Apache Flink 漫談系列(07) - 持續查詢(Continuous Queries)
一、實際問題
我們知道在流計算場景中,數據是源源不斷的流入的,數據流永遠不會結束,那么計算就永遠不會結束,如果計算永遠不會結束的話,那么計算結果何時輸出呢?本篇將介紹Apache Flink利用持續查詢來對流計算結果進行持續輸出的實現原理。
二、數據管理
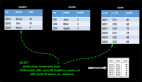
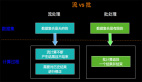
在介紹持續查詢之前,我們先看看Apache Flink對數據的管理和傳統數據庫對數據管理的區別,以MySQL為例,如下圖:

如上圖所示傳統數據庫是數據存儲和查詢計算于一體的架構管理方式,這個很明顯,oracle數據庫不可能管理MySQL數據庫數據,反之亦然,每種數據庫廠商都有自己的數據庫管理和存儲的方式,各自有特有的實現。在這點上Apache Flink海納百川(也有corner case),將data store 進行抽象,分為source(讀) 和 sink(寫)兩種類型接口,然后結合不同存儲的特點提供常用數據存儲的內置實現,當然也支持用戶自定義的實現。
那么在宏觀設計上Apache Flink與傳統數據庫一樣都可以對數據表進行SQL查詢,并將產出的結果寫入到數據存儲里面,那么Apache Flink上面的SQL查詢和傳統數據庫查詢的區別是什么呢?Apache Flink又是如何做到求同(語義相同)存異(實現機制不同),***支持ANSI-SQL的呢?
三、靜態查詢
傳統數據庫中對表(比如 flink_tab,有user和clicks兩列,user主鍵)的一個查詢SQL(select * from flink_tab)在數據量允許的情況下,會立刻返回表中的所有數據,在查詢結果顯示之后,對數據庫表flink_tab的DML操作將與執行的SQL無關了。也就是說傳統數據庫下面對表的查詢是靜態查詢,將計算的最終查詢的結果立即輸出,如下:
- select * from flink_tab;
- +----+------+--------+
- | id | user | clicks |
- +----+------+--------+
- | 1 | Mary | 1 |
- +----+------+--------+
- 1 row in set (0.00 sec)
當我執行完上面的查詢,查詢結果立即返回,上面情況告訴我們表 flink_tab里面只有一條記錄,id=1,user=Mary,clicks=1; 這樣傳統數據庫表的一條查詢語句就完全結束了。傳統數據庫表在查詢那一刻我們這里叫Static table,是指在查詢的那一刻數據庫表的內容不再變化了,查詢進行一次計算完成之后表的變化也與本次查詢無關了,我們將在Static Table 上面的查詢叫做靜態查詢。
四、持續查詢
什么是連續查詢呢?連續查詢發生在流計算上面,在 《Apache Flink 漫談系列 - 流表對偶(duality)性》 中我們提到過Dynamic Table,連續查詢是作用在Dynamic table上面的,永遠不會結束的,隨著表內容的變化計算在不斷的進行著...
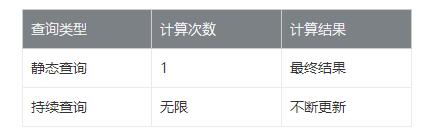
五、靜態/持續查詢特點
靜態查詢和持續查詢的特點就是《Apache Flink 漫談系列 - 流表對偶(duality)性》中所提到的批與流的計算特點,批一次查詢返回一個計算結果就結束查詢,流一次查詢不斷修正計算結果,查詢永遠不結束,表格示意如下:
六、靜態/持續查詢關系
接下來我們以flink_tab表實際操作為例,體驗一下靜態查詢與持續查詢的關系。假如我們對flink_tab表再進行一條增加和一次更新操作,如下:
- MySQL> insert into flink_tab(user, clicks) values ('Bob', 1);
- Query OK, 1 row affected (0.08 sec)
- MySQL> update flink_tab set clicks=2 where user='Mary';
- Query OK, 1 row affected (0.06 sec)
這時候我們再進行查詢 select * from flink_tab ,結果如下:
- MySQL> select * from flink_tab;
- +----+------+--------+
- | id | user | clicks |
- +----+------+--------+
- | 1 | Mary | 2 |
- | 2 | Bob | 1 |
- +----+------+--------+
- 2 rows in set (0.00 sec)
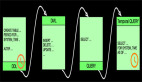
那么我們看見,相同的查詢SQL(select * from flink_tab),計算結果完全 不 一樣了。這說明相同的sql語句,在不同的時刻執行計算,得到的結果可能不一樣(有點像廢話),就如下圖一樣:
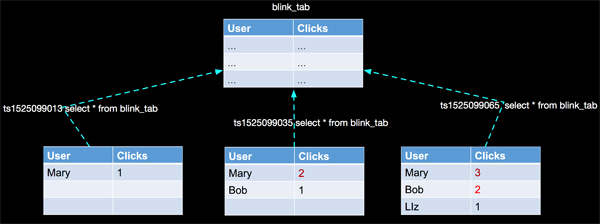
假設不斷的有人在對表flink_tab做操作,同時有一個人間歇性的發起對表數據的查詢,上圖我們只是在三個時間點進行了3次查詢。并且在這段時間內數據表的內容也在變化。引起上面變化的DML如下:
- MySQL> insert into flink_tab(user, clicks) values ('Llz', 1);
- Query OK, 1 row affected (0.08 sec)
- MySQL> update flink_tab set clicks=2 where user='Bob';
- Query OK, 1 row affected (0.01 sec)
- Rows matched: 1 Changed: 1 Warnings: 0
- MySQL> update flink_tab set clicks=3 where user='Mary';
- Query OK, 1 row affected (0.05 sec)
- Rows matched: 1 Changed: 1 Warnings: 0
到現在我們不難想象,上面圖內容的核心要點如下:
- 時間
- 表數據變化
- 觸發計算
- 計算結果更新
接下來我們利用傳統數據庫現有的機制模擬一下持續查詢...
1. 無PK的 Append only 場景
接下來我們把上面隱式存在的時間屬性timestamp作為表flink_tab_ts(timestamp,user,clicks三列,無主鍵)的一列,再寫一個 觸發器(Trigger) 示例觀察一下:
- // INSERT 的時候查詢一下數據flink_tab_ts,將結果寫到trigger.sql中
- DELIMITER ;;
- create trigger flink_tab_ts_trigger_insert after insert
- on flink_tab_ts for each row
- begin
- select ts, user, clicks from flink_tab_ts into OUTFILE '/Users/jincheng.sunjc/testdir/atas/trigger.sql';
- end ;;
- DELIMITER ;
上面的trigger要將查詢結果寫入本地文件,默認MySQL是不允許寫入的,我們查看一下:
- MySQL> show variables like '%secure%';
- +--------------------------+-------+
- | Variable_name | Value |
- +--------------------------+-------+
- | require_secure_transport | OFF |
- | secure_file_priv | NULL |
- +--------------------------+-------+
- 2 rows in set (0.00 sec)
上面secure_file_priv屬性為NULL,說明MySQL不允許寫入file,我需要修改my.cnf在添加secure_file_priv=''打開寫文件限制;
- MySQL> show variables like '%secure%';
- +--------------------------+-------+
- | Variable_name | Value |
- +--------------------------+-------+
- | require_secure_transport | OFF |
- | secure_file_priv | |
- +--------------------------+-------+
- 2 rows in set (0.00 sec)
下面我們對flink_tab_ts進行INSERT操作:

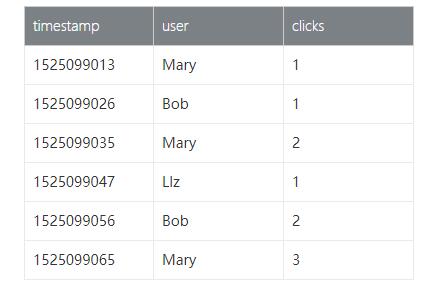
我們再來看看6次trigger 查詢計算的結果:

大家到這里發現我寫了Trigger的存儲過程之后,每次在數據表flink_tab_ts進行DML操作的時候,Trigger就會觸發一次查詢計算,產出一份新的計算結果,觀察上面的查詢結果發現,結果表不停的增加(Append only)。
2. 有PK的Update場景
我們利用flink_tab_ts的6次DML操作和自定義的觸發器TriggerL來介紹了什么是持續查詢,做處理靜態查詢與持續查詢的關系。那么上面的演示目的是為了說明持續查詢,所有操作都是insert,沒有基于主鍵的更新,也就是說Trigger產生的結果都是append only的,那么大家想一想,如果我們操作flink_tab這張表,按主鍵user進行插入和更新操作,同樣利用Trigger機制來進行持續查詢,結果是怎樣的的呢? 初始化表,trigger:
- drop table flink_tab;
- create table flink_tab(
- user VARCHAR(100) NOT NULL,
- clicks INT NOT NULL,
- PRIMARY KEY (user)
- );
- DELIMITER ;;
- create trigger flink_tab_trigger_insert after insert
- on flink_tab for each row
- begin
- select user, clicks from flink_tab into OUTFILE '/tmp/trigger.sql';
- end ;;
- DELIMITER ;
- DELIMITER ;;
- create trigger flink_tab_trigger_ after update
- on flink_tab for each row
- begin
- select ts, user, clicks from flink_tab into OUTFILE '/tmp/trigger.sql';
- end ;;
- DELIMITER ;
同樣我做如下6次DML操作,Trigger 6次查詢計算:
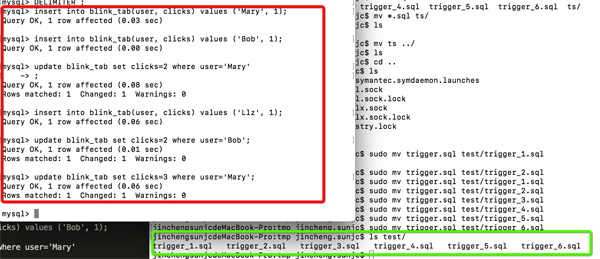
在來看看這次的結果與append only 有什么不同?

我想大家早就知道這結果了,數據庫里面定義的PK所有變化會按PK更新,那么觸發的6次計算中也會得到更新后的結果,這應該不難理解,查詢結果也是不斷更新的(Update)!
3. 關系定義
上面Append Only 和 Update兩種場景在MySQL上面都可以利用Trigger機制模擬 持續查詢的概念,也就是說數據表中每次數據變化,我們都觸發一次相同的查詢計算(只是計算時候數據的集合發生了變化),因為數據表不斷的變化,這個表就可以看做是一個動態表Dynamic Table,而查詢SQL(select * from flink_tab_ts) 被觸發器Trigger在滿足某種條件后不停的觸發計算,進而也不斷地產生新的結果。這種作用在Dynamic Table,并且有某種機制(Trigger)不斷的觸發計算的查詢我們就稱之為 持續查詢。
那么到底靜態查詢和動態查詢的關系是什么呢?在語義上 持續查詢 中的每一次查詢計算的觸發都是一次靜態查詢(相對于當時查詢的時間點), 在實現上 Apache Flink會利用上一次查詢結果+當前記錄 以增量的方式完成查詢計算。
特別說明: 上面我們利用 數據變化+Trigger方式描述了持續查詢的概念,這里有必要特別強調一下的是數據庫中trigger機制觸發的查詢,每次都是一個全量查詢,這與Apache Flink上面流計算的持續查詢概念相同,但實現機制完全不同,Apache Flink上面的持續查詢內部實現是增量處理的,隨著時間的推移,每條數據的到來實時處理當前的那一條記錄,不會處理曾經來過的歷史記錄!
七、Apache Flink 如何做到持續查詢
1. 動態表上面持續查詢
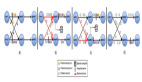
在 《Apache Flink 漫談系列 - 流表對偶(duality)性》 中我們了解到流和表可以相互轉換,在Apache Flink流計算中攜帶流事件的Schema,經過算子計算之后再產生具有新的Schema的事件,流入下游節點,在產生新的Schema的Event和不斷流轉的過程就是持續查詢作用的結果,如下圖:

2. 增量計算
我們進行查詢大多數場景是進行數據聚合,比如查詢SQL中利用count,sum等aggregate function進行聚合統計,那么流上的數據源源不斷的流入,我們既不能等所有事件流入結束(永遠不會結束)再計算,也不會每次來一條事件就像傳統數據庫一樣將全部事件集合重新整體計算一次,在持續查詢的計算過程中,Apache Flink采用增量計算的方式,也就是每次計算都會將計算結果存儲到state中,下一條事件到來的時候利用上次計算的結果和當前的事件進行聚合計算,比如 有一個訂單表,如下:
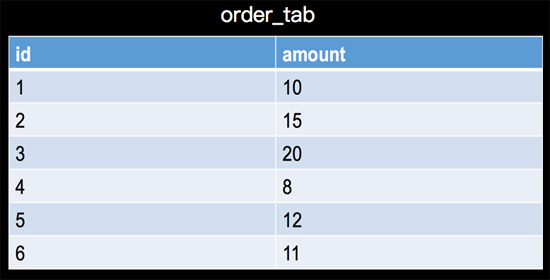
一個簡單的計數和求和查詢SQL:
- // 求訂單總數和所有訂單的總金額
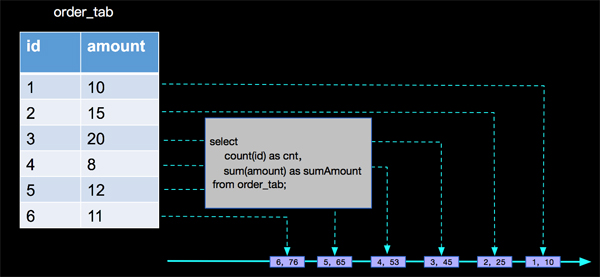
- select count(id) as cnt,sum(amount)as sumAmount from order_tab;
這樣一個簡單的持續查詢計算,Apache Flink內部是如何處理的呢?如下圖:

如上圖,Apache Flink中每來一條事件,就進行一次計算,并且每次計算后結果會存儲到state中,供下一條事件到來時候進行計算,即:
- result(n) = calculation(result(n-1), n)。
3. 無PK的Append Only 場景
在實際的業務場景中,我們只需要進行簡單的數據統計,然后就將統計結果寫入到業務的數據存儲系統里面,比如上面統計訂單數量和總金額的場景,訂單表本身是一個append only的數據源(假設沒有更新,截止到2018.5.14日,Apache Flink內部支持的數據源都是append only的),在持續查詢過程中經過count(id),sum(amount)統計計算之后產生的動態表也是append only的,種場景Apache Flink內部只需要進行aggregate function的聚合統計計算就可以,如下:
4. 有PK的Update 場景
現在我們將上面的訂單場景稍微變化一下,在數據表上面我們將金額字段amount,變為地區字段region,數據如下:
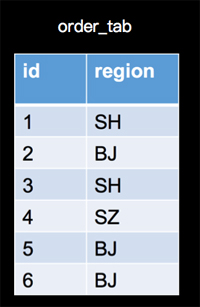
查詢統計的變為,在計算具有相同訂單數量的地區數量;查詢SQL如下:
- CREATE TABLE order_tab(
- id BIGINT,
- region VARCHAR
- )
- CREATE TABLE region_count_sink(
- order_cnt BIGINT,
- region_cnt BIGINT,
- PRIMARY KEY(order_cnt) -- 主鍵
- )
- -- 按地區分組計算每個地區的訂單數量
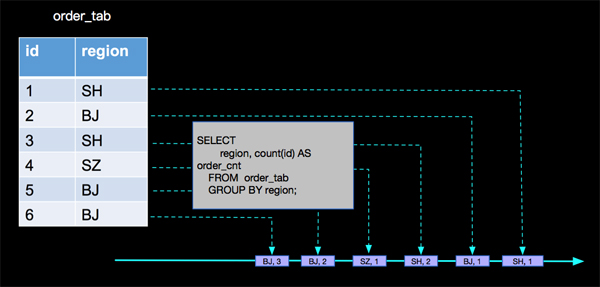
- CREATE VIEW order_count_view AS
- SELECT
- region, count(id) AS order_cnt
- FROM order_tab
- GROUP BY region;
- -- 按訂單數量分組統計具有相同訂單數量的地區數量
- INSERT INTO region_count_sink
- SELECT
- order_cnt,
- count(region) as region_cnt
- FROM order_count_view
- GROUP BY order_cnt;
上面查詢SQL的代碼結構如下(這個圖示在Alibaba 對 Apache Flink 的增強的集成IDE環境生成的,了解更多):

上面SQL中我們發現有兩層查詢計算邏輯,***個查詢計算邏輯是與SOURCE相連的按地區統計訂單數量的分組統計,第二個查詢計算邏輯是在***個查詢產出的動態表上面進行按訂單數量統計地區數量的分組統計,我們一層一層分析。
5. 錯誤處理
- ***層分析:SELECT region, count(id) AS order_cnt FROM order_tab GROUP BY region;
- 第二層分析:SELECT order_cnt, count(region) as region_cnt FROM order_count_view GROUP BY order_cnt;
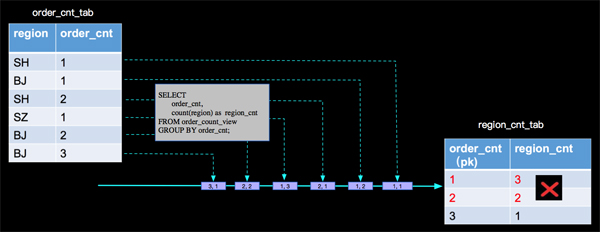
按照***層分析的結果,再分析第二層產出的結果,我們分析的過程是對的,但是最終寫到sink表的計算結果是錯誤的,那我們錯在哪里了呢?
其實當 (SH,2)這條記錄來的時候,以前來過的(SH, 1)已經是臟數據了,當(BJ, 2)來的時候,已經參與過計算的(BJ, 1)也變成臟數據了,同樣當(BJ, 3)來的時候,(BJ, 2)也是臟數據了,上面的分析,沒有處理臟數據進而導致最終結果的錯誤。那么Apache Flink內部是如何正確處理的呢?
6. 正確處理
- ***層分析:SELECT region, count(id) AS order_cnt FROM order_tab GROUP BY region;
- 第二層分析:SELECT order_cnt, count(region) as region_cnt FROM order_count_view GROUP BY order_cnt;
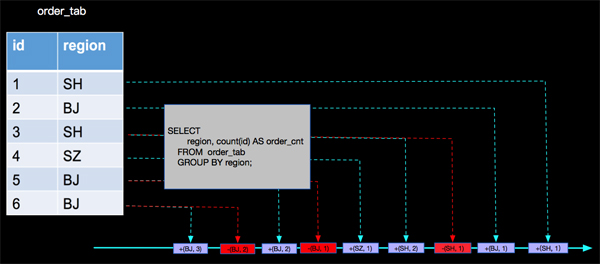
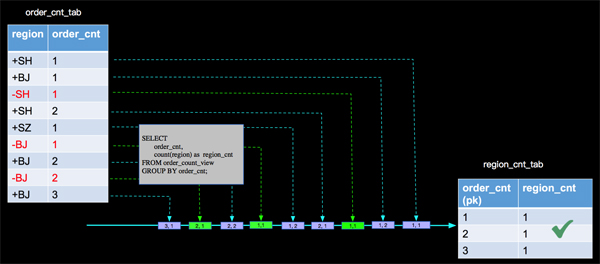
上面我們將有更新的事件進行打標的方式來處理臟數據,這樣在Apache Flink內部計算的時候 算子會根據事件的打標來處理事件,在aggregate function中有兩個對應的方法(retract和accumulate)來處理不同標識的事件,如上面用到的count AGG,內部實現如下:
- def accumulate(acc: CountAccumulator): Unit = {
- acc.f0 += 1L // acc.f0 存儲記數
- }
- def retract(acc: CountAccumulator, value: Any): Unit = {
- if (value != null) {
- acc.f0 -= 1L //acc.f0 存儲記數
- }}
Apache Flink內部這種為事件進行打標的機制叫做 retraction。retraction機制保障了在流上已經流轉到下游的臟數據需要被撤回問題,進而保障了持續查詢的正確語義。
八、Apache Flink Connector 類型
本篇一開始就對比了MySQL的數據存儲和Apache Flink數據存儲的區別,Apache Flink目前是一個計算平臺,將數據的存儲以高度抽象的插件機制與各種已有的數據存儲無縫對接。目前Apache Flink中將數據插件稱之為鏈接器Connector,Connnector又按數據的讀和寫分成Soruce(讀)和Sink(寫)兩種類型。對于傳統數據庫表,PK是一個很重要的屬性,在頻繁的按某些字段(PK)進行更新的場景,在表上定義PK非常重要。那么作為完全支持ANSI-SQL的Apache Flink平臺在Connector上面是否也支持PK的定義呢?
1. Apache Flink Source
現在(2018.11.***pache Flink中用于數據流驅動的Source Connector上面無法定義PK,這樣在某些業務場景下會造成數據量較大,造成計算資源不必要的浪費,甚至有聚合結果不是用戶“期望”的情況。我們以雙流JOIN為例來說明:
- SQL:
- CREATE TABLE inventory_tab(
- product_id VARCHAR,
- product_count BIGINT
- );
- CREATE TABLE sales_tab(
- product_id VARCHAR,
- sales_count BIGINT
- ) ;
- CREATE TABLE join_sink(
- product_id VARCHAR,
- product_count BIGINT,
- sales_count BIGINT,
- PRIMARY KEY(product_id)
- );
- CREATE VIEW join_view AS
- SELECT
- l.product_id,
- l.product_count,
- r.sales_count
- FROM inventory_tab l
- JOIN sales_tab r
- ON l.product_id = r.product_id;
- INSERT INTO join_sink
- SELECT
- product_id,
- product_count,
- sales_count
- FROM join_view ;
代碼結構圖:
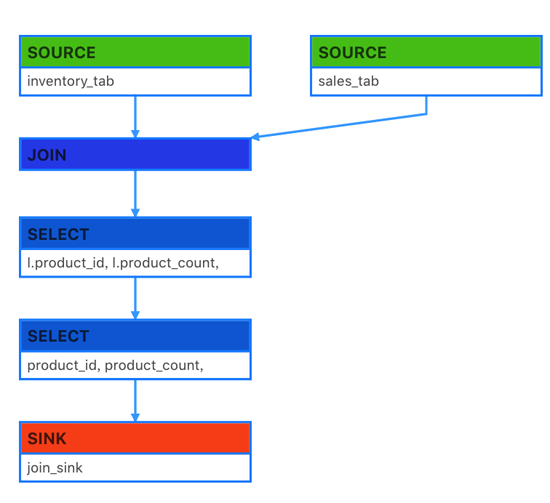
實現示意圖:

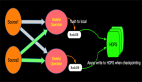
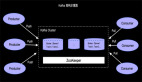
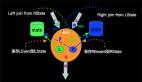
上圖描述了一個雙流JOIN的場景,雙流JOIN的底層實現會將左(L)右(R)兩面的數據都持久化到Apache Flink的State中,當L流入一條事件,首先會持久化到LState,然后在和RState中存儲的R中所有事件進行條件匹配,這樣的邏輯如果R流product_id為P001的產品銷售記錄已經流入4條,L流的(P001, 48) 流入的時候會匹配4條事件流入下游(join_sink)。
2. 問題
上面雙流JOIN的場景,我們發現其實inventory和sales表是有業務的PK的,也就是兩張表上面的product_id是唯一的,但是由于我們在Sorure上面無法定義PK字段,表上面所有的數據都會以append only的方式從source流入到下游計算節點JOIN,這樣就導致了JOIN內部所有product_id相同的記錄都會被匹配流入下游,上面的例子是 (P001, 48) 來到的時候,就向下游流入了4條記錄,不難想象每個product_id相同的記錄都會與歷史上所有事件進行匹配,進而操作下游數據壓力。
那么這樣的壓力是必要的嗎?從業務的角度看,不是必要的,因為對于product_id相同的記錄,我們只需要對左右兩邊***的記錄進行JOIN匹配就可以了。比如(P001, 48)到來了,業務上面只需要右流的(P001, 22)匹配就好,流入下游一條事件(P001, 48, 22)。 那么目前在Apache Flink上面如何做到這樣的優化呢?
3. 解決方案
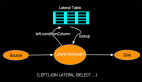
上面的問題根本上我們要構建一張有PK的動態表,這樣按照業務PK進行更新處理,我們可以在Source后面添加group by 操作生產一張有PK的動態表。如下:
- SQL:
- CREATE TABLE inventory_tab(
- product_id VARCHAR,
- product_count BIGINT
- )
- CREATE TABLE sales_tab(
- product_id VARCHAR,
- sales_count BIGINT
- )
- CREATE VIEW inventory_view AS
- SELECT
- product_id,
- LAST_VALUE(product_count) AS product_count
- FROM inventory_tab
- GROUP BY product_id;
- CREATE VIEW sales_view AS
- SELECT
- product_id,
- LAST_VALUE(sales_count) AS sales_count
- FROM sales_tab
- GROUP BY product_id;
- CREATE TABLE join_sink(
- product_id VARCHAR,
- product_count BIGINT,
- sales_count BIGINT,
- PRIMARY KEY(product_id)
- )WITH (
- type = 'print'
- ) ;
- CREATE VIEW join_view AS
- SELECT
- l.product_id,
- l.product_count,
- r.sales_count
- FROM inventory_view l
- JOIN sales_view r
- ON l.product_id = r.product_id;
- INSERT INTO join_sink
- SELECT
- product_id,
- product_count,
- sales_count
- FROM join_view ;
代碼結構:
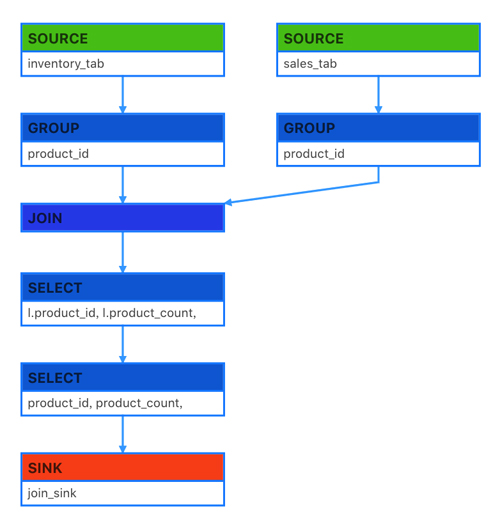
示意圖:

如上方式可以將無PK的source經過一次節點變成有PK的動態表,以Apache Flink的retract機制和業務要素解決數據瓶頸,減少計算資源的消耗。
說明1: 上面方案LAST_VALUE是Alibaba對 Apache Flink 的增強的功能,社區還沒有支持。
4. Apache Flink Sink
在Apache Flink上面可以根據實際外部存儲的特點(是否支持PK),以及整體job的執行plan來動態推導Sink的執行模式,具體有如下三種類型:
Append 模式 - 該模式用戶在定義Sink的DDL時候不定義PK,在Apache Flink內部生成的所有只有INSERT語句;
Upsert 模式 - 該模式用戶在定義Sink的DDL時候可以定義PK,在Apache Flink內部會根據事件打標(retract機制)生成INSERT/UPDATE和DELETE 語句,其中如果定義了PK, UPDATE語句按PK進行更新,如果沒有定義PK UPDATE會按整行更新;
Retract 模式 - 該模式下會產生INSERT和DELETE兩種信息,Sink Connector 根據這兩種信息構造對應的數據操作指令;
九、小結
本篇以MySQL為例介紹了傳統數據庫的靜態查詢和利用MySQL的Trigger+DML操作來模擬持續查詢,并介紹了Apache Flink上面利用增量模式完成持續查詢,并以雙流JOIN為例說明了持續查詢可能會遇到的問題,并且介紹Apache Flink以為事件打標產生delete事件的方式解決持續查詢的問題,進而保證語義的正確性,***的在流計算上支持續查詢。
# 關于點贊和評論
本系列文章難免有很多缺陷和不足,真誠希望讀者對有收獲的篇章給予點贊鼓勵,對有不足的篇章給予反饋和建議,先行感謝大家!
作者:孫金城,花名 金竹,目前就職于阿里巴巴,自2015年以來一直投入于基于Apache Flink的阿里巴巴計算平臺Blink的設計研發工作。
【本文為51CTO專欄作者“金竹”原創稿件,轉載請聯系原作者】