













【WOT2018】如何利用數據訓練人工智能?三位大咖教你挖掘數據價值
原創【51CTO.com原創稿件】2018年11月30日-12月1日,WOT2018全球人工智能技術峰會在北京·粵財JW萬豪酒店盛大召開。60+國內外 人工智能一線精英大咖與千余名業界專業人士齊聚現場,分享人工智能的平臺工具、算法模型、語音視覺等技術內容,探討人工智能如何賦予行業新的活力。兩天會議涵蓋通用技術、應用領域、行業賦能三大章節,開設13大技術專場,如機器學習、數據處理、AI平臺與工具、推薦搜索、業務實踐、優化硬件等,堪稱人工智能技術盛會。

大量的數據可以提供訓練學習算法所需,如何利用數據來培訓人工智能,使其獲得更精準的結果?針對這個問題,本屆WOT2018峰會特別設置了《數據處理》分論壇。來自VIPKID、易觀智庫、BBAE Holdings的三位大咖圍繞“聚焦數據處理,挖掘數據價值”進行了主題分享。
智能匹配在在線教育行業的應用
VIPKID是一家在線少兒英語教育公司。VIPKID供需優化技術負責人沈亮主要負責供給側優化、需求匹配、課程質量方面的工作,此次演講他詳細介紹了智能匹配在在線教育行業中的應用。

VIPKID供需優化技術負責人 沈亮
在線教育行業是典型的雙邊市場,雙邊市場的概念是指2組參與者通過中間平臺進行交易,并且一方的收益決定另一方參與者的數量。在VIPKID快速發展的過程中,隨著用戶規模的變大,傳統搶單模式的弊端慢慢暴露出來。比如:用戶無法挑選到合適的老師;用戶選擇其他用戶喜好的老師;以及平臺馬太效應愈發嚴重。和外賣、快遞、出行等行業的發展軌跡一樣,VIPKID慢慢從搶單過度到智能派單,能夠有效地提升平臺的整體效率,同時,提升用戶的產品滿意度。
那么,整個雙邊市場的匹配是一個怎么樣的AI問題呢? 沈亮認為,可以把它分為3個層次,從不同的建設周期來考慮。最長周期是生態規劃的基礎建設,比如:根據需求側的發展來預測一定時間內老師的招募,司機,配送小哥的招募。第二個層次是市場調節,可以通過經濟手段來調節,比如:高峰期的司機補貼、乘客加價,乘客優惠券的發放,老師長期的加薪周期,開課激勵等。第三個層次是單次用戶需求的滿足,通過實時的派單產品、以及用戶搶單產品來實現。
談到如何構建在線教育行業的智能匹配模型,沈亮表示,VIPKID將模型區分為兩個階段,第一階段是用戶找到合適供給的階段,我們構建了個性化的匹配機制。第二階段是用戶找到了合適的供給以后,我們通過約課機制來保障用戶需求能夠持續得到滿足。
VIPKID在優化整體的學習目標時,也是在不斷變化的,每個階段的思考點是不同的。一開始VIPKID按照Feed流產品的思路,用列表頁點擊來做為機器學習的正樣本。其中核心問題是,從Feed流到真正產生交易的概率低,不能代表用戶的核心訴求。第二步,優化用戶約課動作發生,從約課到上課有2周左右的周期,并且用戶對陌生老師的再復約率不到40%。所以有了第三點目標的變化,用戶重復約課的老師是正樣本,用戶約課后不滿意為負樣本。這一步主要的問題是1、不滿意的用戶不表達,2、平臺不好約還是用戶不滿意區分度不強。最終,VIPKID選擇了上課質量做為機器學習的優化目標。
海豚系統是VIPKID的一整套在線視頻的解決方案。以課程質量分析模塊為例,它主要是通過從語音、圖像、交互角度上來分析老師/學生的課堂表現,評估每堂課的教學/學習質量。其中圖像部分主要進行人臉識別/檢測、手勢識別(TPR教學方法)、表情識別(笑臉)、語音方面則包括老師語音識別、語音情感識別、噪音識別。通過這些課堂的特征來構建課堂質量評估模型,VIPKID通過專家標注+數據挖掘的方式來區分好課和差課。
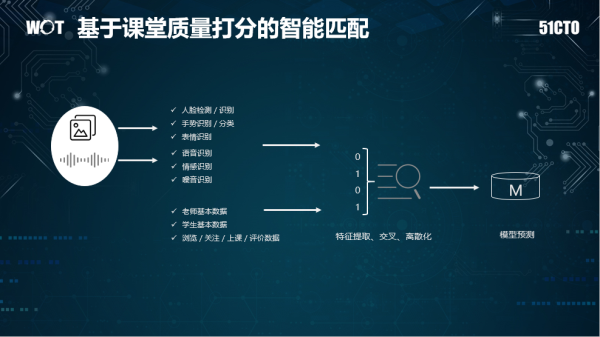
有了課堂質量分的概念,對于一個陌生老師,VIPKID則會提取該老師最近上課視頻中的語音、圖像相關的特征,學生喜歡的老師圖像、語音相關特征,以及老師/學生的一部分結構化數據,進行特征挖掘、交叉和離散化從而構建不同的模型,然后發布到線上A/B測試來監控質量、以及核心指標的變化。
在市場機制、規則設計上,VIPKID推出了專屬外教產品,能夠讓用戶通過簡單的一步即可和自己喜歡的老師長期上課。專屬外教的產品邏輯是這樣的,首先,用戶設置自己喜歡的老師和上課時間,第二步,系統會在所有的規則集合內進行系統派單,從數學角度上來看,這是一個簡單的2分加權圖的分配問題。VIPKID用了傳統的KM (Kuhn-Munkres)算法了解決,也取得了不錯的效果。
VIPKID通過構建基于課程質量的智能匹配模型,完善了師生穩定上課階段的派單引擎;另外,VIPKID在供給側采用了相對隔離,以及師生匹配的預分配。上線前后最大的變化就是,它讓用戶更快地選擇到適合自己的老師,可以從兩方面衡量,第一,用戶找到合適老師的成本(課節數)下降40%;其次,用戶找到合適老師的時間下降了33%。
另外,智能匹配也使得用戶不需要搶課,有了更好的約課體驗;從數據上有兩點明顯改進,第一,周一高峰期來搶課的用戶群體下降幅度高達42%。第二,系統派單的占比持續提升,4個月時間,提升比例高達85%。

基于IOTA架構的實時數據引擎
易觀智庫CTO郭煒分享了題為《IOTA 數據架構——基于邊緣計算的適用于大數據和人工智能新一代計算架構》的主題演講,詳細講解了基于IOTA數據河的計算引擎的實現思路,以及數據河的基本理念。

易觀智庫CTO 郭煒
郭煒指出,現代大部分企業都在面臨大數據困境,存在大數據“大而不強”,人工智能 “人工”而不“智能”的問題。企業在應用大數據的過程中,無論是大數據部門的研發、總監還是架構師都會面臨四大挑戰:
- 隨著大數據、人工智能的火爆,相關人才嚴重不足;
- IoT正在讓數據量持續爆發,移動互聯網數據將會增長十倍,乃至幾十倍,大數據存儲永遠不夠,并且企業并不知道這些數據如何利用;
- 業務分析多變難以滿足:業務部門希望通過選擇維度或者拖拽的方式,能夠盡可能快的展現出結果。隨著數據量越來越大,定義指標、預定維度正在變得越來越困難;
- IoT,移動端,CRM數據正在變得越來越多,越來越復雜,格式也不統一。
他認為,要解決企業的這些問題,就需要使用新一代的數據計算架構IOTA架構——基于邊緣計算的適用于大數據和人工智能新一代計算架構。它將數據和AI模型,從中央集中計算放到邊緣進行計算,最終形成企業數據的業務閉環,提高企業運行效率。IOTA架構擴展到整個企業就形成了數據水系的理論,數據河補全了數據湖的流動性問題,將IOTA架構擴展到整個企業,從而改善整個企業大數據和人工智能與業務的交互效率以及自身技術的發展速度。
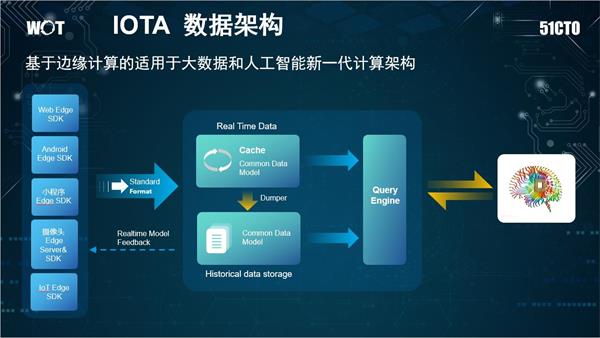
IOTA數據架構具有四大優勢:
- 去ETL ((Extract-Transform-Load))化架構:過去企業都在做ETL,每次都要進行各種各樣的數據處理,而IOTA架構則不再使用ETL,所有數據產生的時候就已經處理好,可以直接放到云端,進行數據查詢;
- 非結構化實時結構化為SQL數據存儲:大量事件都是非結構化數據,企業所要做的是把其實時轉化為結構化數據進行存儲。
- 支持IoT設備與現有移動端數據融合:企業常常會遇到Web端和Android端的用戶如何打通的問題,需要花費企業很多精力,搭建平臺進行分層,而現在就可以直接進行數據的融合。
- 支持邊緣AI實時反饋:一方面,企業可以把數據直接存儲在云端,很快的查詢到邊緣的數據。另一方面,在一些簡單的數據模型中,企業可以把參數下放到SDK中,讓SDK進行集成。而不再需要每次都在云端進行大量計算,直接在邊緣端進行計算即可。
IOTA的整體技術結構分為幾部分:
- 核心模型Common Data Model:始終貫穿IOTA架構的數據模型,需要SDK、Cache、歷史數據、查詢引擎保持一致。對于用戶數據分析來講,可以定義為“主-謂-賓”或者“對象-事件”這樣的抽象模型來滿足各種各樣的查詢。以APP用戶模型為例,用“主-謂-賓”模型描述就是“X用戶 – 事件1 – A頁面(2018/4/11 20:00) ”。
- 核心組件Edge SDK:不僅僅是過去的簡單的SDK,在復雜的計算情況下,會賦予SDK更復雜的計算, 在設備端就轉化為形成統一的數據模型來進行傳送。例如,對于智能Wi-Fi采集的數據,從AC端就變為“X用戶的MAC 地址-出現- A樓層(2018/4/11 18:00)”這種主-謂-賓結構,對于攝像頭會通過Edge AI Server,轉化成為“X的Face特征- 進入- A火車站(2018/4/11 20:00)”,對于智能音箱就會變為“X用戶-啟動-Y設備 (2018/4/11 20:00)”。
與此同時,企業如何利用數據產生價值呢?郭煒給出的答案是企業需要打造一個數據驅動的中臺。很多企業認為,數據中臺就是把各種數據組件打包、把大數據存儲好即可。但是隨著時間積累,數據中臺就會從數據湖變成數據沼澤。由此,易觀提出了數據河的概念,中國有句俗話叫“流水不腐,戶樞不蠹”,也就是數據一定要像河水一樣流動起來,才不會產生瘀泥。具體來說,數據河就是,從數據產生端直接通過IOTA架構數據河實時流向數據使用者,而不再需要像過去一樣層層加工之后才能使用,其好處就在于如果遇到數據質量發生問題,不用等到數據加工完幾天甚至是一個月之后才發現,而是在最早的時間,數據的發生者和使用者就能夠很快的發現問題,從而驅動解決問題。
最后,郭煒為與會者舉了一個IOTA架構引擎的實例——易觀秒算,具有以下六大特點:
- 去“ETL”化;
- 高效:時時入庫即時分析;
- 穩定:經過易觀5.8Pb,5.2億月活數據錘煉;
- 跨數據庫:天然支持“Data Federation”數據聯邦針對MySQL等數據庫跨庫查詢;
- 便捷:支持SQL級別的二次開發和UDAF定義;
- 擴充性強:組件基于Apache開源協議,可支持眾多開源存儲對接。

基于大數據AI的金融建模
來自SEC備案注冊的初創投資顧問平臺BBAE Holdings的CTO劉玥帶來了題為《基于大數據AI的金融建模——BBAE 智能投顧模型的機器學習實踐》的主題演講,圍繞BBAE智能投顧產品的設計實現,詳細介紹了如何基于統計模型和機器學習來構建一個自適應的資產管理組合。

BBAE Holdings CTO 劉玥
劉玥首先介紹了智能投顧的前世今生。Robo Advisory(智能投顧)概念始于2008經濟危機后,2010年,Betterment將基于算法的資產管理模式成功帶入人們的視線。德勤預計2025年,美國基于AI和算法模型的資產管理模式將管理多達5萬億至7萬億美金的資產。
傳統的建模方法包括Risk Neutral、Constant Mix、60/40、Equal Weighted。
- Risk Neutral:例如,給定兩個投資機會,風險中性投資者只關注每個投資的潛在收益,而忽略潛在的下行風險;
- Constant Mix:你買入低價并且賣得很高,因為你賣出表現最好的股票來買入表現最差的股票;
- 60/40:60%的股票和40%的債券或其他固定收益產品;
- Equal Weighted:許多最大和最知名的市場指數是市值加權或價格加權。市值加權指數,如標準普爾500指數,根據市值對大公司給予更大的重視。蘋果和通用電氣等大型股是標準普爾500指數中最大的股票。道瓊斯工業平均指數等價格加權指數給股票價格上漲的股票帶來更大的權重。小盤股通常被認為比大盤股具有更高的風險,更高的潛在回報投資。理論上,在等權重的投資組合中給標準普爾500指數中較小的股票賦予更大的權重,應該會增加投資組合的回報潛力。
這些模型雖然簡單直觀,但過于依賴條件假設,難以個性化。自2008年有了智能投顧這個概念之后,大家越來越多的會把統計模型用于金融分析的領域中。
預期收益計算也有很多傳統方法,和機器學習方法形成了兩大陣營。現代投資組合理論(MPT)是由Harry Markowitz于1952年提出,是一種試圖通過在收益和風險之間取得平衡來創建資產組合的理論。其基本理論是,可以在給定一定風險的情況下最大化投資組合預期收益,或者等效地降低給定收益水平的風險。
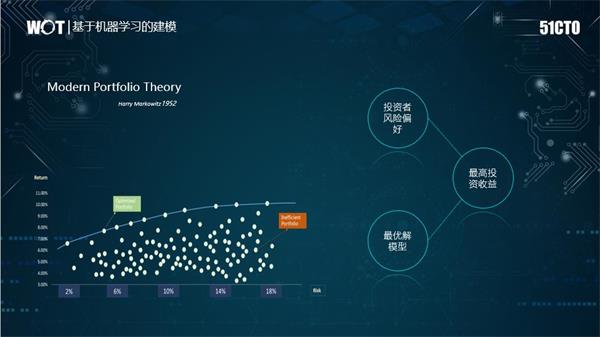
MPT的一個主要思想是,資產組合不應基于單個資產的表現,而應整體地考慮資產績效。這意味著在評估投資組合時必須考慮投資組合的內部風險收益動態。 MPT的經典數學模型使用平均收益作為預期收益的度量,并使用收益方差作為風險度量。
根據風險調整后的收益對有效邊界進行優化,并通過考慮市場收益、獨立風險和相關風險的量化方法獲得有效邊界,從而在結構良好的低相關市場組合 中消除市場獨立風險。 然后可以識別最優分配并將其應用于不同的客戶。
這其中,有三個核心要素,包括Market Return(預期收益向量)、Market Risk(預期風險(協方差矩陣))、Constraints(約束條件)。
資本資產定價模型(CAPM)是由William Sharpe創建的模型,它根據市場回報和資產與市場回報的線性關系來估計資產的收益。 這種線性關系是股票的β系數。CAPM使用簡單的線性回歸,而FF使用具有許多自變量的多元回歸。 因此,我們的3因子FF方程是lm( R_excess~MKT_RF + SMB + HML。例如,我們可以用過去 26 期周收益率數據的均值當做下周周收益率均值的預測。由于每個投資品的預測只用到自己過去的歷史數據,因此這個模型是無結構性的(它相當于每個投資品自成一個因子)。此外,基于歷史數據的預測是無偏的(unbiased)。
舉一個例子,預測市場收益與不同宏觀變量的關系,如石油,美元,波動率,消費者信心,利率等。在傳統統計中,分析師會采用線性回歸來計算這些變量的市場收益的β值。通過機器學習,分析師可以使用先進的回歸模型計算風險,這些回歸模型將考慮異常值,以穩健的方式處理大量變量,區分相關輸入變量,考慮潛在的非線性效應等。通過計算機科學家開發的新算法使回歸成為可能。例如,一個擴展 - 稱為套索回歸 - 選擇輸入變量的最小必要子集。另一種算法 - 稱為邏輯回歸 - 適用于處理數據,其中結果輸出是二進制值,如“買入”或“賣出”。該方法涉及將觀察組隨機地劃分為大小相等的k組或折疊。第一個折疊被視為驗證集,并且該方法適合剩余的k-1倍。

在估計每個時間幀的協方差矩陣時,BBAE Holdings采用了機器學習方法,包括K最近鄰(kNN,k-NearestNeighbor)分類算法和Lasso算法,我們發現這些方法可以提高檢驗結果偏差(out of specification)性能,而不是傳統的估算方法。像Lasso和Ridge是對普通線性回歸的簡單修改,旨在在存在大量潛在相關變量的情況下創建更穩健的輸出模型。當輸入特征的數量很大或輸入特征相關時,經典線性回歸傾向于過度擬合并產生虛假系數。 LASSO,Ridge和彈性網絡回歸也是“正規化”的例子 - 機器學習中的一種技術,有望減少樣本外的預測錯誤(但無助于減少樣本內回溯錯誤)。
例如,市場狀況類別可以定義為強牛、牛、中性、熊和強熊。該算法使用SVM (Support Vector Machine)和Ransom Forrest這些技術進行數據輸入的處理,包括基本因素和技術因素,然后可以將其市場定義為五種類型之一。如果市場屬于強牛類,則該算法可以調整(其他條件,如投資者的風險偏好可能適用)相應市場的下限約束,如果市場屬于熊類,則可以減小所述市場的上限約束以控制風險暴露。

以上內容是51CTO記者根據WOT2018全球人工智能技術峰會的《數據處理》分論壇演講內容整理,更多關于WOT的內容請關注51cto.com。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】


























