PyFlink場景案例 - PyFlink實現CDN日志實時分析
CDN 日志實時分析綜述
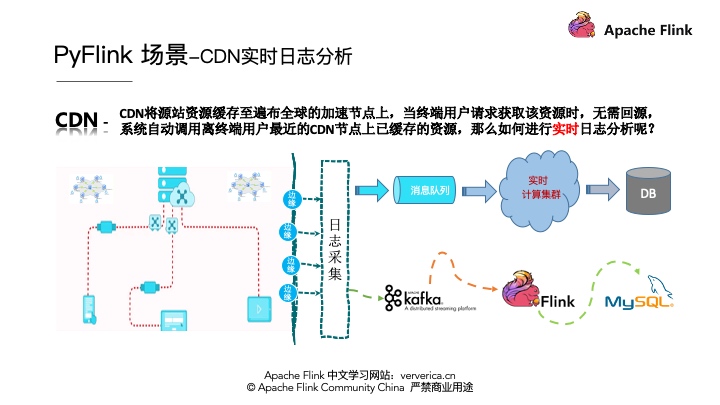
CDN將源站資源緩存至遍布全球的加速節點上,當終端用戶請求獲取該資源時,無需回源,系統自動調用離終端用戶最近的CDN節點上已緩存的資源,那么如何進行實時日志分析呢?
架構
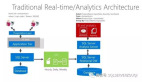
CDN日志的解析一般有一個通用的架構模式,就是首先要將各個邊緣節點的日志數據進行采集,一般會采集到消息隊列,然后將消息隊列和實時計算集群進行集成進行實時的日志分析,最后將分析的結果寫到存儲系統里面。那么我今天的案例將架構實例化,消息隊列采用Kafka,實時計算采用Flink,最終將數據存儲到MySql中。如下圖所示:
需求說明
阿里云實際的CDN日志數據結構如下(可能會不斷豐富字段信息):

為了介紹方便,我們將實際的統計需求進行簡化,示例將從CDN訪問日志中,根據IP解析出其所屬的地區,統計指標:
- 按地區統計資源訪問量
- 按地區統計資源下載總量
- 按地區統計資源平均下載速度
CDN實時日志分析UDF定義
這里我們需要定義一個 ip_to_province()的UDF,輸入是ip地址,輸出是地區名字字符串。UDF的輸入類型是一個字符串,輸出類型也是一個字符串。同時我們會用到地理區域查詢服務
(http://whois.pconline.com.cn/ipJson.jsp?ip=27.184.139.25),大家在自己的生產環境要替換為可靠的地域查詢服務。
- import re
- import json
- from pyflink.table import DataTypes
- from pyflink.table.udf import udf
- from urllib.parse import quote_plus
- from urllib.request import urlopen
- @udf(input_types=[DataTypes.STRING()], result_type=DataTypes.STRING())
- def ip_to_province(ip):
- """
- format:
- {
- 'ip': '27.184.139.25',
- 'pro': '河北省',
- 'proCode': '130000',
- 'city': '石家莊市',
- 'cityCode': '130100',
- 'region': '靈壽縣',
- 'regionCode': '130126',
- 'addr': '河北省石家莊市靈壽縣 電信',
- 'regionNames': '',
- 'err': ''
- }
- """
- try:
- urlobj = urlopen( \
- 'http://whois.pconline.com.cn/ipJson.jsp?ip=%s' % quote_plus(ip))
- data = str(urlobj.read(), "gbk")
- pos = re.search("{[^{}]+\}", data).span()
- geo_data = json.loads(data[pos[0]:pos[1]])
- if geo_data['pro']:
- return geo_data['pro']
- else:
- return geo_data['err']
- except:
- return "UnKnow"
數據讀取和結果寫入定義
按照通用的作業結構,需要定義Source connector來讀取Kafka數據,定義Sink connector來將計算結果存儲到MySQL。最后是編寫統計邏輯。在這特別說明一下,在PyFlink中也支持SQL DDL的編寫,我們用一個簡單的DDL描述,就完成了Source Connector的開發。其中connector.type填寫kafka。SinkConnector也一樣,用一行DDL描述即可,其中connector.type填寫jdbc。
1. Kafka 數據源讀取DDL定義
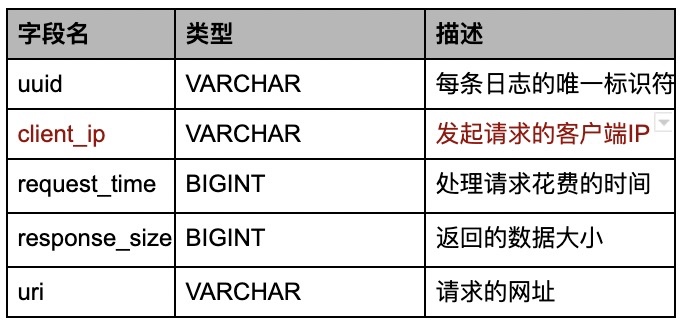
數據統計需求我們只選取核心的字段,比如:uuid,表示唯一的日志標示,client_ip表示訪問來源,request_time表示資源下載耗時,response_size表示資源數據大小。Kafka數據字段進行簡化如下:
DDL定義如下:
- kafka_source_ddl = """
- CREATE TABLE cdn_access_log (
- uuid VARCHAR,
- client_ip VARCHAR,
- request_time BIGINT,
- response_size BIGINT,
- uri VARCHAR
- ) WITH (
- 'connector.type' = 'kafka',
- 'connector.version' = 'universal',
- 'connector.topic' = 'access_log',
- 'connector.properties.zookeeper.connect' = 'localhost:2181',
- 'connector.properties.bootstrap.servers' = 'localhost:9092',
- 'format.type' = 'csv',
- 'format.ignore-parse-errors' = 'true'
- )
- """
2. MySql 數據寫入DDL定義
其中我們發現我們需求是按地區分組,但是原始日志里面并沒有地區的字段信息,所以我們需要定義一個Python UDF 更具 client_ip 來查詢對應的地區。所以我們對應的MySqL統計結果表如下:

DDL定義如下:
- mysql_sink_ddl = """
- CREATE TABLE cdn_access_statistic (
- province VARCHAR,
- access_count BIGINT,
- total_download BIGINT,
- download_speed DOUBLE
- ) WITH (
- 'connector.type' = 'jdbc',
- 'connector.url' = 'jdbc:mysql://localhost:3306/Flink',
- 'connector.table' = 'access_statistic',
- 'connector.username' = 'root',
- 'connector.password' = '123456',
- 'connector.write.flush.interval' = '1s'
- )
- """
核心統計邏輯
我們首先要將client_ip轉換為地區名字,然后在做數據統計,如下核心統計邏輯:
- # 核心的統計邏輯
- t_env.from_path("cdn_access_log")\
- .select("uuid, "
- "ip_to_province(client_ip) as province, " # IP 轉換為地區名稱
- "response_size, request_time")\
- .group_by("province")\
- .select( # 計算訪問量
- "province, count(uuid) as access_count, "
- # 計算下載總量
- "sum(response_size) as total_download, "
- # 計算下載速度
- "sum(response_size) * 1.0 / sum(request_time) as download_speed") \
- .insert_into("cdn_access_statistic")
完整的作業代碼
我們整體看一遍完整代碼結構,首先是核心依賴的導入,然后是我們需要創建一個ENV,并設置采用的planner(目前Flink支持Flink和blink兩套planner)建議大家采用 blink planner。 接下來將我們剛才描述的kafka和mysql的ddl進行表的注冊。再將Python UDF進行注冊,這里特別提醒一點,UDF所依賴的其他文件也可以在API里面進行制定,這樣在job提交時候會一起提交到集群。然后是核心的統計邏輯,最后調用executre提交作業。這樣一個實際的CDN日志實時分析的作業就開發完成了。具體代碼如下:
- import os
- from pyFlink.datastream import StreamExecutionEnvironment
- from pyflink.table import StreamTableEnvironment, EnvironmentSettings
- from enjoyment.cdn.cdn_udf import ip_to_province
- from enjoyment.cdn.cdn_connector_ddl import kafka_source_ddl, mysql_sink_ddl
- # 創建Table Environment, 并選擇使用的Planner
- env = StreamExecutionEnvironment.get_execution_environment()
- t_env = StreamTableEnvironment.create(
- env,
- environment_settings=EnvironmentSettings.new_instance().use_blink_planner().build())
- # 創建Kafka數據源表
- t_env.sql_update(kafka_source_ddl)
- # 創建MySql結果表
- t_env.sql_update(mysql_sink_ddl)
- # 注冊IP轉換地區名稱的UDF
- t_env.register_function("ip_to_province", ip_to_province)
- # 添加依賴的Python文件
- t_env.add_Python_file(
- os.path.dirname(os.path.abspath(__file__)) + "/enjoyment/cdn/cdn_udf.py")
- t_env.add_Python_file(os.path.dirname(
- os.path.abspath(__file__)) + "/enjoyment/cdn/cdn_connector_ddl.py")
- # 核心的統計邏輯
- t_env.from_path("cdn_access_log")\
- .select("uuid, "
- "ip_to_province(client_ip) as province, " # IP 轉換為地區名稱
- "response_size, request_time")\
- .group_by("province")\
- .select( # 計算訪問量
- "province, count(uuid) as access_count, "
- # 計算下載總量
- "sum(response_size) as total_download, "
- # 計算下載速度
- "sum(response_size) * 1.0 / sum(request_time) as download_speed") \
- .insert_into("cdn_access_statistic")
- # 執行作業
- t_env.execute("pyFlink_parse_cdn_log")
環境搭建(MacOS)
1. 安裝MySQL
- $ brew install mysql
- Updating Homebrew...
- ==> Auto-updated Homebrew!
- ...
- ...
- MySQL is configured to only allow connections from localhost by default
- To connect run:
- mysql -uroot
- To have launchd start mysql now and restart at login:
- brew services start mysql
- Or, if you don't want/need a background service you can just run:
- mysql.server start
如果沒有安裝brew,執行以下指令安裝:
- $ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
安裝完成后,執行安全配置,將root用戶的密碼設置為JxXX&&l2j2#:
- $ mysql_secure_installation
啟動mysql服務:
- $ brew services start mysql
- ==> Tapping homebrew/services
- Cloning into '/usr/local/Homebrew/Library/Taps/homebrew/homebrew-services'...
- ...
- ...
- ==> Successfully started `mysql` (label: homebrew.mxcl.mysql)
登錄mysql并創建flink數據庫和cdn_access_statistic表,并確認開放端口號為默認的3306:
- $ mysql -uroot -p
- Enter password: JxXX&&l2j2#
- mysql> use flink;
- Database changed
- mysql> CREATE TABLE cdn_access_statistic(
- -> province VARCHAR(255) PRIMARY KEY,
- -> access_count BIGINT,
- -> total_download BIGINT,
- -> download_speed DOUBLE
- -> ) ENGINE=INNODB CHARSET=utf8mb4;
- Query OK, 0 rows affected (0.01 sec)
- exit
這樣mysql的環境就準備好了。
2. 安裝Kafka
在Mac系統安裝Kafka也非常方便,如下:
- brew install kafka
- Updating Homebrew...
- ==> Installing dependencies for kafka: zookeeper
- ...
- ...
- ==> Summary
- /usr/local/Cellar/zookeeper/3.5.7: 394 files, 11.3MB
- ==> Installing kafka
- ...
- ...
- ==> kafka
- To have launchd start kafka now and restart at login:
- brew services start kafka
- Or, if you don't want/need a background service you can just run:
- zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties & kafka-server-start /usr/local/etc/kafka/server.properties
安裝完成后執行以下指令啟動zookeeper和kafka:
- $ cd /usr/local/opt/kafka/libexec/bin/
- $ ./zookeeper-server-start.sh ../config/zookeeper.properties &
- $ (回車)
- $ ./kafka-server-start.sh ../config/server.properties &
- $ (回車)
然后在kafka中創建名為cdn_access_log的topic:
- $ kafka-topics --create --replication-factor 1 --partitions 1 --topic cdn_access_log --zookeeper localhost:2181
- ...
- Created topic cdn_access_log.
這樣kafka的環境也準備好了.
3. 安裝PyFlink
確保使用Python3.5+的版本,檢驗如下:
- $ python --version
- Python 3.7.6
說過pip install安裝PyFlink
- python -m pip install apache-flink==1.10.0
- ...
- ...
- Successfully installed apache-beam-2.15.0 dill-0.2.9 pyarrow-0.14.1
檢查我們是否成功安裝了PyFlink和依賴的Beam,如下:
- $ python -m pip list |grep apache-
- apache-beam 2.15.0
- apache-flink 1.10.0
如上顯示說明已經完成安裝。
4. Copy使用的Connector的JAR包
Flink默認是沒有打包connector的,所以我們需要下載各個connector所需的jar包并放入PyFlink的lib目錄。首先拿到PyFlink的lib目錄的路徑:
- $ PYFLINK_LIB=`python -c "import pyflink;import os;print(os.path.dirname(os.path.abspath(pyflink.__file__))+'/lib')"`
- $ echo $PYFLINK_LIB
- /usr/local/lib/python3.7/site-packages/pyflink/lib
然后想需要的jar包下載到lib目錄中去:
- $ cd $PYFLINK_LIB
- $ curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.11/1.10.0/flink-sql-connector-kafka_2.11-1.10.0.jar
- $ curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-jdbc_2.11/1.10.0/flink-jdbc_2.11-1.10.0.jar
- $ curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-csv/1.10.0/flink-csv-1.10.0-sql-jar.jar
- $ curl -O https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.19/mysql-connector-java-8.0.19.jar
最終lib的JARs如下:
- $ ls -la
- total 310448
- drwxr-xr-x 12 jincheng.sunjc admin 384 3 27 15:48 .
- drwxr-xr-x 28 jincheng.sunjc admin 896 3 24 11:44 ..
- -rw-r--r-- 1 jincheng.sunjc admin 36695 3 27 15:48 flink-csv-1.10.0-sql-jar.jar
- -rw-r--r-- 1 jincheng.sunjc admin 110055308 2 27 13:33 flink-dist_2.11-1.10.0.jar
- -rw-r--r-- 1 jincheng.sunjc admin 89695 3 27 15:48 flink-jdbc_2.11-1.10.0.jar
- -rw-r--r-- 1 jincheng.sunjc admin 2885638 3 27 15:49 flink-sql-connector-kafka_2.11-1.10.0.jar
- -rw-r--r-- 1 jincheng.sunjc admin 22520058 2 27 13:33 flink-table-blink_2.11-1.10.0.jar
- -rw-r--r-- 1 jincheng.sunjc admin 19301237 2 27 13:33 flink-table_2.11-1.10.0.jar
- -rw-r--r-- 1 jincheng.sunjc admin 489884 2 27 13:33 log4j-1.2.17.jar
- -rw-r--r-- 1 jincheng.sunjc admin 2356711 3 27 15:48 mysql-connector-java-8.0.19.jar
- -rw-r--r-- 1 jincheng.sunjc admin 20275 12 5 17:01 pyflink-demo-connector-0.1.jar
- -rw-r--r-- 1 jincheng.sunjc admin 9931 2 27 13:33 slf4j-log4j12-1.7.15.jar
這樣所有的環境就準備好了。
本地運行作業
- 啟動本地集群:
- $PYFLINK_LIB/../bin/start-cluster.sh local
啟動成功后可以打開web界面(默認8081端口,我更改為4000)
- 提交作業
示例涉及到如下三個py文件:
我們在作業文件所在目錄進行執行:
- $ $PYFLINK_LIB/../bin/flink run -m localhost:4000 -py cdn_demo.py
- Job has been submitted with JobID e71de2db44fd6cfb9bae93bd04ee2ec9
查看控制臺如下:
目前我們已經成功的將作業啟動起來了,接下來我們向Kafka里面進行數據的寫入。
Mock 數據
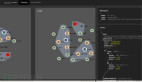
我們對CDN數據進行Mock,并進行統計可視化,工具代碼請下載。
進行源碼編譯
- $ python setup.py sdist
- $ sudo python -m pip install dist/*
運行工具
- $ start_dashboard.py
- --------------------------------------environment config--------------------------------------
- Target kafka port: localhost:9092
- Target kafka topic: cdn_access_log
- Target mysql://localhost:3306/flink
- Target mysql table: cdn_access_statistic
- Listen at: http://localhost:64731
- ----------------------------------------------------------------------------------------------
- To change above environment config, edit this file: /usr/local/bin/start_dashboard.py
打開可視化界面: (根據命令行提示的 Listen at:后面的地址)

小結
本篇是場景案例系列,開篇分享了老子教導我們要學會放空自己,空杯才能注水。全篇圍繞阿里云CDN日志實時分析需求進行展開,描述了任何利用PyFlink解決實際業務問題。最后又為大家提供了示例的數據的Mock工具和可視化統計頁面,希望對大家有所幫助。
作者介紹
本人孫金城,淘寶花名“金竹”,阿里巴巴高級技術專家。2011年加入阿里,在2016年開始ASF社區貢獻,目前是 ASF Member, PMC member of @ApacheFlink and a Committer for @ApacheFlink, @ApacheBeam, @ApacheIoTDB。
【本文為51CTO專欄作者“金竹”原創稿件,轉載請聯系原作者】