













百萬并發下的Nginx優化,看這一篇就夠了!
本文作者主要分享在 Nginx 性能方面的實踐經驗,希望能給大家帶來一些系統化思考,幫助大家更有效地去做 Nginx。
優化方法論
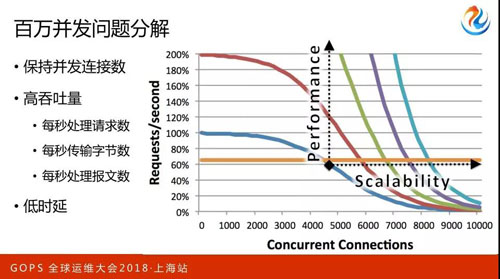
我重點分享如下兩個問題:
- 保持并發連接數,怎么樣做到內存有效使用。
- 在高并發的同時保持高吞吐量的重要要點。
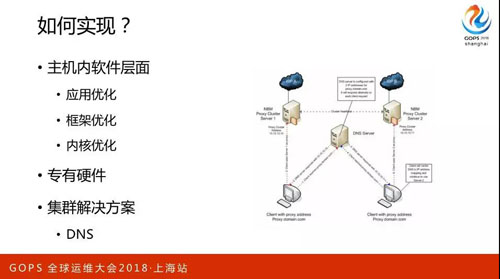
實現層面主要是三方面優化,主要聚焦在應用、框架、內核。
硬件限制可能有的同學也都聽過,把網卡調到萬兆、10G 或者 40G 是最好的,磁盤會根據成本的預算和應用場景來選擇固態硬盤或者機械式硬盤,關注 IOPS 或者 BPS。

CPU 是我們重點看的一個指標。實際上它是把操作系統的切換代價換到了進程內部,所以它從一個連接器到另外一個連接器的切換成本非常低,它性能很好,協程 Openresty 其實是一樣的。
資源的高效使用,降低內存是對我們增大并發性有幫助的,減少 RTT、提升容量。
Reuseport 都是圍繞著提升 CPU 的機核性。還有 Fast Socket,因為我之前在阿里云的時候還做過阿里云的網絡,所以它能夠帶來很大的性能提升,但是問題也很明顯,就是把內核本身的那套東西繞過去了。

請求的“一生”
下面我首先會去聊一下怎么看“請求”,了解完這個以后再去看怎么優化就會很清楚了。
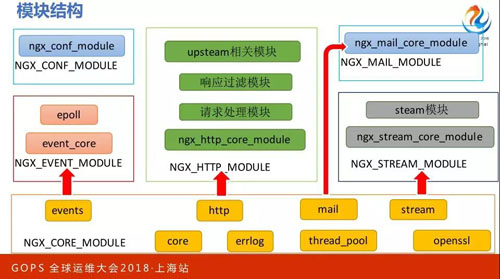
說這個之前必須再說一下 Nginx 的模塊結構,像 Nginx 以外,任何一個外部框架都有個特點,如果想形成整個生態必須允許第三方的代碼接進來,構成一個序列,讓一個請求挨個被模塊共同處理。
那 Nginx 也一樣,這些模塊會串成一個序列,一個請求會被挨個的處理。在核心模塊里有兩個,分別是 Steam 和 NGX。
請求到來
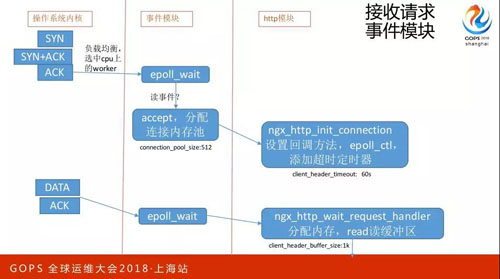
一個連接開始剛剛建立請求到來的時候會發生什么事情?先是操作系統內核中有一個隊列,等著我們的進程去系統調用,這時候因為有很多工作進程,誰會去調用呢,這有個負載均衡策略。
現在有一個事件模塊,調用了 Epoll Wait 這樣的接口,Accept 建立好一個新連接,這時會分配到連接內存池,這個內存池不同于所有的內存池,它在連接剛創建的時候會分配,什么時候會釋放呢?
只有這個連接關閉的時候才會去釋放。接下來就到了 NGX 模塊,這時候會加一個 60 秒的定時器。
就是在建立好連接以后 60 秒之內沒有接到客戶端發來的請求就自動關閉,如果 60 秒過來之后會去分配內存,讀緩沖區。什么意思呢?
現在操作系統內核已經收到這個請求了,但是我的應用程序處理不了,因為沒有給它讀到用戶態的內存里去,所以這時候要分配內存。
從連接內存池這里分配,那要分配多大呢?會擴到 1K。
收到請求
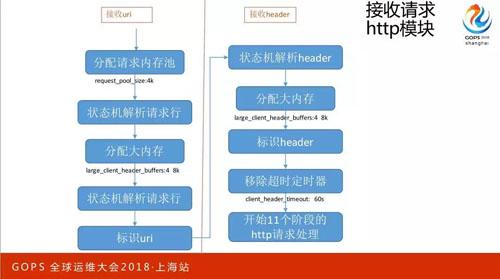
當收到請求以后,接收 Url 和 Header,分配請求內存池,這時候 Request Pool Size 是 4K,大家發現是不是和剛才的有一個 8 倍的差距,這是因為利用態的內存是非常消耗資源的。
再看為什么會消耗資源,首先會用狀態機解去形容,所謂狀態機解就是把它當做一個序列,一個支節一個支節往下解,如果發現換行了那就是請求行解完了。
但如果這個請求特別長的時候,就會去再分配更大的,剛剛 1K 不夠用了,為什么是 4 乘 8K 呢?
就是因為當 1K 不夠了不會一次性分配 32K,而是一次性分配 8K。如果 8K 以后還沒有解析到剛才的標識符,就會分配第二個 8K。
我之前收到的所有東西都不會釋放,只是放一個指針,指到 Url 或者指到那個協議,標識它有多長就可以了。
接下來解決 Header,這個流程一模一樣的沒有什么區別,這時候還會有一個不夠用的情況,當我接收完所有的 Header 以后,會把剛剛的定時器給移除,移除后接下來做 11 個階段的處理。
也就是說剛剛所有的外部服務器都是通過很多的模塊串成在一起處理一個請求的。
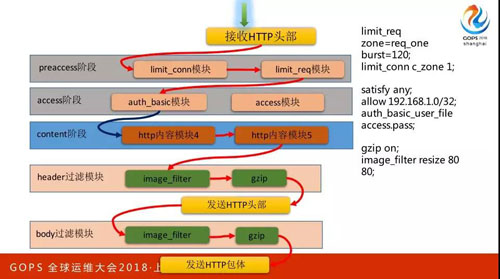
像剛剛兩頁 PPT 都在說藍色的區域,那么請求接下來 11 個階段是什么意思呢?這個黃色的、綠色的,還有右邊這個都是在 11 階段之中。
這 11 個階段大家也不用記,非常簡單,只要掌握三個關鍵詞就可以。
剛剛讀完 Header 要做處理,所以這時候第一階段是 Post-Read。接下來會有 Rewrite,還有 Access 和 Preaccess。
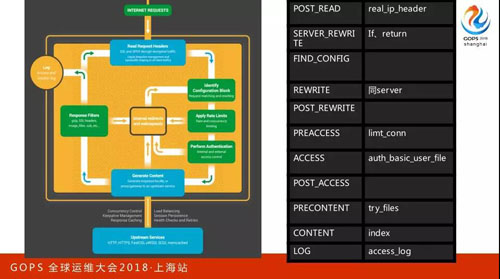
先看左手邊,當我們下載完 Nginx 源碼編以后會有一個 Referer,所有的第三方數據都會在這里呈現有序排列。
這些序列中并不是簡單的一個請求給它再給它,先是分為 11 個階段,每個階段之內大家是有序一個個往后來的,但在 11 個階段中是按階段來的。
我把它分解一下,第一個 Referer 這階段有很多模塊,后面這是有序的。

這個圖比剛剛的圖多了兩個關鍵點:
- 第一到了某一個模塊可以決定繼續向這序列后的模塊執行,也可以說直接跳到下個階段,但不能說跳多個階段。
- 第二是生成了向客戶端反映的響應,這時候要對響應做些處理,這里是有序的,先做縮略圖再做壓縮,所以它是有嚴格順序的。
請求的反向代理
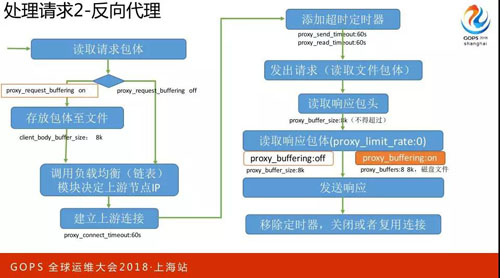
請求的反向代理,反向代理這塊是我們 Nginx 的重點應用場景,因為 Nginx 會考慮一種場景,客戶端走的是公網,所以網絡環境非常差,網速非常慢。
如果簡單用一個緩沖區從客戶端收一點發給上游服務器,那上游服務器的壓力會很大,因為上游服務器往往它的效率高,所以都是一個請求被處理完之前不會再處理下一個請求。
Nginx 考慮到這個場景,它會先把整個請求全部收完以后,再向上游服務器建立連接,所以是默認第一個配置,就是 Proxy Request Buffering On,存放包體至文件,默認 Size 是 8K。
那建立上游連接的時候會放 Time Out,60 秒,添加超時定時器,也是 60 秒的。
發出請求(讀取文體包件),如果向上游傳一個很大的包體的話,那 Sizk 就是 8K。
默認 Proxy Limit Rate 是打開的,我們會先把這個請求全部緩存到端來,所以這時候有個 8×8K,如果關掉的話,也就是從上游發一點就往下游發一點。
知道這個流程以后,再說這里的話大家可以感覺到這里的內存消耗還是蠻大的。
返回響應

返回響應,這里面其實內容蠻多的,我給大家簡化一下,還是剛剛官方的那個包,這也是有順序的從下往上看,如果有大量第三方模塊進來的話,數量會非常高。
第一個關鍵點是上面的 Header Filter,上面是 Write Filter,下面是 Postpone Filter,這里還有一個 Copy Filter,它又分為兩類,一類是需要處理,一類是不需要處理的。
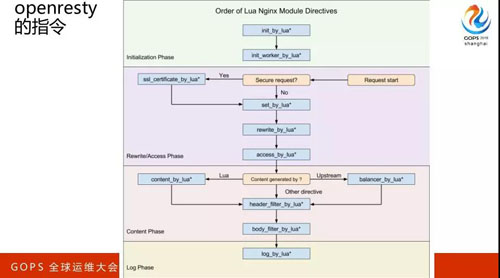
OpenResty 的指令,第一代碼是在哪里執行的,第二個是 SDK。
應用層優化
協議
做應用層的優化我們會先看協議層有沒有什么優化,比如說編碼方式、Header 每次都去傳用 Nginx 的架構,以至于浪費了很多的流量。我們可以改善 Http2,有很多這樣的協議會大幅度提升它的性能。
當然如果你改善 Http2 了,會帶來其他的問題,比如說 Http2 必須走這條路線。
這條路線又是一個很大的話題,它涉及到安全性和性能,是互相沖突的東西。
壓縮
我們希望“商”越大越好,壓縮這里會有一個重點提出來的動態和靜態,比如說我們用了拷貝,比如說可以從磁盤中直接由內核來發網卡,但一旦做壓縮的話就不得不先把這個文件讀到 Nginx,交給后面的極內核去做一下處理。
Keepalive 長連接也是一樣的,它也涉及到很多東西,簡單來看這也就是附用連接。
因為連接有一個慢啟動的過程,一開始它的窗口是比較小,一次可能只傳送很小的 1K 的,但后面可能會傳送幾十K,所以你每次新建連接它都會重新開始,這是很慢的。
當然這里還涉及到一個問題,因為 Nginx 內核它默認打開了一個連接空閑的時候,長連接產生的作用也會下降。
提高內存使用率

剛剛在說具體的請求處理過程中已經比較詳細的把這問題說清楚了,這里再總結一下,在我看來有一個角度,Nginx 對下游只是必須要有的這些模塊,Client Header、Buffer Size:1K,上游網絡 Http 包頭和包體。

CPU 通過緩存去取儲存上東西的時候,它是一批一批取的,每一批目前是 64 字節,所以默認的是 8K。
如果你配了 32 它會給你上升到 64;如果你配了 65 會升到 128,因為它是一個一個序列化重組的。
所以了解這個東西以后自己再配的時候就不會再犯問題。紅黑樹這里用的非常多,因為是和具體的模塊相關。
限速
大部分我們在做分公司流控的時候,主要在限什么呢?主要限 Nginx 向客戶端發送響應的速度。
這東西非常好用,因為可以和 Nginx 定量連接在一起。這不是限上游發請求的速度,而是在限從上游接響應的速度。
Worker 間負載均衡

當時我在用 0.6 版本的時候那時候都在默認用這個,這個“鎖”它是在用進程間同步方式去實現負載均衡,這個負載均衡怎么實現呢?
就是保證所有的 Worker 進程,同一時刻只有一個 Worker 進程在處理距離,這里就會有好幾個問題,綠色的框代表它的吞吐量,吞吐量不高,所以會導致第二個問題 Requests,也是比較長的,這個方差就非常的大。
如果把這個“鎖”關掉以后,可以看到吞吐量是上升的,方差也在下降,但是它的時間在上升,為什么會出現這樣的情況?
因為會導致一個 Worker 可能會非常忙,它的連接數已經非常高了,但是還有其他的 Worker 進程是很閑的。
如果用了 Requests,它會在內核層面上做負載均衡。這是一個專用場景,如果在復雜應用場景下開 Requests 和不開是能看到明顯變化的。
超時
這里我剛剛說了好多,它是一個紅黑樹在實現的。唯一要說的也就是這里,Nginx 現在做四層的反向代理也很成熟了。
像 UTP 協議是可以做反向代理的,但要把有問題的連接迅速踢掉的話,要遵循這個原則,一個請求對一個響應。
緩存
只要想提升性能必須要在緩存上下工夫。比如說我以前在阿里云做云盤,云盤緩存的時候就會有個概念叫空間維度緩存,在讀一塊內容的時候可能會把這內容周邊的其他內容也讀到緩存中。
大家如果熟悉優化的話也會知道有分支預測先把代碼讀到那空間中,這個用的比較少,基于時間維度用的比較多了。
減少磁盤 IO
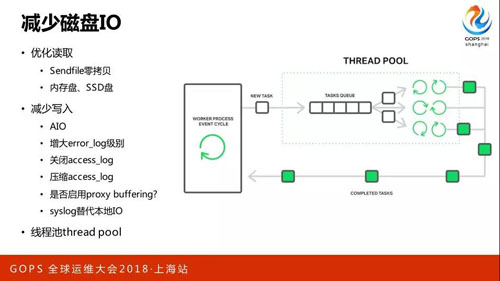
其實要做的事也非常多,優化讀取,Sendfile 零拷貝、內存盤、SSD 盤。減少寫入,AIO,磁盤是遠大于內存的,當它把你內存消化完的時候還會退化成一個調用。
像 Thread Pool 只用讀文件,當退化成這種模式變多線程可以防止它的主進程被阻塞住,這時候官方的博客上說是有 9 倍的性能提升。
系統優化
提升容量配置

我們建連接的時候也有,還有些向客戶端發起連接的時候會有一個端口范圍,還有一些像對于網卡設備的。
CPU緩存的親和性
CPU緩存的親和性,這看情況了,現在用 L3 緩存差不多也 20 兆的規模,CPU 緩存的親和性是一個非常大的話題,這里就不再展開了。
NUMA 架構的 CPU 親和性
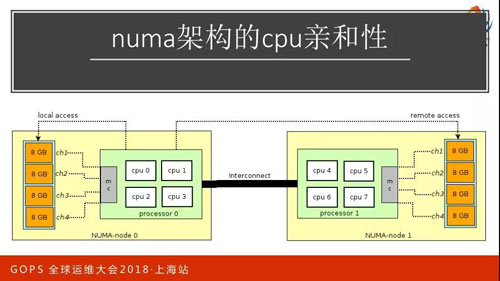
把內存分成兩部分,一部分是靠近這個核,一部分靠近那個核,如果訪問本核的話就會很快,靠近另一邊大概會耗費三倍的損耗。對于多核 CPU 的使用對性能提升很大的話就不要在意這個事情。
網絡快速容錯
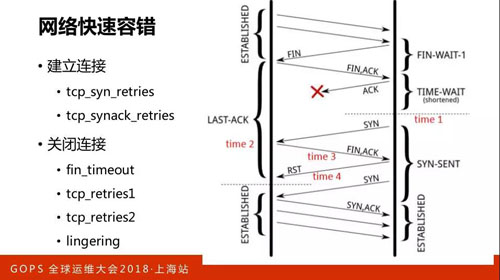
因為 TCP 的連接最麻煩的是在建立連接和關閉連接,這里有很多參數都是在調,每個地方重發,多長時間重發,重發多少次。
這里給大家展示的是快啟動,有好幾個概念在里面,第一個概念在快速啟動的時候是以兩倍的速度。
因為網的帶寬是有限的,當你超出網絡帶寬的時候其中的網絡設備是會被丟包的,也就是控制量在往下降,那再恢復就會比較慢。
TCP 協議優化
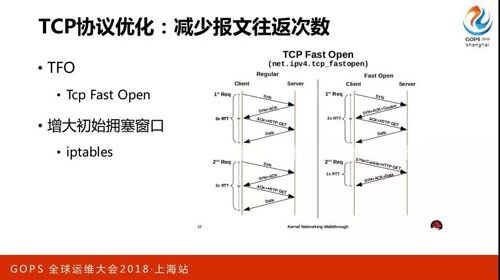
TCP 協議優化,本來可能差不多要四個來回才能達到每次的傳輸在網絡中有幾十 K,那么提前配好的話用增大初始窗口讓它一開始就達到最大流量。
提高資源效率
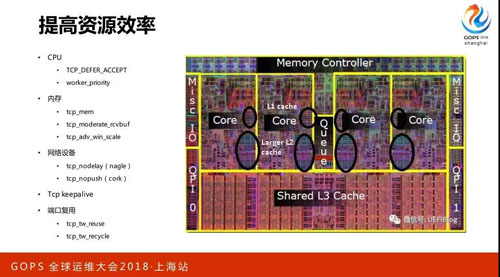
提高資源效率,這一頁東西就挺多了,比如說先從 CPU 看,TCP Defer Accept,如果有這個的話,實際上會犧牲一些即時性,但帶來的好處是第一次建立好連接沒有內容過來的時候是不會激活 Nginx 做切換的。
內存在說的時候是系統態的內存,在內存大和小的時候操作系統做了一次優化,在壓力模式和非壓力模式下為每一個連接分配的系統內存可以動態調整。
網絡設備的核心只解決一個問題,變單個處理為批量處理,批量處理后吞吐量一定是會上升的。
因為消耗的資源變少了,切換次數變少了,它們的邏輯是一樣的,就這些邏輯和我一直在說的邏輯都是同一個邏輯,只是應用在不同層面會產生不同的效果。
端口復用,像 Reals 是很好用的,因為它可以把端口用在上游服務連接的層面上,沒有帶來隱患。
提升多 CPU 使用效率
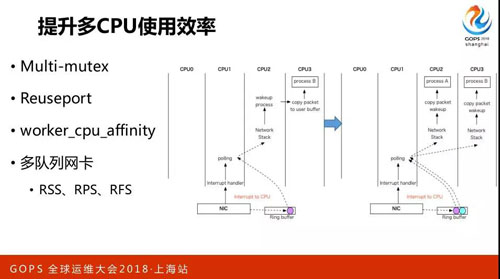
提升多 CPU 使用效率,上面很多東西都說到了,重點就兩個,一是 CPU 綁定,綁定以后緩存更有效。多隊列網卡,從硬件層面上已經能夠做到了。
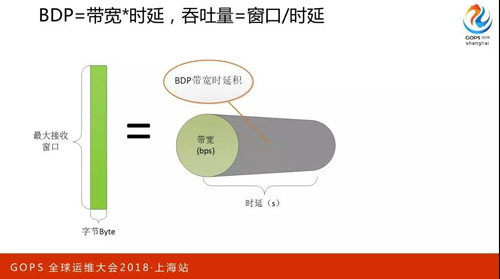
BDP,帶寬肯定是知道的,帶寬和時延就決定了帶寬時延積,那吞吐量等于窗口或者時延。
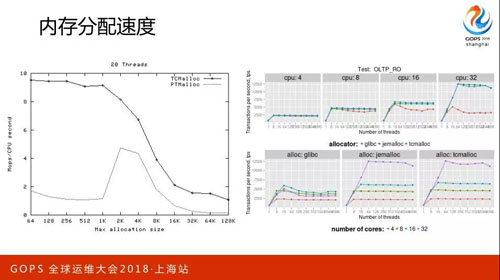
內存分配速度也是我們關注的重點,當并發量很大的時候內存的分配是比較糟糕的,大家可以看到有很多它的競品。
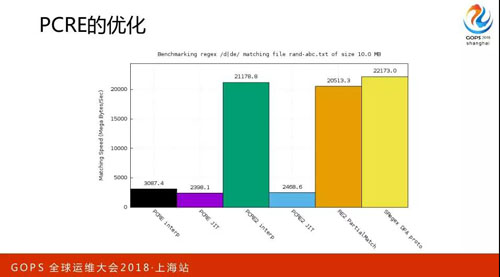
PCRE 的優化,這用最新的版本就好。
作者:陶輝
介紹:曾在華為、騰訊公司做底層數據相關的工作,寫過一本書叫《深入理解 Nginx:模塊開發與架構解析》,目前在杭州智鏈達作為聯合創始人擔任技術總監一職,目前專注于使用互聯網技術助力建筑行業實現轉型升級。






















