Apache Flink 漫談系列(15) - DataStream Connectors之Kafka
一、聊什么
為了滿足本系列讀者的需求,我先介紹一下Kafka在Apache Flink中的使用。所以本篇以一個簡單的示例,向大家介紹在Apache Flink中如何使用Kafka。
二、Kafka 簡介
Apache Kafka是一個分布式發布-訂閱消息傳遞系統。 它最初由LinkedIn公司開發,LinkedIn于2010年貢獻給了Apache基金會并成為***開源項目。Kafka用于構建實時數據管道和流式應用程序。它具有水平擴展性、容錯性、極快的速度,目前也得到了廣泛的應用。
Kafka不但是分布式消息系統而且也支持流式計算,所以在介紹Kafka在Apache Flink中的應用之前,先以一個Kafka的簡單示例直觀了解什么是Kafka。
1. 安裝
本篇不是系統的,詳盡的介紹Kafka,而是想讓大家直觀認識Kafka,以便在Apahe Flink中進行很好的應用,所以我們以最簡單的方式安裝Kafka。
(1) 下載二進制包:
- curl -L -O http://mirrors.shu.edu.cn/apache/kafka/2.1.0/kafka_2.11-2.1.0.tgz
(2) 解壓安裝
Kafka安裝只需要將下載的tgz解壓即可,如下:
- jincheng:kafka jincheng.sunjc$ tar -zxf kafka_2.11-2.1.0.tgz
- jincheng:kafka jincheng.sunjc$ cd kafka_2.11-2.1.0
- jincheng:kafka_2.11-2.1.0 jincheng.sunjc$ ls
- LICENSE NOTICE bin config libs site-docs
其中bin包含了所有Kafka的管理命令,如接下來我們要啟動的Kafka的Server。
(3) 啟動Kafka Server
Kafka是一個發布訂閱系統,消息訂閱首先要有個服務存在。我們啟動一個Kafka Server 實例。 Kafka需要使用ZooKeeper,要進行投產部署我們需要安裝ZooKeeper集群,這不在本篇的介紹范圍內,所以我們利用Kafka提供的腳本,安裝一個只有一個節點的ZooKeeper實例。如下:
- jincheng:kafka_2.11-2.1.0 jincheng.sunjc$ bin/zookeeper-server-start.sh config/zookeeper.properties &
- [2019-01-13 09:06:19,985] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
- ....
- ....
- [2019-01-13 09:06:20,061] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
啟動之后,ZooKeeper會綁定2181端口(默認)。接下來我們啟動Kafka Server,如下:
- jincheng:kafka_2.11-2.1.0 jincheng.sunjc$ bin/kafka-server-start.sh config/server.properties
- [2019-01-13 09:09:16,937] INFO Registered kafkakafka:type=kafka.Log4jController MBean (kafka.utils.Log4jControllerRegistration$)
- [2019-01-13 09:09:17,267] INFO starting (kafka.server.KafkaServer)
- [2019-01-13 09:09:17,267] INFO Connecting to zookeeper on localhost:2181 (kafka.server.KafkaServer)
- [2019-01-13 09:09:17,284] INFO [ZooKeeperClient] Initializing a new session to localhost:2181. (kafka.zookeeper.ZooKeeperClient)
- ...
- ...
- [2019-01-13 09:09:18,253] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
如果上面一切順利,Kafka的安裝就完成了。
2. 創建Topic
Kafka是消息訂閱系統,首先創建可以被訂閱的Topic,我們創建一個名為flink-tipic的Topic,在一個新的terminal中,執行如下命令:
- jincheng:kafka_2.11-2.1.0 jincheng.sunjc$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flink-tipic
- Created topic "flink-tipic".
在Kafka Server的terminal中也會輸出如下成功創建信息:
- ...
- [2019-01-13 09:13:31,156] INFO Created log for partition flink-tipic-0 in /tmp/kafka-logs with properties {compression.type -> producer, message.format.version -> 2.1-IV2, file.delete.delay.ms -> 60000, max.message.bytes -> 1000012, min.compaction.lag.ms -> 0, message.timestamp.type -> CreateTime, message.downconversion.enable -> true, min.insync.replicas -> 1, segment.jitter.ms -> 0, preallocate -> false, min.cleanable.dirty.ratio -> 0.5, index.interval.bytes -> 4096, unclean.leader.election.enable -> false, retention.bytes -> -1, delete.retention.ms -> 86400000, cleanup.policy -> [delete], flush.ms -> 9223372036854775807, segment.ms -> 604800000, segment.bytes -> 1073741824, retention.ms -> 604800000, message.timestamp.difference.max.ms -> 9223372036854775807, segment.index.bytes -> 10485760, flush.messages -> 9223372036854775807}. (kafka.log.LogManager)...
上面顯示了flink-topic的基本屬性配置,如消息壓縮方式,消息格式,備份數量等等。
除了看日志,我們可以用命令顯示的查詢我們是否成功的創建了flink-topic,如下:
- jincheng:kafka_2.11-2.1.0 jincheng.sunjc$ bin/kafka-topics.sh --list --zookeeper localhost:2181
- flink-tipic
如果輸出flink-tipic那么說明我們的Topic成功創建了。
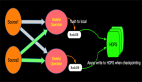
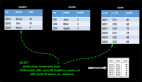
那么Topic是保存在哪里?Kafka是怎樣進行消息的發布和訂閱的呢?為了直觀,我們看如下Kafka架構示意圖簡單理解一下:
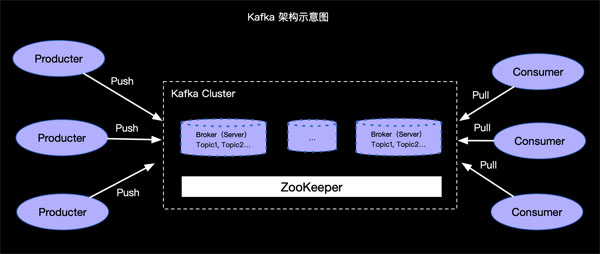
簡單介紹一下,Kafka利用ZooKeeper來存儲集群信息,也就是上面我們啟動的Kafka Server 實例,一個集群中可以有多個Kafka Server 實例,Kafka Server叫做Broker,我們創建的Topic可以在一個或多個Broker中。Kafka利用Push模式發送消息,利用Pull方式拉取消息。
3. 發送消息
如何向已經存在的Topic中發送消息呢,當然我們可以API的方式編寫代碼發送消息。同時,還可以利用命令方式來便捷的發送消息,如下:
- jincheng:kafka_2.11-2.1.0 jincheng.sunjc$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic flink-topic
- >Kafka test msg
- >Kafka connector
上面我們發送了兩條消息Kafka test msg 和 Kafka connector 到 flink-topic Topic中。
4. 讀取消息
如果讀取指定Topic的消息呢?同樣可以API和命令兩種方式都可以完成,我們以命令方式讀取flink-topic的消息,如下:
- jincheng:kafka_2.11-2.1.0 jincheng.sunjc$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic flink-topic --from-beginning
- Kafka test msg
- Kafka connector
其中--from-beginning 描述了我們從Topic開始位置讀取消息。
三、Flink Kafka Connector
前面我們以最簡單的方式安裝了Kafka環境,那么我們以上面的環境介紹Flink Kafka Connector的使用。Flink Connector相關的基礎知識會在《Apache Flink 漫談系列(14) - Connectors》中介紹,這里我們直接介紹與Kafka Connector相關的內容。
Apache Flink 中提供了多個版本的Kafka Connector,本篇以flink-1.7.0版本為例進行介紹。
1. mvn 依賴
要使用Kakfa Connector需要在我們的pom中增加對Kafka Connector的依賴,如下:
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-kafka_2.11</artifactId>
- <version>1.7.0</version>
- </dependency>
Flink Kafka Consumer需要知道如何將Kafka中的二進制數據轉換為Java / Scala對象。 DeserializationSchema允許用戶指定這樣的模式。 為每個Kafka消息調用 T deserialize(byte [] message)方法,從Kafka傳遞值。
2. Examples
我們示例讀取Kafka的數據,再將數據做簡單處理之后寫入到Kafka中。我們需要再創建一個用于寫入的Topic,如下:
- bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic flink-tipic-output
所以示例中我們Source利用flink-topic, Sink用slink-topic-output。
(1) Simple ETL
我們假設Kafka中存儲的就是一個簡單的字符串,所以我們需要一個用于對字符串進行serialize和deserialize的實現,也就是我們要定義一個實現DeserializationSchema和SerializationSchema 的序列化和反序列化的類。因為我們示例中是字符串,所以我們自定義一個KafkaMsgSchema實現類,然后在編寫Flink主程序。
- KafkaMsgSchema - 完整代碼
- import org.apache.flink.api.common.serialization.DeserializationSchema;
- import org.apache.flink.api.common.serialization.SerializationSchema;
- import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
- import org.apache.flink.api.common.typeinfo.TypeInformation;
- import org.apache.flink.util.Preconditions;
- import java.io.IOException;
- import java.io.ObjectInputStream;
- import java.io.ObjectOutputStream;
- import java.nio.charset.Charset;
- public class KafkaMsgSchema implements DeserializationSchema<String>, SerializationSchema<String> {
- private static final long serialVersionUID = 1L;
- private transient Charset charset;
- public KafkaMsgSchema() {
- // 默認UTF-8編碼
- this(Charset.forName("UTF-8"));
- }
- public KafkaMsgSchema(Charset charset) {
- this.charset = Preconditions.checkNotNull(charset);
- }
- public Charset getCharset() {
- return this.charset;
- }
- public String deserialize(byte[] message) {
- // 將Kafka的消息反序列化為java對象
- return new String(message, charset);
- }
- public boolean isEndOfStream(String nextElement) {
- // 流永遠不結束
- return false;
- }
- public byte[] serialize(String element) {
- // 將java對象序列化為Kafka的消息
- return element.getBytes(this.charset);
- }
- public TypeInformation<String> getProducedType() {
- // 定義產生的數據Typeinfo
- return BasicTypeInfo.STRING_TYPE_INFO;
- }
- private void writeObject(ObjectOutputStream out) throws IOException {
- out.defaultWriteObject();
- out.writeUTF(this.charset.name());
- }
- private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
- in.defaultReadObject();
- String charsetName = in.readUTF();
- this.charset = Charset.forName(charsetName);
- }
- }
- import org.apache.flink.api.common.functions.MapFunction;
- import org.apache.flink.api.java.utils.ParameterTool;
- import org.apache.flink.streaming.api.datastream.DataStream;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
- import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
- import org.apache.flink.streaming.util.serialization.KeyedSerializationSchemaWrapper;
- import java.util.Properties;
- public class KafkaExample {
- public static void main(String[] args) throws Exception {
- // 用戶參數獲取
- final ParameterTool parameterTool = ParameterTool.fromArgs(args);
- // Stream 環境
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- // Source的topic
- String sourceTopic = "flink-topic";
- // Sink的topic
- String sinkTopic = "flink-topic-output";
- // broker 地址
- String broker = "localhost:9092";
- // 屬性參數 - 實際投產可以在命令行傳入
- Properties p = parameterTool.getProperties();
- p.putAll(parameterTool.getProperties());
- p.put("bootstrap.servers", broker);
- env.getConfig().setGlobalJobParameters(parameterTool);
- // 創建消費者
- FlinkKafkaConsumer consumer = new FlinkKafkaConsumer<String>(
- sourceTopic,
- new KafkaMsgSchema(),
- p);
- // 設置讀取最早的數據
- // consumer.setStartFromEarliest();
- // 讀取Kafka消息
- DataStream<String> input = env.addSource(consumer);
- // 數據處理
- DataStream<String> result = input.map(new MapFunction<String, String>() {
- public String map(String s) throws Exception {
- String msg = "Flink study ".concat(s);
- System.out.println(msg);
- return msg;
- }
- });
- // 創建生產者
- FlinkKafkaProducer producer = new FlinkKafkaProducer<String>(
- sinkTopic,
- new KeyedSerializationSchemaWrapper<String>(new KafkaMsgSchema()),
- p,
- FlinkKafkaProducer.Semantic.AT_LEAST_ONCE);
- // 將數據寫入Kafka指定Topic中
- result.addSink(producer);
- // 執行job
- env.execute("Kafka Example");
- }
- }
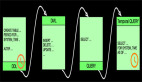
運行主程序如下:
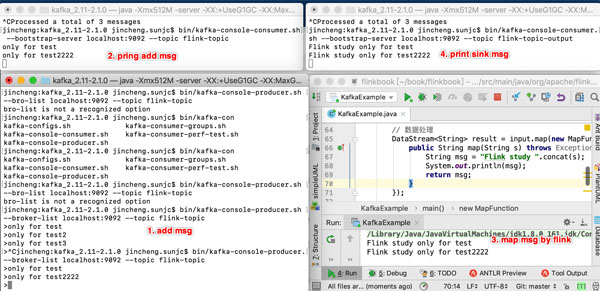
我測試操作的過程如下:
- 啟動flink-topic和flink-topic-output的消費拉取;
- 通過命令向flink-topic中添加測試消息only for test;
- 通過命令打印驗證添加的測試消息 only for test;
- 最簡單的FlinkJob source->map->sink 對測試消息進行map處理:"Flink study ".concat(s);
- 通過命令打印sink的數據;
(2) 內置Schemas
Apache Flink 內部提供了如下3種內置的常用消息格式的Schemas:
- TypeInformationSerializationSchema (and TypeInformationKeyValueSerializationSchema) 它基于Flink的TypeInformation創建模式。 如果數據由Flink寫入和讀取,這將非常有用。
- JsonDeserializationSchema (and JSONKeyValueDeserializationSchema) 它將序列化的JSON轉換為ObjectNode對象,可以使用objectNode.get(“field”)作為(Int / String / ...)()從中訪問字段。 KeyValue objectNode包含“key”和“value”字段,其中包含所有字段以及可選的"metadata"字段,該字段公開此消息的偏移量/分區/主題。
- AvroDeserializationSchema 它使用靜態提供的模式讀取使用Avro格式序列化的數據。 它可以從Avro生成的類(AvroDeserializationSchema.forSpecific(...))推斷出模式,或者它可以與GenericRecords一起使用手動提供的模式(使用AvroDeserializationSchema.forGeneric(...))
要使用內置的Schemas需要添加如下依賴:
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-avro</artifactId>
- <version>1.7.0</version>
- </dependency>
(3) 讀取位置配置
我們在消費Kafka數據時候,可能需要指定消費的位置,Apache Flink 的FlinkKafkaConsumer提供很多便利的位置設置,如下:
- consumer.setStartFromEarliest() - 從最早的記錄開始;
- consumer.setStartFromLatest() - 從***記錄開始;
- consumer.setStartFromTimestamp(...); // 從指定的epoch時間戳(毫秒)開始;
- consumer.setStartFromGroupOffsets(); // 默認行為,從上次消費的偏移量進行繼續消費。
上面的位置指定可以精確到每個分區,比如如下代碼:
- Map<KafkaTopicPartition, Long> specificStartOffsets = new HashMap<>();
- specificStartOffsets.put(new KafkaTopicPartition("myTopic", 0), 23L); // ***個分區從23L開始
- specificStartOffsets.put(new KafkaTopicPartition("myTopic", 1), 31L);// 第二個分區從31L開始
- specificStartOffsets.put(new KafkaTopicPartition("myTopic", 2), 43L);// 第三個分區從43L開始
- consumer.setStartFromSpecificOffsets(specificStartOffsets);
對于沒有指定的分區還是默認的setStartFromGroupOffsets方式。
(4) Topic發現
Kafka支持Topic自動發現,也就是用正則的方式創建FlinkKafkaConsumer,比如:
- // 創建消費者
- FlinkKafkaConsumer consumer = new FlinkKafkaConsumer<String>( java.util.regex.Pattern.compile(sourceTopic.concat("-[0-9]")),
- new KafkaMsgSchema(),
- p);
在上面的示例中,當作業開始運行時,消費者將訂閱名稱與指定正則表達式匹配的所有Topic(以sourceTopic的值開頭并以單個數字結尾)。
3. 定義Watermark(Window)
對Kafka Connector的應用不僅限于上面的簡單數據提取,我們更多時候是期望對Kafka數據進行Event-time的窗口操作,那么就需要在Flink Kafka Source中定義Watermark。
要定義Event-time,首先是Kafka數據里面攜帶時間屬性,假設我們數據是String#Long的格式,如only for test#1000。那么我們將Long作為時間列。
- KafkaWithTsMsgSchema - 完整代碼
要想解析上面的Kafka的數據格式,我們需要開發一個自定義的Schema,比如叫KafkaWithTsMsgSchema,將String#Long解析為一個Java的Tuple2
- import org.apache.flink.api.common.serialization.DeserializationSchema;
- import org.apache.flink.api.common.serialization.SerializationSchema;
- import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
- import org.apache.flink.api.common.typeinfo.TypeInformation;
- import org.apache.flink.api.java.tuple.Tuple2;
- import org.apache.flink.api.java.typeutils.TupleTypeInfo;
- import org.apache.flink.util.Preconditions;
- import java.io.IOException;
- import java.io.ObjectInputStream;
- import java.io.ObjectOutputStream;
- import java.nio.charset.Charset;
- public class KafkaWithTsMsgSchema implements DeserializationSchema<Tuple2<String, Long>>, SerializationSchema<Tuple2<String, Long>> {
- private static final long serialVersionUID = 1L;
- private transient Charset charset;
- public KafkaWithTsMsgSchema() {
- this(Charset.forName("UTF-8"));
- }
- public KafkaWithTsMsgSchema(Charset charset) {
- this.charset = Preconditions.checkNotNull(charset);
- }
- public Charset getCharset() {
- return this.charset;
- }
- public Tuple2<String, Long> deserialize(byte[] message) {
- String msg = new String(message, charset);
- String[] dataAndTs = msg.split("#");
- if(dataAndTs.length == 2){
- return new Tuple2<String, Long>(dataAndTs[0], Long.parseLong(dataAndTs[1].trim()));
- }else{
- // 實際生產上需要拋出runtime異常
- System.out.println("Fail due to invalid msg format.. ["+msg+"]");
- return new Tuple2<String, Long>(msg, 0L);
- }
- }
- @Override
- public boolean isEndOfStream(Tuple2<String, Long> stringLongTuple2) {
- return false;
- }
- public byte[] serialize(Tuple2<String, Long> element) {
- return "MAX - ".concat(element.f0).concat("#").concat(String.valueOf(element.f1)).getBytes(this.charset);
- }
- private void writeObject(ObjectOutputStream out) throws IOException {
- out.defaultWriteObject();
- out.writeUTF(this.charset.name());
- }
- private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
- in.defaultReadObject();
- String charsetName = in.readUTF();
- this.charset = Charset.forName(charsetName);
- }
- @Override
- public TypeInformation<Tuple2<String, Long>> getProducedType() {
- return new TupleTypeInfo<Tuple2<String, Long>>(BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.LONG_TYPE_INFO);
- }}
- Watermark生成
提取時間戳和創建Watermark,需要實現一個自定義的時間提取和Watermark生成器。在Apache Flink 內部有2種方式如下:
- AssignerWithPunctuatedWatermarks - 每條記錄都產生Watermark。
- AssignerWithPeriodicWatermarks - 周期性的生成Watermark。
我們以AssignerWithPunctuatedWatermarks為例寫一個自定義的時間提取和Watermark生成器。代碼如下:
- import org.apache.flink.api.java.tuple.Tuple2;
- import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks;
- import org.apache.flink.streaming.api.watermark.Watermark;
- import javax.annotation.Nullable;
- public class KafkaAssignerWithPunctuatedWatermarks
- implements AssignerWithPunctuatedWatermarks<Tuple2<String, Long>> {
- @Nullable
- @Override
- public Watermark checkAndGetNextWatermark(Tuple2<String, Long> o, long l) {
- // 利用提取的時間戳創建Watermark
- return new Watermark(l);
- }
- @Override
- public long extractTimestamp(Tuple2<String, Long> o, long l) {
- // 提取時間戳
- return o.f1;
- }}
主程序 - 完整程序
我們計算一個大小為1秒的Tumble窗口,計算窗口內***的值。完整的程序如下:
- import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
- import org.apache.flink.api.common.typeinfo.TypeInformation;
- import org.apache.flink.api.java.tuple.Tuple2;
- import org.apache.flink.api.java.typeutils.TupleTypeInfo;
- import org.apache.flink.api.java.utils.ParameterTool;
- import org.apache.flink.streaming.api.TimeCharacteristic;
- import org.apache.flink.streaming.api.datastream.DataStream;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
- import org.apache.flink.streaming.api.windowing.time.Time;
- import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
- import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
- import org.apache.flink.streaming.util.serialization.KeyedSerializationSchemaWrapper;
- import java.util.Properties;
- public class KafkaWithEventTimeExample {
- public static void main(String[] args) throws Exception {
- // 用戶參數獲取
- final ParameterTool parameterTool = ParameterTool.fromArgs(args);
- // Stream 環境
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- // 設置 Event-time
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
- // Source的topic
- String sourceTopic = "flink-topic";
- // Sink的topic
- String sinkTopic = "flink-topic-output";
- // broker 地址
- String broker = "localhost:9092";
- // 屬性參數 - 實際投產可以在命令行傳入
- Properties p = parameterTool.getProperties();
- p.putAll(parameterTool.getProperties());
- p.put("bootstrap.servers", broker);
- env.getConfig().setGlobalJobParameters(parameterTool);
- // 創建消費者
- FlinkKafkaConsumer consumer = new FlinkKafkaConsumer<Tuple2<String, Long>>(
- sourceTopic,
- new KafkaWithTsMsgSchema(),
- p);
- // 讀取Kafka消息
- TypeInformation<Tuple2<String, Long>> typeInformation = new TupleTypeInfo<Tuple2<String, Long>>(
- BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.LONG_TYPE_INFO);
- DataStream<Tuple2<String, Long>> input = env
- .addSource(consumer).returns(typeInformation)
- // 提取時間戳,并生產Watermark
- .assignTimestampsAndWatermarks(new KafkaAssignerWithPunctuatedWatermarks());
- // 數據處理
- DataStream<Tuple2<String, Long>> result = input
- .windowAll(TumblingEventTimeWindows.of(Time.seconds(1)))
- .max(0);
- // 創建生產者
- FlinkKafkaProducer producer = new FlinkKafkaProducer<Tuple2<String, Long>>(
- sinkTopic,
- new KeyedSerializationSchemaWrapper<Tuple2<String, Long>>(new KafkaWithTsMsgSchema()),
- p,
- FlinkKafkaProducer.Semantic.AT_LEAST_ONCE);
- // 將數據寫入Kafka指定Topic中
- result.addSink(producer);
- // 執行job
- env.execute("Kafka With Event-time Example");
- }}
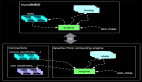
測試運行如下:
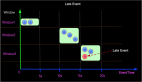
簡單解釋一下,我們輸入數如下:
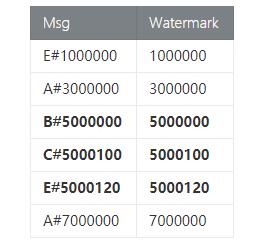
我們看的5000000~7000000之間的數據,其中B#5000000, C#5000100和E#5000120是同一個窗口的內容。計算MAX值,按字符串比較,***的消息就是輸出的E#5000120。
4. Kafka攜帶Timestamps
在Kafka-0.10+ 消息可以攜帶timestamps,也就是說不用單獨的在msg中顯示添加一個數據列作為timestamps。只有在寫入和讀取都用Flink時候簡單一些。一般情況用上面的示例方式已經足夠了。
四、小結
本篇重點是向大家介紹Kafka如何在Flink中進行應用,開篇介紹了Kafka的簡單安裝和收發消息的命令演示,然后以一個簡單的數據提取和一個Event-time的窗口示例讓大家直觀的感受如何在Apache Flink中使用Kafka。愿介紹的內容對您有所幫助!
關于點贊和評論
本系列文章難免有很多缺陷和不足,真誠希望讀者對有收獲的篇章給予點贊鼓勵,對有不足的篇章給予反饋和建議,先行感謝大家!
作者:孫金城,花名 金竹,目前就職于阿里巴巴,自2015年以來一直投入于基于Apache Flink的阿里巴巴計算平臺Blink的設計研發工作。
【本文為51CTO專欄作者“金竹”原創稿件,轉載請聯系原作者】