使用Apache Spark構建實時分析Dashboard

問題描述
電子商務門戶(http://www.aaaa.com)希望構建一個實時分析儀表盤,對每分鐘發貨的訂單數量做到可視化,從而優化物流的效率。
解決方案
解決方案之前,先快速看看我們將使用的工具:
Apache Spark – 一個通用的大規模數據快速處理引擎。Spark的批處理速度比Hadoop MapReduce快近10倍,而內存中的數據分析速度則快近100倍。
Python – Python是一種廣泛使用的高級,通用,解釋,動態編程語言。
Kafka – 一個高吞吐量,分布式消息發布訂閱系統。
Node.js – 基于事件驅動的I/O服務器端JavaScript環境,運行在V8引擎上。
Socket.io – Socket.IO是一個構建實時Web應用程序的JavaScript庫。它支持Web客戶端和服務器之間的實時、雙向通信。
Highcharts – 網頁上交互式JavaScript圖表。
CloudxLab – 提供一個真實的基于云的環境,用于練習和學習各種工具。
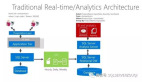
如何構建數據Pipeline?
下面是數據Pipeline高層架構圖
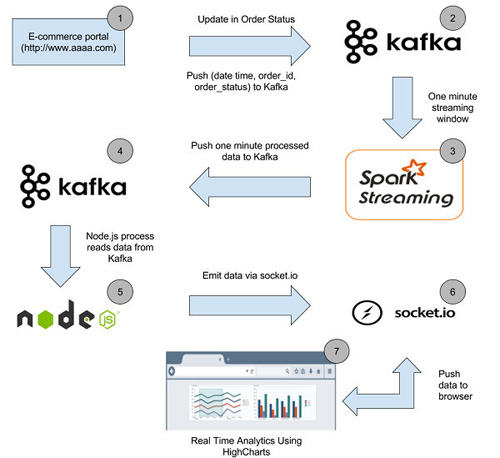
數據Pipeline
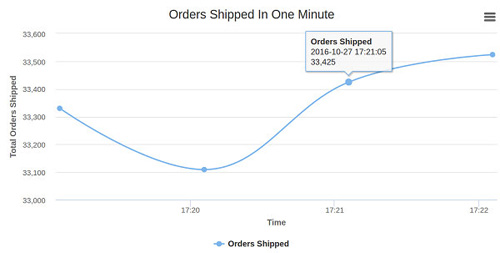
實時分析Dashboard
讓我們從數據Pipeline中的每個階段的描述開始,并完成解決方案的構建。
階段1
當客戶購買系統中的物品或訂單管理系統中的訂單狀態變化時,相應的訂單ID以及訂單狀態和時間將被推送到相應的Kafka主題中。
數據集
由于沒有真實的在線電子商務門戶網站,我們準備用CSV文件的數據集來模擬。讓我們看看數據集:

數據集包含三列分別是:“DateTime”、“OrderId”和“Status”。數據集中的每一行表示特定時間時訂單的狀態。這里我們用“xxxxx-xxx”代表訂單ID。我們只對每分鐘發貨的訂單數感興趣,所以不需要實際的訂單ID。
可以從CloudxLab GitHub倉庫克隆完整的解決方案的源代碼和數據集。
數據集位于項目的spark-streaming/data/order_data文件夾中。
推送數據集到Kafka
shell腳本將從這些CSV文件中分別獲取每一行并推送到Kafka。推送完一個CSV文件到Kafka之后,需要等待1分鐘再推送下一個CSV文件,這樣可以模擬實時電子商務門戶環境,這個環境中的訂單狀態是以不同的時間間隔更新的。在現實世界的情況下,當訂單狀態改變時,相應的訂單詳細信息會被推送到Kafka。
運行我們的shell腳本將數據推送到Kafka主題中。登錄到CloudxLab Web控制臺并運行以下命令。

階段2
在第1階段后,Kafka“order-data”主題中的每個消息都將如下所示
![]()
階段3
Spark streaming代碼將在60秒的時間窗口中從“order-data”的Kafka主題獲取數據并處理,這樣就能在該60秒時間窗口中為每種狀態的訂單計數。處理后,每種狀態訂單的總計數被推送到“order-one-min-data”的Kafka主題中。
請在Web控制臺中運行這些Spark streaming代碼

階段4
在這個階段,Kafka主題“order-one-min-data”中的每個消息都將類似于以下JSON字符串

階段5
運行Node.js server
現在我們將運行一個node.js服務器來使用“order-one-min-data”Kafka主題的消息,并將其推送到Web瀏覽器,這樣就可以在Web瀏覽器中顯示出每分鐘發貨的訂單數量。
請在Web控制臺中運行以下命令以啟動node.js服務器

現在node服務器將運行在端口3001上。如果在啟動node服務器時出現“EADDRINUSE”錯誤,請編輯index.js文件并將端口依次更改為3002...3003...3004等。請使用3001-3010范圍內的任意可用端口來運行node服務器。
用瀏覽器訪問
啟動node服務器后,請轉到http://YOUR_WEB_CONSOLE:PORT_NUMBER訪問實時分析Dashboard。如果您的Web控制臺是f.cloudxlab.com,并且node服務器正在端口3002上運行,請轉到http://f.cloudxlab.com:3002訪問Dashboard。
當我們訪問上面的URL時,socket.io-client庫被加載到瀏覽器,它會開啟服務器和瀏覽器之間的雙向通信信道。
階段6
一旦在Kafka的“order-one-min-data”主題中有新消息到達,node進程就會消費它。消費的消息將通過socket.io發送給Web瀏覽器。
階段7
一旦web瀏覽器中的socket.io-client接收到一個新的“message”事件,事件中的數據將會被處理。如果接收的數據中的訂單狀態是“shipped”,它將會被添加到HighCharts坐標系上并顯示在瀏覽器中。
截圖
我們還錄制了一個關于如何運行上述所有的命令并構建實時分析Dashboard的視頻。
我們已成功構建實時分析Dashboard。這是一個基本示例,演示如何集成Spark-streaming,Kafka,node.js和socket.io來構建實時分析Dashboard。現在,由于有了這些基礎知識,我們就可以使用上述工具構建更復雜的系統。