,并同步到Data Warehouse;周期性的進行數據全量和增量更新來確保OLTP和Data Warehouse中數據的一致性。整個數據流冗長,實現邏輯異常復雜。
成本過高:為了實現傳統的RDBMS數據分析功能,必須新增Data Warehouse角色來保存所有的OLTP數據冗余,專門提供分析服務功能。這勢必會加大了硬件、軟件和維護成本投入;隨之還會到來ETL任務做數據抓取、清洗、轉換和加載的開發成本和時間成本投入。
那么,SQL Server有沒有一種技術既能解決以上所有痛點的方法,又能實現數據實時分析呢?當然有,那就是SQL Server 2016列存儲技術。
SQL Server 2016列存儲技術做實時分析
為了解決OLAP場景的查詢分析,微軟從SQL Server 2012開始引入列存儲技術,大大提高了OLAP查詢的性能;SQL Server 2014解決了列存儲表只讀的問題,使用場景大大拓寬;而SQL Server 2016的列存儲技術徹底解決了實時數據分析的業務場景。用戶只需要做非常小規模的修改,便可以可以非常平滑的使用SQL Server 2016的列存儲技術來解決實時數據分析的業務場景。這一節討論以下幾個方面:
SQL Server 2016數據分析架構
- Disk-based Tables with Nonclustered Columnstore Index
- Memory-based Tables with Columnstore Index
- Minimizing impacts of OLTP
SQL Server 2016數據分析架構
SQL Server 2016數據分析架構相對于傳統的RDBMS數據分析架構有了非常大的改進,變得更加簡單。具體體現在OLAP直接接入OLTP數據源,如此就無需Data Warehouse角色和ETL任務這個“搬運工”了。
OLAP直接接入OLTP數據源:讓OLAP報表數據源直接接入OLTP的數據源頭上。SQL Server會自動選擇合適的列存儲索引來提高數據分析查詢的性能,實現實時數據分析的場景。
不再需要ETL任務:由于OLAP數據源直接接入OLTP的數據,沒有了Data Warehouse角色,所以不再需要ETL任務,從而大大簡化了數據處理流程中的各環節,沒有了相應的開發維護和時間成本。
SQL Server 2016實時分析架構圖,展示如下(圖片來自微軟培訓教程):
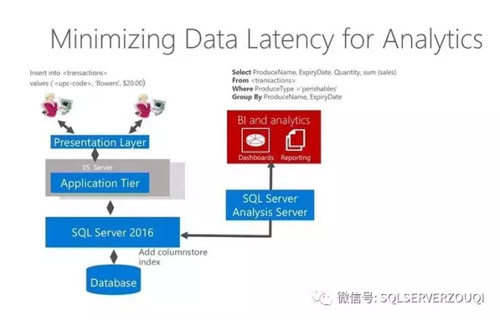
SQL Server 2016之所以能夠實現如此簡化的實時分析,底氣是來源于SQL Server 2016的列存儲技術,我們可以建立基于磁盤存儲或者基于內存存儲的列存儲表來進行實時數據分析。
Disk-based Tables with Nonclustered Columnstore Index
使用SQL Server 2016列存儲索引實現實時分析的***種方法是為表建立非聚集列存儲索引。在SQL Server 2012版本中,僅支持非聚集列存儲索引,并且表會成為只讀,而無法更新;在SQL Server 2014版本中,支持聚集列存儲索引表,且數據可更新;但是非聚集列存儲索引表還是只讀;而在SQL Server 2016中,完全支持非聚集列存儲索引和聚集列存儲索引,并且表可更新。所以,在SQL Server 2016版本中,我們完全可以建立非聚集列存儲索引來實現OLAP的查詢場景。創建方法示例如下:
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED (OrderID)
- ) ;
- GO
- --Create the columnstore index with a filtered condition
- CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_SalesOrder
- ON dbo.SalesOrder (OrderID, AutoID, UserID, OrderQty, Price, OrderDate, OrderStatus)
- ;
- GO
在這個實例中,我們創建了SalesOrder表,并且為該表創建了非聚集列存儲索引,當進行OLAP查詢分析的時候,SQL Server會直接從該列存儲索引中讀取數據。
Memory-based Tables with Columnstore Index
SQL Server 2014版本引入了In-Memory OLTP,又或者叫著Hekaton,中文稱之為內存優化表,內存優化表完全是Lock Free、Latch Free的,可以***限度的增加并發和提高響應時間。而在SQL Server 2016中,如果你的服務器內存足夠大的話,我們完全可以建立基于內存優化表的列存儲索引,這樣的表數據會按列存儲在內存中,充分利用兩者的優勢,***程度的提高查詢查詢效率,降低數據庫響應時間。創建方法實例如下:
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED HASH (OrderID) WITH (BUCKET_COUNT = 10000000)
- ) WITH(MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA) ;
- GO
- ALTER TABLE dbo.SalesOrder
- ADD INDEX CCSI_SalesOrder CLUSTERED COLUMNSTORE
- ;
- GO
在這個實例中,我們創建了基于內存的優化表SalesOrder,持久化方案為表結構和數據;然后在這個內存表上建立聚集列存儲索引。當OLAP查詢分析執行的時候,SQL Server可以直接從基于內存的列存儲索引中獲取數據,大大提高查詢分析的能力。
Minimizing impacts of OLTP
考慮到OLTP數據源的高并發,低延遲要求的特性,在某些非常高并發事務場景中,我們可以采用以下方法***限度減少對OLTP的影響:
- Filtered NCCI + Clustered B-Tree Index
- Compress Delay
- Offloading OLAP to AlwaysOn Readable Secondary
- Filtered NCCI + Clustered B-Tree Index
帶過濾條件的索引在SQL Server產品中并不是什么全新的概念,在SQL Server 2008及以后的產品版本中,均支持創建過濾索引,這項技術允許用戶創建存在過濾條件的索引,以加速特定條件的查詢語句使用過濾索引。而在SQL Server 2016中支持存在過濾條件的列存儲索引,我們可以使用這項技術來區分數據的冷熱程度(數據冷熱程度是指數據的修改頻率;冷數據是指幾乎或者很少被修改的數據;熱數據是指經常會被修改的數據。比如在訂單場景中,訂單從生成狀態到客戶收到貨物之間的狀態,會被經常更新,屬于熱數據;而客人一旦收到貨物,訂單信息幾乎不會被修改了,就屬于冷數據)。利用過濾列存儲索引來區分冷熱數據的技術,是使用聚集B-Tree索引來存放熱數據,使用過濾非聚集列存儲索引來存放冷數據,這樣SQL Server 2016的優化器可以非常智能的從非聚集列存儲索引中獲取冷數據,從聚集B-Tree索引中獲取熱數據,這樣使得OLAP操作與OLTP事務操作邏輯隔離開來,最終OLAP***限度的減少對OLTP的影響。
下圖直觀的表示了Filtered NCCI + Clustered B-Tree Index的結構圖(圖片來自微軟培訓教程):
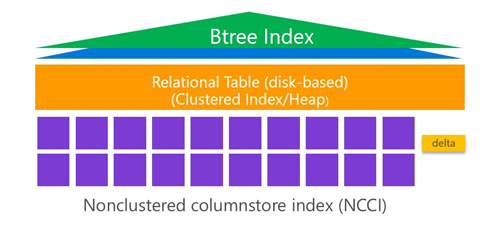
實現方法參見以下代碼:
- -- create demo table SalesOrder
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED (OrderID)
- ) ;
- GO
- /*
- — OrderStatus Description
- — 0 => ‘Placed’
- — 1 => ‘Closed’
- — 2 => ‘Paid’
- — 3 => ‘Pending’
- — 4 => ‘Shipped’
- — 5 => ‘Received’
- */
- CREATE CLUSTERED INDEX CI_SalesOrder
- ON dbo.SalesOrder(OrderStatus)
- ;
- GO
- --Create the columnstore index with a filtered condition
- CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_SalesOrder
- ON dbo.SalesOrder (AutoID, Price, OrderQty, orderstatus)
- WHERE orderstatus = 5
- ;
- GO
在這個實例中,我們創建了SalesOrder表,并在OrderStatus字段上建立了Clustered B-Tree結構的索引CI_SalesOrder,然后再建立了帶過濾條件的非聚集列存儲索引NCCI_SalesOrder。當客人還未收到貨物的訂單,會處于前面五中狀態,屬于需要經常更新的熱數據,SQL Server查詢會根據Clustered B-Tree索引CI_SalesOrder來查詢數據;客人已經收貨的訂單,處于第六種狀態,屬于冷數據,SQL Server查詢冷數據會直接從非聚集列存儲索引中獲取數據。從而***限度減少對OLTP影響的同時,提高查詢效率。
Compress Delay
如果按照業務邏輯層面很難明確劃分出數據的冷熱程度,也就是說很難從過濾條件來邏輯區分數據的冷熱。這種情況下,我們可以使用延遲壓縮(Compress Delay)技術從時間層面來區分冷熱數據。比如:我們定義超過60分鐘的數據為冷數據,60分鐘以內的數據為熱數據,那么我們可以在創建列存儲索引的時候添加WITH選項COMPRESSION_DELAY = 60 Minutes。當數據產生超過60分鐘以后,數據會被壓縮存放到列存儲索引中(冷數據),60分鐘以內的數據會駐留在Delta Store的B-Tree結構中,這種延遲壓縮的技術不但能夠達到隔離OLAP對OLTP作用,還能***限度的減少列存儲索引碎片的產生。
實現方法參見以下例子:
- -- create demo table SalesOrder
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED (OrderID)
- ) ;
- GO
- --Create the columnstore index with a filtered condition
- CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_SalesOrder
- ON dbo.SalesOrder (AutoID, Price, OrderQty, orderstatus)
- WITH(COMPRESSION_DELAY = 60 MINUTES)
- ;
- GO
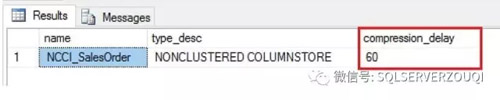
- SELECT name
- ,type_desc
- ,compression_delay
- FROM sys.indexes
- WHERE object_id = object_id('SalesOrder')
- AND name = 'NCCI_SalesOrder'
- ;
檢查索引信息截圖如下:
Offloading OLAP to AlwaysOn Readable Secondary
另外一種減少OLAP對OLTP影響的方法是利用AlwaysOn只讀副本,這種情況,可以將OLAP數據源從OLTP剝離出來,接入到AlwaysOn的只讀副本上。AlwaysOn的主副本負責事務處理,只讀副本可以作為OLAP的數據分析源,這樣實現了OLAP與OLTP的物理隔離,將影響減到***。架構圖如下所示(圖片來自微軟培訓教程):
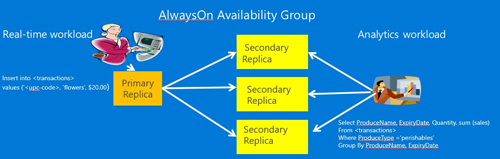
一個實際例子
在訂單系統場景中,用戶收到貨物過程,每個訂單會經歷6中狀態,假設為Placed、Canceled、Paid、Pending、Shipped和Received。在前面5中狀態的訂單,會被經常修改,比如:打包訂單,出庫,更新快遞信息等,這部分經常被修改的數據稱為熱數據;而訂單一旦被客人接受以后,訂單數據就幾乎不會被修改,這部分數據稱為冷數據。這個例子就是使用SQL Server 2016 Filtered NCCI + Clustered B-Tree索引的方式來邏輯劃分出數據的冷熱程度,SQL Server在查詢過程中,會從非聚集列存儲索引中取冷數據,從B-Tree索引中取熱數據,***限度提高OLAP查詢效率,減少對OLTP的影響。
具體建表代碼實現如下:
- -- create demo table SalesOrder
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED (OrderID)
- ) ;
- GO
- /*
- — OrderStatus Description
- — 0 => ‘Placed’
- — 1 => ‘Closed’
- — 2 => ‘Paid’
- — 3 => ‘Pending’
- — 4 => ‘Shipped’
- — 5 => ‘Received’
- */
- CREATE CLUSTERED INDEX CI_SalesOrder
- ON dbo.SalesOrder(OrderStatus)
- ;
- GO
- --Create the columnstore index with a filtered condition
- CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_SalesOrder
- ON dbo.SalesOrder (AutoID, Price, OrderQty, orderstatus)
- WHERE orderstatus = 5
- ;
- GO
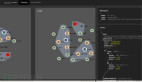
為了能夠直觀的看到利用SQL Server 2016列存儲索引實現實時分析的效果,我虛擬了一個網絡汽車銷售訂單系統,使用NodeJs + SQL Server 2016 Columnstore Index + Socket.IO來實現實時訂單銷量和銷售收入的分析頁面。
總結
這篇文章講解利用SQL Server 2016列存儲索引技術實現數據實時分析的兩種方法,以解決傳統RDBMS數據分析的高延遲、高成本的痛點。***種方法是Hekaton + Clustered Columnstore Index;第二種方法是Filtered Nonclustered Columnstore Index + Clustered B-Tree。本文并以此理論為基礎,展示了一個網絡汽車在線銷售系統的實時訂單分析頁面。