舍棄Python,為何知乎選用Go重構推薦系統?
知乎從問答起步,已逐步成長為一個大規模的綜合性知識內容平臺,截止目前,用戶數突破 2.2 億,有超過 3000 萬的問題被提出,并獲得超過 1.3 億個回答。同時,知乎內還沉淀了數量眾多的優質文章、電子書以及其它付費內容。

因此,在鏈接人與知識的路徑中,知乎存在著大量的推薦場景。粗略統計,目前除了首頁推薦之外,我們已存在著 20 多種推薦場景;并且在業務快速發展中,不斷有新的推薦業務需求加入。在這個背景之下,構建一個較通用的且便于業務接入的推薦系統就變成不得不做的事了。
重構推薦系統需要考慮哪些因素?如何做技術選型?重構的過程中會遇到哪些坑?希望知乎的踩坑經驗能給你帶來一些思考。
背景

在講通用架構的設計之前,我們一起回顧一下推薦系統的總體流程和架構。通常,因為模型所需特征及排序的性能考慮,我們通常將簡單的推薦系統分為召回層和 ranking 層,召回層主要負責從候選集合中粗排選擇待排序集合,之后獲取 ranking 特征,經過排序模型,挑選出推薦結果給用戶。
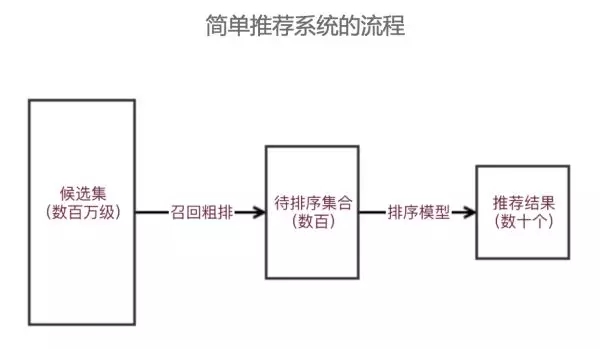
簡單推薦模型適合一些推薦結果要求單一,只對單目標負責的推薦場景,比如新聞詳情頁推薦、文章推薦等等。但在現實中,作為通用的推薦系統來說,其需要考慮用戶的多維度需求,比如用戶的多樣性需求、時效性需求、結果的滿足性需求等。因此就需要在推薦過程中采用多個不同隊列,針對不同需求進行排序,之后通過多隊列融合策略,從而滿足用戶不同的需求。
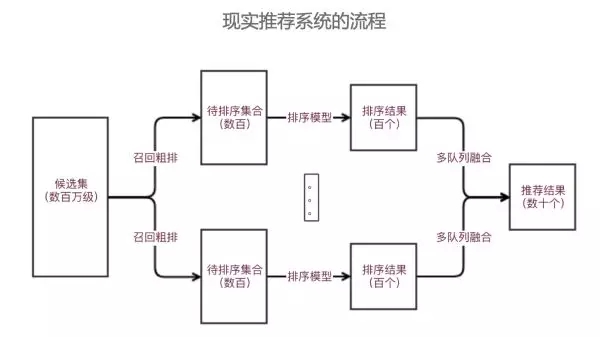
從我們知乎來說,也大體是這樣一個發展路線,比如今年的 7 月份時,因為一些業務快速發展且架構上相對獨立的歷史原因,我們的推薦系統存在多套,并且架構相對簡單。以其中一個推薦架構設計相對完善的系統為例,其總體架構是這樣的。可以看出,這個架構已經包含了召回層和 ranking 層,并且還考慮了二次排序。
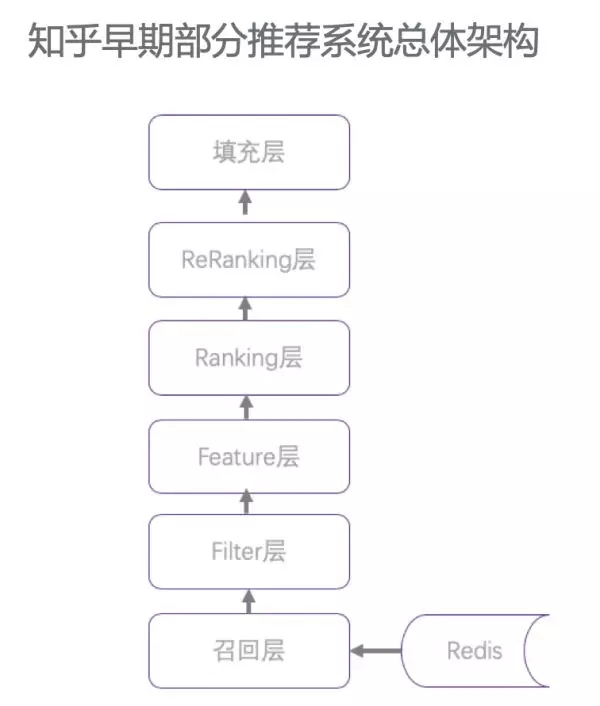
那么存在哪些問題呢?
首先,對多路召回支持不友好。現有架構的召回是耦合在一起的,因此開發調研成本高,多路召回接入相對困難。
然后,召回階段只使用 Redis 作為召回基礎。Redis 有很多優點,比如查詢效率高,服務較穩定。但將其作為所有召回層的基礎,就放大了其缺點,***不支持稍復雜的召回邏輯,第二無法進行大量結果的召回計算,第三不支持 embedding 的召回。
第三點,總體架構在實現時,架構邏輯剝離不夠干凈,使得架構抽樣邏輯較弱,各種通用特征和通用監控建設都較困難。
第四點,我們知道,在推薦系統中,特征日志的建設是非常重要的一個環節,它是推薦效果好壞的重要基礎之一。但現有推薦系統框架中,特征日志建設缺乏統一的校驗和落地方案,各業務『各顯神通』。
第五點,當前系統是不支持多隊列融合的,這就嚴重限制了通用架構的可擴展性和易用性。因此,我們就準備重構知乎的通用推薦服務框架。
重構之路
在重構前的考慮
***,語言的選擇。早期知乎大量的服務都是基于 Python 開發的,但在實踐過程中發現 Python 資源消耗過大、不利用多人協同開發等各種問題,之后公司進行了大規模的重構,現在知乎在語言層面的技術選型上比較開放,目前公司內部已有 Python、Scala、Java、Golang 等多種開發語言項目。那么對于推薦系統服務來說,由于其重計算,多并發的特點,語言的選擇還是需要考慮的。
第二,架構上的考慮,要解決支持多隊列混排和支持多路召回的問題,并且其設計***是支持可插拔的。
第三,召回層上,除了傳統的 Redis 的 kv 召回(部分 cf 召回,熱門召回等等應用場景),我們還需要考慮一些其他索引數據庫,以便支持更多索引類型。
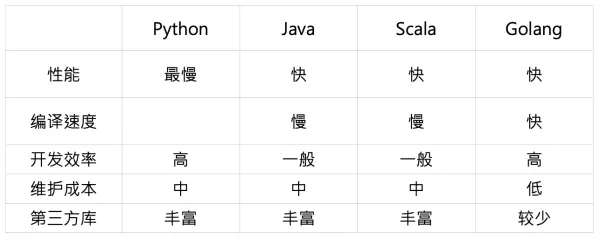
首先我們先看語言上的選擇,先總體上比較一下各種語言的特點,我們簡單從如下幾個方面進行比較。
從性能上,依照公開的 benchmark,Golang 和 Java、Scala 大概在一個量級,是 Python 的 30 倍左右。其次 Golang 的編譯速度較快,這點相對于 Java、Scala 具有比較明顯的優勢,再次其語言特性決定了 Golang 的開發效率較高,此外因為缺乏 trycatch 機制,使得使用 Golang 開發時對異常處理思考較多,因此其上線之后維護成本相對較低。但 Golang 有個明顯缺陷就是目前第三方庫較少,特別跟 AI 相關的庫。
那么基于以上優缺點,我們重構為什么選擇 Golang?
1、Golang 天然的優勢,支持高并發并且占用資源相對較少。這個優勢恰恰是推薦系統所需要的,推薦系統存在大量需要高并發的場景,比如多路召回,特征計算等等。
2、知乎內部基礎組件的 Golang 版生態比較完善。目前我們知乎內部對于 Golang 的使用越來越積極,大量基礎組件都已經 Golang 化,包括基礎監控組件等等,這也是我們選擇 Golang 的重要原因。
但我需要強調一點,語言的選擇不是只有唯一答案的,這是跟公司技術和業務場景結合的選擇。
講完語言上的選擇,那么為了在重構時支持多隊列混排和支持多路召回,我們架構上是如何來解決的?
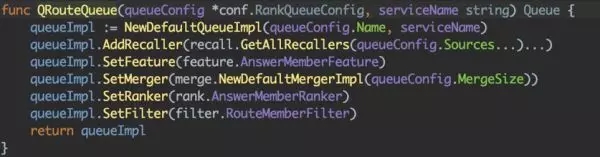
這點在設計模式比較常見,就是『抽象工廠模式』:首先我們構建隊列注冊管理器,將回調注冊一個 map 中,并將當前服務所有隊列做成 json 配置的可自由插拔的模式,比如如下配置,指定一個服務所需要的全部隊列,存入 queues 字段中。
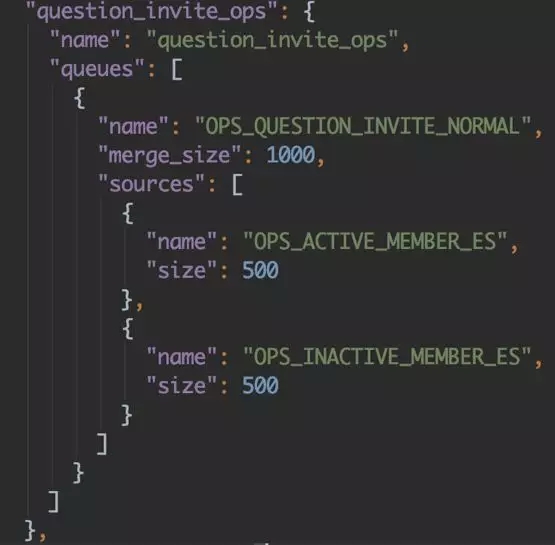
通過 name 來從注冊管理器的 map 中調取相應的隊列服務。

之后呢我們就可以并發進行多隊列的處理。
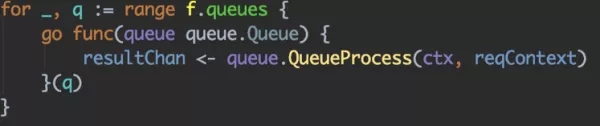
對于多路召回,及整個推薦具體流程的可插拔,與上面處理手法類似,比如如下隊列:
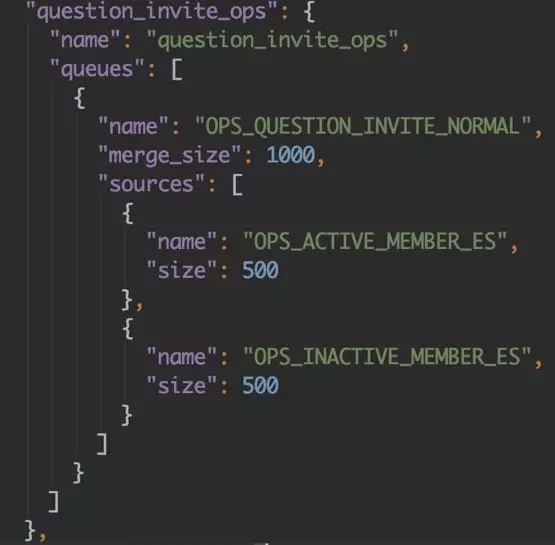
我們可以指定所需召回源,指定 merger 策略等等,當某個過程不需處理,會按自動默認步驟處理,這樣在具體 Queue 的實現中就可以通過如下簡單操作進行自由配置。
我們講完了架構上一些思考點和具體架構實現方案,下面就是關于召回層具體技術選型問題。
我們先回顧一下,在常用的推薦召回源中,有基于 topic(tag)的召回、實體的召回、地域的召回、CF(協同過濾)的召回以及 NN 產生的 embedding 召回等等。那么為了能夠支持這些召回,技術上我們應該如何來實現呢?
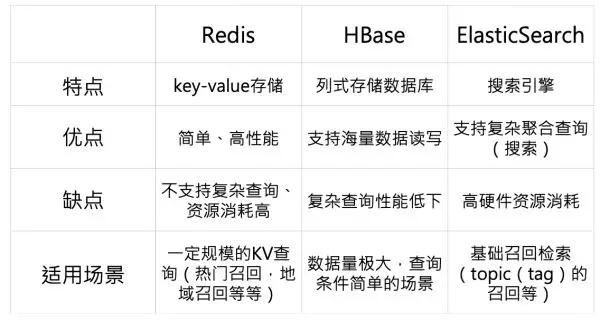
我們先從使用角度看一下常用的 NoSQL 數據庫產品,Redis 是典型的 k-v 存儲,其簡單、并且高性能使得其在業內得到大量使用,但不支持復雜查詢的問題也讓 Redis 在召回復雜場景下并不占優,因此一般主要適用于 kv 類的召回,比如熱門召回,地域召回,少量的 CF 召回等等。而 HBase 作為海量數據的列式存儲數據庫,有一個明顯缺點就是復雜查詢性能差,因此一般適合數據查詢量大,但查詢簡單的場景,比如推薦系統當中的已讀已推等等場景。而 ES 其實已經不算是一個數據庫了,而是一個通用搜索引擎范疇,其***優點就是支持復雜聚合查詢,因此將其用戶通用基礎檢索,是一個相對適合的選擇。
我們上面介紹了通用召回的技術選型,那么 embedding 召回如何來處理呢,我們的方案是基于 Facebook 開源的 faiss 封裝,構建一個通用 ANN(近似最近鄰)檢索服務。faiss 是為稠密向量提供高效相似度搜索和聚類的框架。其具有如下特性:1、提供了多種 embedding 召回方法;2、檢索速度快,我們基于 python 接口封裝,影響時間在幾 ms-20ms 之間;3、c++ 實現,并且提供了 python 的封裝調用;4、大部分算法支持 GPU 實現。
從以上介紹可以看出,在通用的推薦場景中,我們召回層大體是基于 ES+Redis+ANN 的模式進行構建。ES 主要支持相對復雜的召回邏輯,比如基于多種 topic 的混合召回;Redis 主要用于支持熱門召回,以及規模相對較小的 CF 召回等;ANN 主要支持 embedding 召回,包括 nn 產出的 embedding、CF 訓練產出的 embedding 等等。
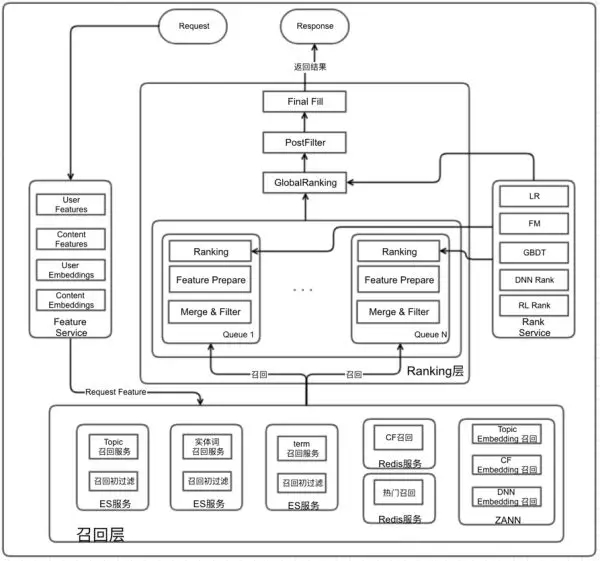
介紹完以上思考點,我們總體的架構就基本成型了,具體如下圖所示。該框架可以支持多隊列融合,并且每個隊列也支持多路召回,從而對于不同推薦場景能夠較好的支持,另外,我們召回選擇了 ES+Redis+ANN 的技術棧方案,可以較好支持多種不同類型召回,并達到服務線上的最終目的。
重構遇到的一些問題及解決方案
1、離線任務和模型的管理問題。我們做在線服務的都有體會,我們經常容易對線上業務邏輯代碼更關注一些,而往往忽視離線代碼任務的管理和維護。但離線代碼任務和模型在推薦場景中又至關重要。因此如何有效維護離線代碼和任務,是我們面臨的***個問題。
2、特征日志問題。在推薦系統中,我們常常會遇到特征拼接和特征的『時間穿越』的問題。所謂特征時間穿越,指的是模型訓練時用到了預測時無法獲取的『未來信息』,這主要是訓練 label 和特征拼接時時間上不夠嚴謹導致。如何構建便捷通用的特征日志,減少特征拼接錯誤和特征穿越,是我們面臨的第二個問題。
3、服務監控問題。一個通用的推薦系統應該在基礎監控上做到盡可能通用可復用,減少具體業務對于監控的開發量,并方便業務定位問題。
4、離線任務和模型的管理問題。
在包括推薦系統的算法方向中,需要構建大量離線任務支持各種數據計算業務,和模型的定時訓練工作。但實際工作中,我們往往忽略離線任務代碼管理的重要性,當時間一長,各種數據和特征的質量往往無法保證。為了盡可能解決這樣的問題,我們從三方面來做,***,將通用推薦系統依賴的離線任務的代碼統一到一處管理;第二,結合公司離線任務管理平臺,將所有任務以通用包的形式進行管理,這樣保證所有任務的都是依賴***包;第三,建設任務結果的監控體系,將離線任務的產出完整監控起來。
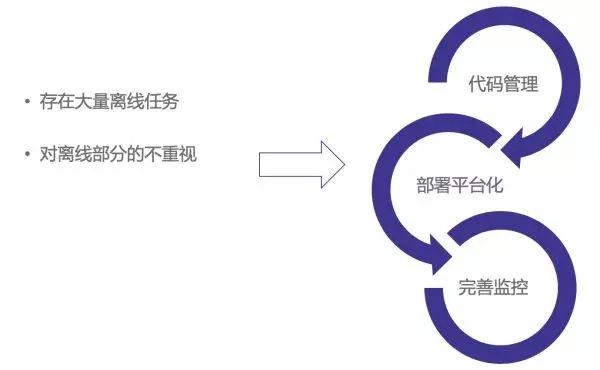
5、特征日志問題。
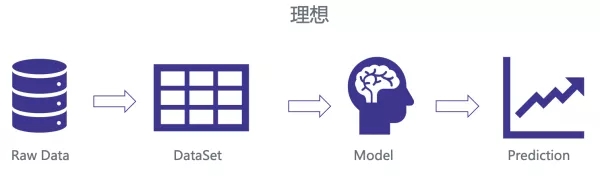
Andrew Ng 之前說過:『挖掘特征是困難、費時且需要專業知識的事,應用機器學習其實基本上是在做特征工程。』我們理想中的推薦系統模型應該是有干凈的 Raw Data,方便處理成可學習的 Dataset,通過某種算法學習 model,來達到預測效果不斷優化的目的。
但現實中,我們需要處理各種各樣的數據源,有數據庫的,有日志的,有離線的,有在線的。這么多來源的 Raw Data,不可避免的會遇到各種各樣的問題,比如特征拼接錯誤,特征『時間穿越』等等。
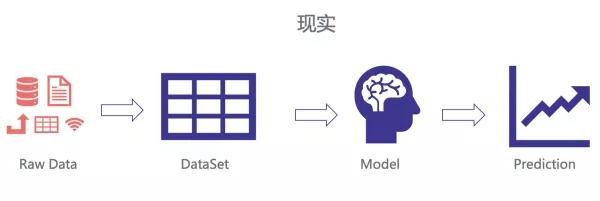
這里邊反應的一個本質問題是特征處理流程的規范性問題。那么我們是如何來解決這一點呢,首先,我們用在線代替了離線,通過在線落特征日志,而不是 Raw Data,并統一了特征日志 Proto,如此就可以統一特征解析腳本。

6、服務監控問題。
在監控問題上,知乎搭建了基于 StatsD + Grafana + InfluxDB 的監控系統,以支持各種監控日志的收集存儲及展示。基于這套系統,我們可以便捷的構建自己微服務的各種監控。

我們這里不過多介紹通用監控系統,主要介紹下,基于推薦系統我們監控建設的做法。首先先回顧一下我們推薦系統的通用設計上,我們采用了『可插拔』的多隊列和多召回的設計,那么可以在通用架構設計獲取到各種信息,比如業務線名,業務名,隊列名,process 名等等。如此,我們就可以將監控使用如下方式實現,這樣就可以通用化的設計監控,而不需各個推薦業務再過多設計監控及相關報警。

按照如上實現之后,我們推薦系統的監控體系大概是什么樣子?首先各個業務可以通過 grafana 展示頁面進行設置。我們可以看到各個 flow 的各種數據,以及召回源的比例關系,還有特征分布,ranking 得分分布等等。
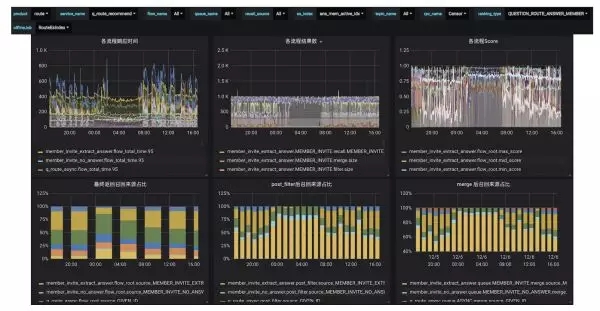
未來挑戰講完了遇到的一些問題之后,我們來看一下未來的挑戰。隨著業務的快速發展,數據和規模還在不斷擴張,架構上還需要不斷迭代;第二點,隨著推薦業務越來越多,策略的通用性和業務之間的隔離如何協調一致;第三點,資源調度和性能開銷也需要不斷優化;***,多機房之間數據如何保持同步也是需要考慮的問題。
總 結
***,我們做個簡單總結:***點,重構語言的選擇,關鍵要跟公司技術背景和業務場景結合起來;第二點,架構盡量靈活,并不斷自我迭代;第三點,監控要早點開展,并盡可能底層化、通用化。