Apache Flink 漫談系列(12) - Time Interval(Time-windowed) JOIN
一、說什么
JOIN 算子是數據處理的核心算子,前面我們在《Apache Flink 漫談系列(09) - JOIN 算子》介紹了UnBounded的雙流JOIN,在《Apache Flink 漫談系列(10) - JOIN LATERAL》介紹了單流與UDTF的JOIN操作,在《Apache Flink 漫談系列(11) - Temporal Table JOIN》又介紹了單流與版本表的JOIN,本篇將介紹在UnBounded數據流上按時間維度進行數據劃分進行JOIN操作 - Time Interval(Time-windowed)JOIN, 后面我們叫做Interval JOIN。
二、實際問題
前面章節我們介紹了Flink中對各種JOIN的支持,那么想想下面的查詢需求之前介紹的JOIN能否滿足?需求描述如下:
比如有一個訂單表Orders(orderId, productName, orderTime)和付款表Payment(orderId, payType, payTime)。 假設我們要統計下單一小時內付款的訂單信息。
1. 傳統數據庫解決方式
在傳統劉數據庫中完成上面的需求非常簡單,查詢sql如下::
- SELECT
- o.orderId,
- o.productName,
- p.payType,
- o.orderTime,
- payTime
- FROM
- Orders AS o JOIN Payment AS p ON
- o.orderId = p.orderId AND p.payTime >= orderTime AND p.payTime < orderTime + 3600 // 秒
上面查詢可以***的完成查詢需求,那么在Apache Flink里面應該如何完成上面的需求呢?
2. Apache Flink解決方式
(1) UnBounded 雙流 JOIN
上面查詢需求我們很容易想到利用《Apache Flink 漫談系列(09) - JOIN 算子》介紹了UnBounded的雙流JOIN,SQL語句如下:
- SELECT
- o.orderId,
- o.productName,
- p.payType,
- o.orderTime,
- payTime
- FROM
- Orders AS o JOIN Payment AS p ON
- o.orderId = p.orderId AND p.payTime >= orderTime AND p.payTime as timestamp < TIMESTAMPADD(SECOND, 3600, orderTime)
UnBounded雙流JOIN可以解決上面問題,這個示例和本篇要介紹的Interval JOIN有什么關系呢?
(2) 性能問題
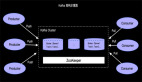
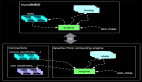
雖然我們利用UnBounded的JOIN能解決上面的問題,但是仔細分析用戶需求,會發現這個需求場景訂單信息和付款信息并不需要長期存儲,比如2018-12-27 14:22:22的訂單只需要保持1小時,因為超過1個小時的訂單如果沒有被付款就是無效訂單了。同樣付款信息也不需要長期保持,2018-12-27 14:22:22的訂單付款信息如果是2018-12-27 15:22:22以后到達的那么我們也沒有必要保存到State中。 而對于UnBounded的雙流JOIN我們會一直將數據保存到State中,如下示意圖:
這樣的底層實現,對于當前需求有不必要的性能損失。所以我們有必要開發一種新的可以清除State的JOIN方式(Interval JOIN)來高性能的完成上面的查詢需求。
(3) 功能擴展
目前的UnBounded的雙流JOIN是后面是沒有辦法再進行Event-Time的Window Aggregate的。也就是下面的語句在Apache Flink上面是無法支持的:
- SELECT COUNT(*) FROM (
- SELECT
- ...,
- payTime
- FROM Orders AS o JOIN Payment AS p ON
- o.orderId = p.orderId
- ) GROUP BY TUMBLE(payTime, INTERVAL '15' MINUTE)
因為在UnBounded的雙流JOIN中無法保證payTime的值一定大于WaterMark(WaterMark相關可以查閱<
3. Interval JOIN
為了完成上面需求,并且解決性能和功能擴展的問題,Apache Flink在1.4開始開發了Time-windowed Join,也就是本文所說的Interval JOIN。接下來我們詳細介紹Interval JOIN的語法,語義和實現原理。
三、什么是Interval JOIN
Interval JOIN 相對于UnBounded的雙流JOIN來說是Bounded JOIN。就是每條流的每一條數據會與另一條流上的不同時間區域的數據進行JOIN。對應Apache Flink官方文檔的 Time-windowed JOIN(release-1.7之前都叫Time-Windowed JOIN)。
1. Interval JOIN 語法
- SELECT ... FROM t1 JOIN t2 ON t1.key = t2.key AND TIMEBOUND_EXPRESSION
TIMEBOUND_EXPRESSION 有兩種寫法,如下:
- L.time between LowerBound(R.time) and UpperBound(R.time)
- R.time between LowerBound(L.time) and UpperBound(L.time)
- 帶有時間屬性(L.time/R.time)的比較表達式。
2. Interval JOIN 語義
Interval JOIN 的語義就是每條數據對應一個 Interval 的數據區間,比如有一個訂單表Orders(orderId, productName, orderTime)和付款表Payment(orderId, payType, payTime)。 假設我們要統計在下單一小時內付款的訂單信息。SQL查詢如下:
- SELECT
- o.orderId,
- o.productName,
- p.payType,
- o.orderTime,
- cast(payTime as timestamp) as payTime
- FROM
- Orders AS o JOIN Payment AS p ON
- o.orderId = p.orderId AND
- p.payTime BETWEEN orderTime AND
- orderTime + INTERVAL '1' HOUR
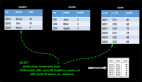
- Orders訂單數據
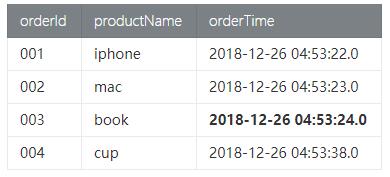
- Payment付款數據
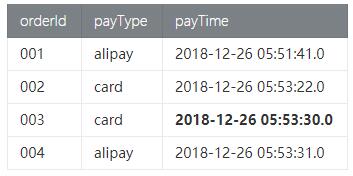
符合語義的預期結果是 訂單id為003的信息不出現在結果表中,因為下單時間2018-12-26 04:53:24.0, 付款時間是 2018-12-26 05:53:30.0超過了1小時付款。
那么預期的結果信息如下:

這樣Id為003的訂單是無效訂單,可以更新庫存繼續售賣。
接下來我們以圖示的方式直觀說明Interval JOIN的語義,我們對上面的示例需求稍微變化一下: 訂單可以預付款(不管是否合理,我們只是為了說明語義)也就是訂單 前后 1小時的付款都是有效的。SQL語句如下:
- SELECT
- ...
- FROM
- Orders AS o JOIN Payment AS p ON
- o.orderId = p.orderId AND
- p.payTime BETWEEN orderTime - INTERVAL '1' HOUR AND
- orderTime + INTERVAL '1' HOUR
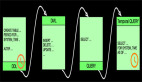
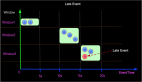
這樣的查詢語義示意圖如下:
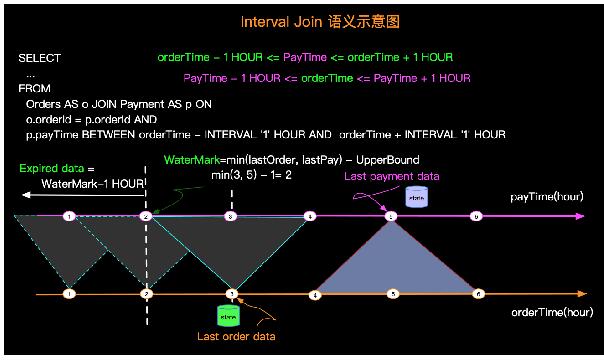
上圖有幾個關鍵點,如下:
- 數據JOIN的區間 - 比如Order時間為3的訂單會在付款時間為[2, 4]區間進行JOIN。
- WaterMark - 比如圖示Order***一條數據時間是3,Payment***一條數據時間是5,那么WaterMark是根據實際最小值減去UpperBound生成,即:Min(3,5)-1 = 2
- 過期數據 - 出于性能和存儲的考慮,要將過期數據清除,如圖當WaterMark是2的時候時間為2以前的數據過期了,可以被清除。
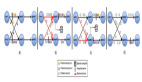
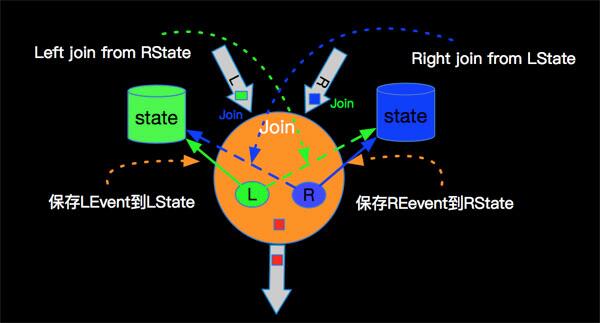
3. Interval JOIN 實現原理
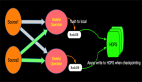
由于Interval JOIN和雙流JOIN類似都要存儲左右兩邊的數據,所以底層實現中仍然是利用State進行數據的存儲。流計算的特點是數據不停的流入,我們可以不停的進行增量計算,也就是我們每條數據流入都可以進行JOIN計算。我們還是以具體示例和圖示來說明內部計算邏輯,如下圖:
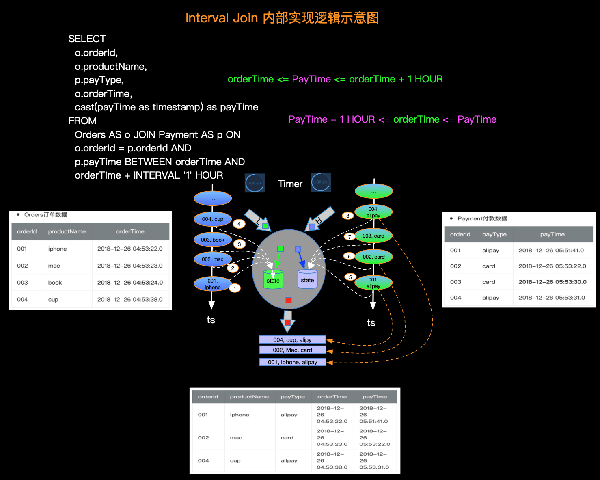
簡單解釋一下每條記錄的處理邏輯如下:

實際的內部邏輯會比描述的復雜的多,大家可以根據如上簡述理解內部原理即可。
四、示例代碼
我們還是以訂單和付款示例,將完整代碼分享給大家,具體如下(代碼基于flink-1.7.0):
- import java.sql.Timestamp
- import org.apache.flink.api.scala._
- import org.apache.flink.streaming.api.TimeCharacteristic
- import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
- import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
- import org.apache.flink.streaming.api.windowing.time.Time
- import org.apache.flink.table.api.TableEnvironment
- import org.apache.flink.table.api.scala._
- import org.apache.flink.types.Row
- import scala.collection.mutable
- object SimpleTimeIntervalJoin {
- def main(args: Array[String]): Unit = {
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- val tEnv = TableEnvironment.getTableEnvironment(env)
- env.setParallelism(1)
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
- // 構造訂單數據
- val ordersData = new mutable.MutableList[(String, String, Timestamp)]
- ordersData.+=(("001", "iphone", new Timestamp(1545800002000L)))
- ordersData.+=(("002", "mac", new Timestamp(1545800003000L)))
- ordersData.+=(("003", "book", new Timestamp(1545800004000L)))
- ordersData.+=(("004", "cup", new Timestamp(1545800018000L)))
- // 構造付款表
- val paymentData = new mutable.MutableList[(String, String, Timestamp)]
- paymentData.+=(("001", "alipay", new Timestamp(1545803501000L)))
- paymentData.+=(("002", "card", new Timestamp(1545803602000L)))
- paymentData.+=(("003", "card", new Timestamp(1545803610000L)))
- paymentData.+=(("004", "alipay", new Timestamp(1545803611000L)))
- val orders = env
- .fromCollection(ordersData)
- .assignTimestampsAndWatermarks(new TimestampExtractor[String, String]())
- .toTable(tEnv, 'orderId, 'productName, 'orderTime.rowtime)
- val ratesHistory = env
- .fromCollection(paymentData)
- .assignTimestampsAndWatermarks(new TimestampExtractor[String, String]())
- .toTable(tEnv, 'orderId, 'payType, 'payTime.rowtime)
- tEnv.registerTable("Orders", orders)
- tEnv.registerTable("Payment", ratesHistory)
- var sqlQuery =
- """
- |SELECT
- | o.orderId,
- | o.productName,
- | p.payType,
- | o.orderTime,
- | cast(payTime as timestamp) as payTime
- |FROM
- | Orders AS o JOIN Payment AS p ON o.orderId = p.orderId AND
- | p.payTime BETWEEN orderTime AND orderTime + INTERVAL '1' HOUR
- |""".stripMargin
- tEnv.registerTable("TemporalJoinResult", tEnv.sqlQuery(sqlQuery))
- val result = tEnv.scan("TemporalJoinResult").toAppendStream[Row]
- result.print()
- env.execute()
- }
- }
- class TimestampExtractor[T1, T2]
- extends BoundedOutOfOrdernessTimestampExtractor[(T1, T2, Timestamp)](Time.seconds(10)) {
- override def extractTimestamp(element: (T1, T2, Timestamp)): Long = {
- element._3.getTime
- }
- }
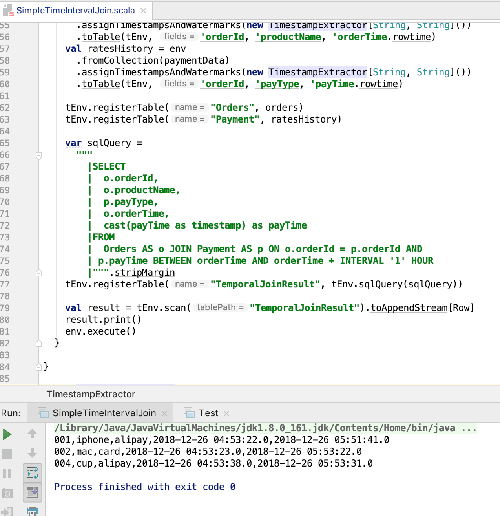
運行結果如下:
五、小節
本篇由實際業務需求場景切入,介紹了相同業務需求既可以利用Unbounded 雙流JOIN實現,也可以利用Time Interval JOIN來實現,Time Interval JOIN 性能優于UnBounded的雙流JOIN,并且Interval JOIN之后可以進行Window Aggregate算子計算。然后介紹了Interval JOIN的語法,語義和實現原理,***將訂單和付款的完整示例代碼分享給大家。期望本篇能夠讓大家對Apache Flink Time Interval JOIN有一個具體的了解!
關于點贊和評論
本系列文章難免有很多缺陷和不足,真誠希望讀者對有收獲的篇章給予點贊鼓勵,對有不足的篇章給予反饋和建議,先行感謝大家!
作者:孫金城,花名 金竹,目前就職于阿里巴巴,自2015年以來一直投入于基于Apache Flink的阿里巴巴計算平臺Blink的設計研發工作。
【本文為51CTO專欄作者“金竹”原創稿件,轉載請聯系原作者】