負載突然翻了100倍,如何拯救MySQL架構?
最近有一個業務庫的負載比往常高了很多,最直觀的印象就是原來的負載***是 100%,現在不是翻了幾倍或者指數級增長,而是突然翻了 100 倍,導致業務后端的數據寫入劇增,產生了嚴重的性能阻塞。
引入讀寫分離,優化初見成效
這類問題引起了我的興趣和好奇心,經過和業務方溝通了解,這個業務是記錄回執數據的。
簡單來說就好比你發送了一條微博,想看看有多少人已讀,有多少人留言等。所以這類場景不存在事務,會有數據的密集型寫入,會有明確的統計需求。
目前的統計頻率是每 7 分鐘做一次統計,會有幾類統計場景,目前基本都是全表掃描級別的查詢語句。當前數據庫的架構很簡單,是一個主從,外加 MHA 高可用。
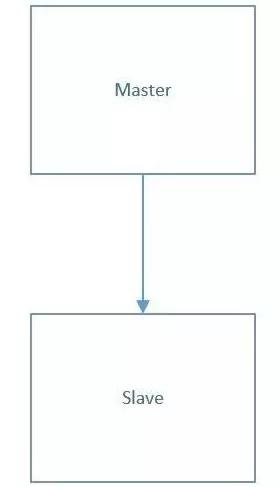
問題的改進方向是減少主庫的壓力,分別是讀和寫的壓力。寫入的壓力來自于業務的并發寫入壓力,而讀的壓力來自于于全表掃描的壓力,對于 CPU 和 IO 壓力都很大。
這兩個問題的解決還是存在優先級,首先統計的 SQL 導致了系統資源成為瓶頸,結果原本簡單的 Insert 也成為了慢日志 SQL,相比而言,寫入需求是硬需求。
而統計需求是輔助需求,所以在這種場景下和業務方溝通,快速的響應方式就是把主庫的統計需求轉移到從庫端。
轉移了讀請求的負載,寫入壓力得到了極大緩解,后來也經過業務方的應用層面的優化,整體的負載情況就相對樂觀了。
主庫的監控負載如下圖:
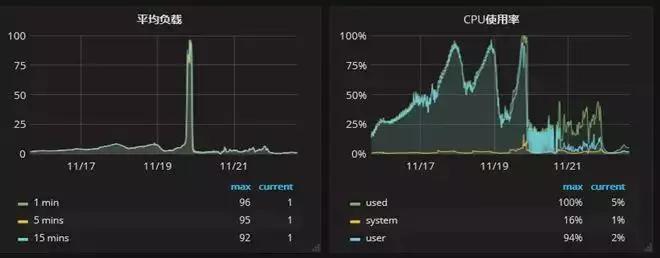
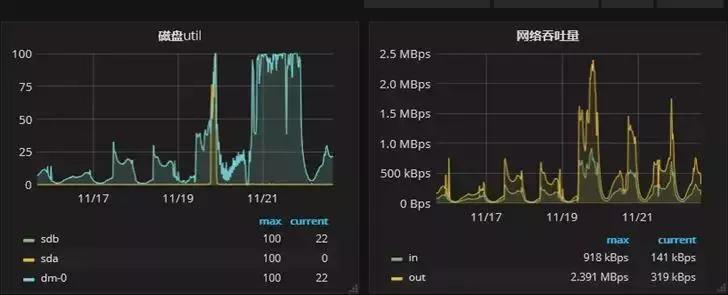
可以看到有一個明顯降低的趨勢,CPU 負載從原來的 90% 以上降到了不到 10%。IO 的壓力也從原來的近 100% 降到了 25% 左右。
從庫的監控負載如下圖:
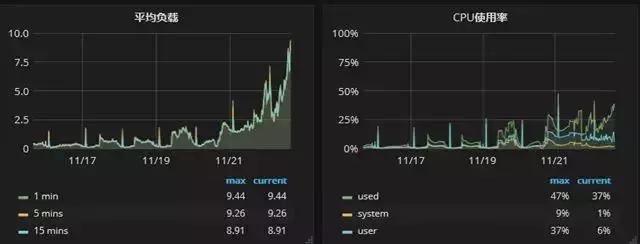
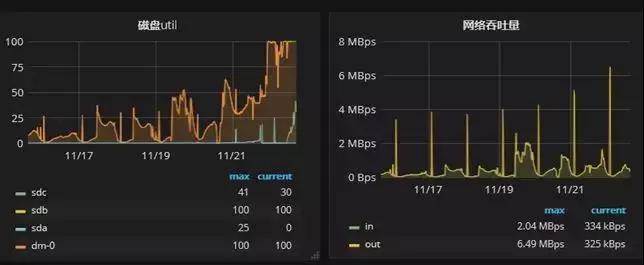
可以看到壓力有了明顯的提升。CPU 層面的體現不夠明顯,主要的壓力在于 IO 層面,即全表數據的掃描代價極高。
這個算是優化的***步改進,在這個基礎上,開始做索引優化,但是通過對比,發現效果很有限。
因為從庫端的是統計需求,添加的索引只能從全表掃描降級為全索引掃描,對于系統整體的負載改進卻很有限,所以我們需要對已有的架構做一些改進和優化。
方案 1
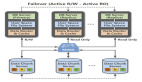
考慮到資源的成本和使用場景,所以我們暫時把架構調整為如下的方式:即添加兩個數據節點,然后打算啟用中間件的方式來做分布式的架構設計。
對于從庫,暫時為了節省成本,就對原來的服務器做了資源擴容,即單機多實例的模式,這樣一來寫入的壓力就可以完全支撐住了。
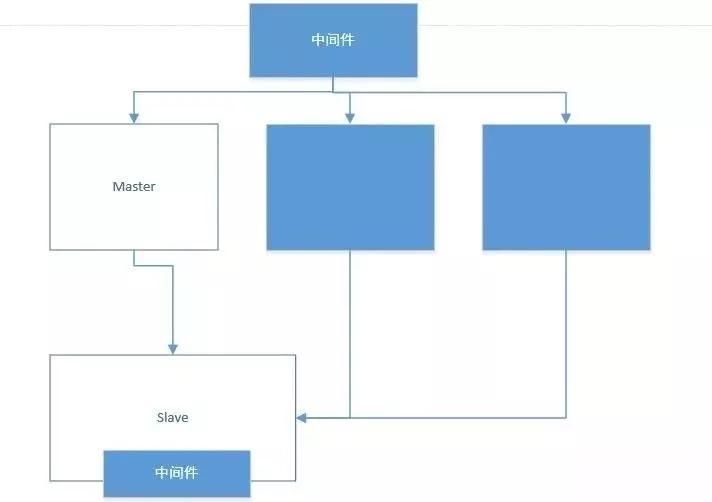
但是這種方式有一個潛在的隱患,那就是從庫的中間件層面來充當數據統計的角色,一旦出現性能問題,對于中間件的壓力極大,很可能導致原本的統計任務會阻塞。
同時從庫端的資源瓶頸除了磁盤空間外就是 IO 壓力,目前通過空間擴容解決不了這個硬傷。
在和業務同學進一步溝通后,發現他們對于這一類表的創建是動態配置的方式,在目前的中間件方案中很難以落實。而且對于業務來說,統計需求變得更加不透明了。
方案 2
一種行之有效的改進方式就是從應用層面來做數據路由,比如有 10 個業務:業務 1、業務 2 在***個節點,業務 3、業務 5 在第二個節點等等。
按照這種路由的配置方式來映射數據源,相對可控,更容易擴展,所以架構方式改為了這種:
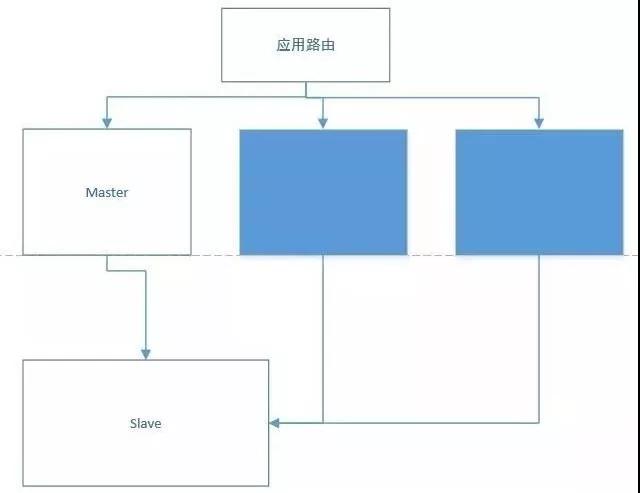
而整個的改進中,最關鍵的一環是對于統計 SQL 性能的改進,如果 SQL 統計性能的改進能夠初見成效,后續的架構改進就會更加輕松。
引入列式存儲,優化統計性能
后續又開始有了業務的爆發式增長,使得統計需求的優化成為本次優化的關鍵所在。
原來的主庫讀寫壓力都很大,通過讀寫分離,使得讀節點的壓力開始激增,而且隨著業務的擴展,統計查詢的需求越來越多。
比如原來是有 10 個查詢,現在可能變成了 30 個,這樣一來統計壓力變大,導致系統響應降低,從而導致從庫的延遲也開始變大。
***的時候延遲有 3 個小時,按照這種情況,統計的意義其實已經不大了。
對此我做了幾個方面的改進:
- 首先是和業務方進行了細致的溝通,對于業務的場景有了一個比較清晰的認識,其實這個業務場景是蠻適合 Redis 之類的方案來解決的,但是介于成本和性價比選擇了關系型的 MySQL,結論:暫時保持現狀。
- 對于讀壓力,目前不光支撐不了指數級壓力,連現狀都讓人擔憂。業務的每個統計需求涉及 5 個 SQL,要對每個場景做優化都需要取舍。
***達到的一個初步效果是字段有 5 個,索引就有 3 個,而且不太可控的是一旦某個表的數據量太大導致延遲,整個系統的延遲就會變大,從而造成統計需求都整體垮掉。
所以添加索引來解決硬統計需求算是心有力而力不足。結論:索引優化效果有限,需要尋求其他可行解決方案。
- 對于寫壓力,后續可以通過分片的策略來解決,這里的分片策略和我們傳統認為的邏輯不同,這是基于應用層面的分片,應用端來做這個數據路由。這樣分片對于業務的爆發式增長就很容易擴展了。
有了這一層保障之后,業務的統計需求遷移到從庫,寫壓力就能夠平滑的對接了,目前來看寫壓力的空余空間很大,完全可以支撐指數級的壓力。結論:業務數據路由在統計壓力減緩后再開始改進。
為了快速改進現狀,我寫了一個腳本自動采集和管理,會定時殺掉超時查詢的會話。
但是延遲還是存在,查詢依舊是慢,很難想象在指數級壓力的情況下,這個延遲會有多大。
在做了大量的對比測試之后,按照單表 3500 萬的數據量,8 張同樣數據量的表,5 條統計 SQL,做完統計大約需要 17~18 分鐘左右,平均每個表需要大約 2 分多鐘。
因為不是沒有事務關聯,所以這個場景的延遲根據業務場景和技術實現來說是肯定存在的,我們的改進方法是提高統計的查詢效率,同時保證系統的壓力在可控范圍內。
一種行之有效的方式就是借助于數據倉庫方案,MySQL 原生不支持數據庫倉庫,但是有第三方的解決方案:
- 一類是 ColumnStore,是在 InfiniDB 的基礎上改造的。
- 一類是 Infobright,除此之外還有其他大型的解決方案,比如 Greenplum 的 MPP 方案。
ColumnStore 的方案有點類似于這種 MPP 方案,需要的是分布式節點,所以在資源和架構上 Infobright 更加輕量一些。
我們的表結構很簡單,字段類型也是基本類型,而且在團隊內部也有大量的實踐經驗。
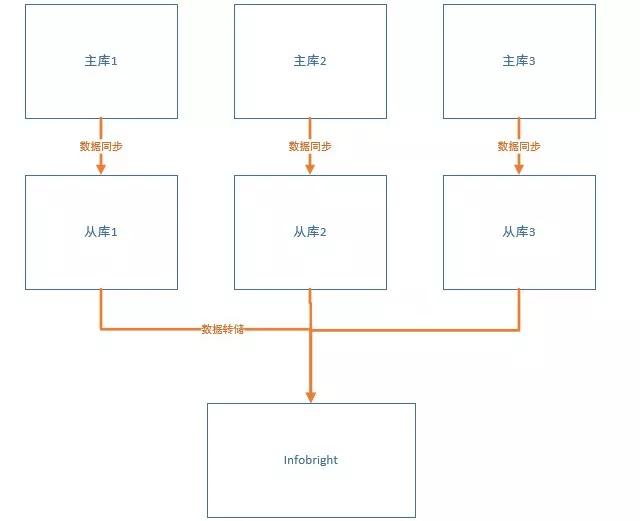
改進之后的整體架構如下,原生的主從架構不受影響:
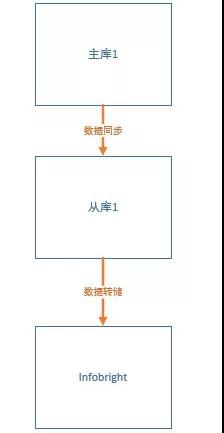
需要在此基礎上擴展一個數據倉庫節點,數據量可以根據需要繼續擴容。
表結構如下:
- CREATE TABLE `receipt_12149_428` (
- `id` int(11) NOT NULL COMMENT '自增主鍵',
- `userid` int(11) NOT NULL DEFAULT '0' COMMENT '用戶ID',
- `action` int(11) NOT NULL DEFAULT '0' COMMENT '動作',
- `readtimes` int(11) NOT NULL DEFAULT '0' COMMENT '閱讀次數',
- `create_time` datetime NOT NULL COMMENT '創建時間'
- ) ;
導出的語句類似于:
- select *from ${tab_name} where create_time between xxx and xxxx into outfile '/data/dump_data/${tab_name}.csv' FIELDS TERMINATED BY ' ' ENCLOSED BY '\"';
Infobright 社區版是不支持 DDL 和 DML 的,后期 Infobright 官方宣布:不再發布 ICE 社區版,將專注于 IEE 的開發,所以后續的支持力度其實就很有限了。對于我們目前的需求來說是游刃有余。
來簡單感受下 Infobright 的實力:
- >select count( id) from testxxx where id>2000;
- +------------+
- | count( id) |
- +------------+
- | 727686205 |
- +------------+
- 1 row in set (6.20 sec)
- >select count( id) from testxxxx where id<2000;
- +------------+
- | count( id) |
- +------------+
- | 13826684 |
- +------------+
- 1 row in set (8.21 sec)
- >select count( distinct id) from testxxxx where id<2000;
- +---------------------+
- | count( distinct id) |
- +---------------------+
- | 1999 |
- +---------------------+
- 1 row in set (10.20 sec)
所以對于幾千萬的表來說,這都不是事兒。我把 3500 萬的數據導入到 Infobright 里面,5 條查詢語句總共的執行時間維持在 14 秒,相比原來的 2 分多鐘已經改進很大了。
我跑了下批量的查詢,原本要 18 分鐘,現在只需要不到 3 分鐘。
引入動態調度,解決統計延遲問題
通過引入 Infobright 方案對已有的統計需求可以做到***支持,但是隨之而來的一個難點就是對于數據的流轉如何平滑支持。
我們可以設定流轉頻率,比如 10 分鐘等或者半個小時,但是目前來看,這個是需要額外的腳本或工具來做的。
在具體落地的過程中,發現有一大堆的事情需要提前搞定。
其一:比如***個頭疼的問題就是全量的同步,***次同步肯定是全量的,這么多的數據怎么同步到 Infobright 里面。
第二個問題,也是更為關鍵的,那就是同步策略是怎么設定的,是否可以支持的更加靈活。
第三個問題是基于現有的增量同步方案,需要在時間字段上添加索引。對于線上的操作而言又是一個巨大的挑戰。
其二:從目前的業務需求來說,最多能夠允許一個小時的統計延遲,如果后期要做大量的運營活動,需要更精確的數據支持,要得到半個小時的統計數據,按照現有的方案是否能夠支持。
這兩個主要的問題,任何一個解決不了,數據流轉能夠落地都是難題,這個問題留給我的時間只有一天。
所以我準備把前期的準備和測試做得扎實一些,后期接入的時候就會順暢得多。
部分腳本實現如下:
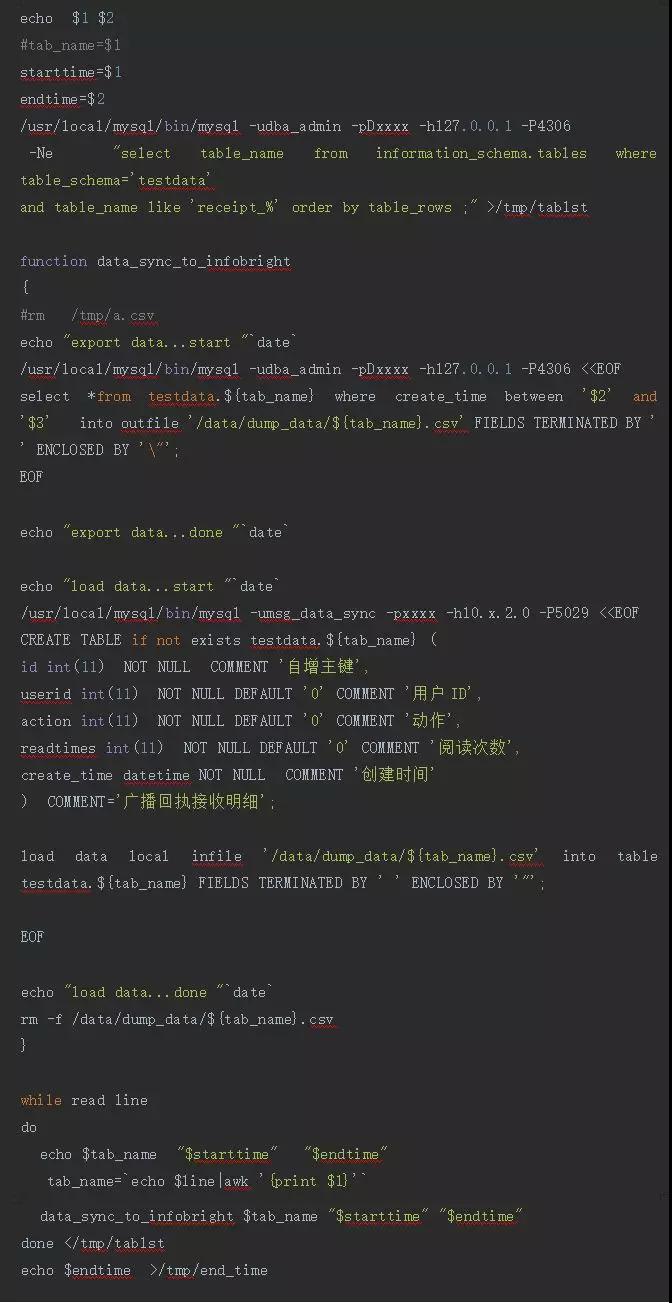
腳本的輸入參數有兩個,一個是起始時間,一個是截止時間。***次全量同步的時候,可以把起始時間給的早一些,這樣截止時間是固定的,邏輯上就是全量的。
另外全量同步的時候一定要確保主從延遲已經***或者暫時停掉查詢業務,使得數據全量抽取更加順利。
所以需要對上述腳本再做一層保證,通過計算當前時間和上一次執行的時間來得到任務可執行的時間。這樣腳本就不需要參數了,這是一個動態調度的迭代過程。
考慮到每天落盤的數據量大概在 10G 左右,日志量在 30G 左右,所以考慮先使用客戶端導入 Infobright 的方式來操作。
從實踐來看,涉及的表有 600 多個,我先導出了一個列表,按照數據量來排序,這樣小表就可以快速導入,大表放在***,整個數據量有 150G 左右,通過網絡傳輸導入 Infobright,從導出到導入完成,這個過程大概需要 1 個小時。
而導入數據到 Infobright 之后的性能提升也是極為明顯的。原來的一組查詢持續時間在半個小時,現在在 70 秒鐘即可完成。對于業務的體驗來說大大提高。
完成了***次同步之后,后續的同步都可以根據實際的情況來靈活控制。所以數據增量同步暫時是“手動擋”控制。
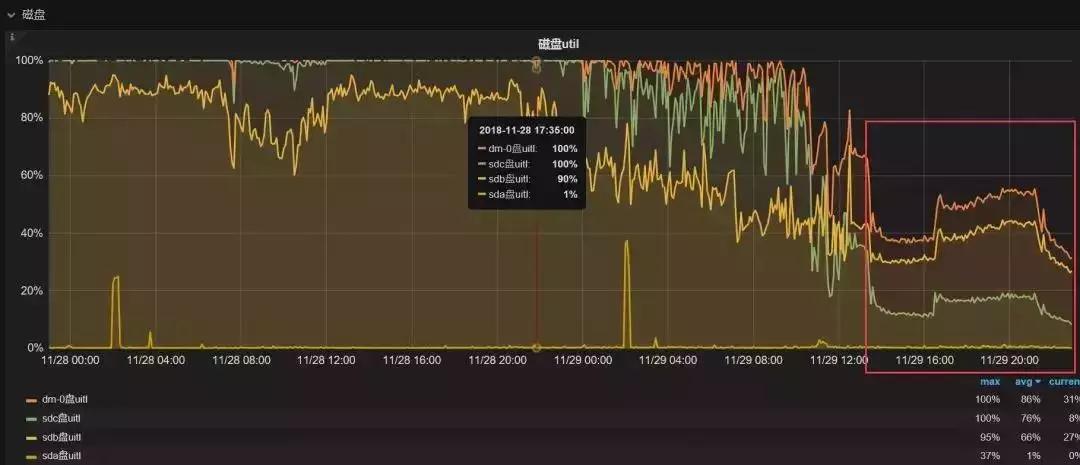
從整個數據架構分離之后的效果來看,從庫的壓力大大降低,而效率也大大提高。
引入業務路由,平滑支持業務擴容
前面算是對現狀做到了***程度的優化,但是還有一個問題,目前的架構暫時能夠支撐密集型數據寫入,但是不能夠支持指數級別的壓力請求,而且存儲容量很難以擴展。
從我的理解中,業務層面來做數據路由是***的一種方式,而且從擴展上來說,也更加友好。
所以再進一層的改進方案如下:
通過數據路由來達到負載均衡,從目前來看效果是很明顯的,而在后續要持續的擴容時,對于業務來說也是一種可控的方式。
以下是近期的一些優化時間段里從庫的 IO 的壓力情況:
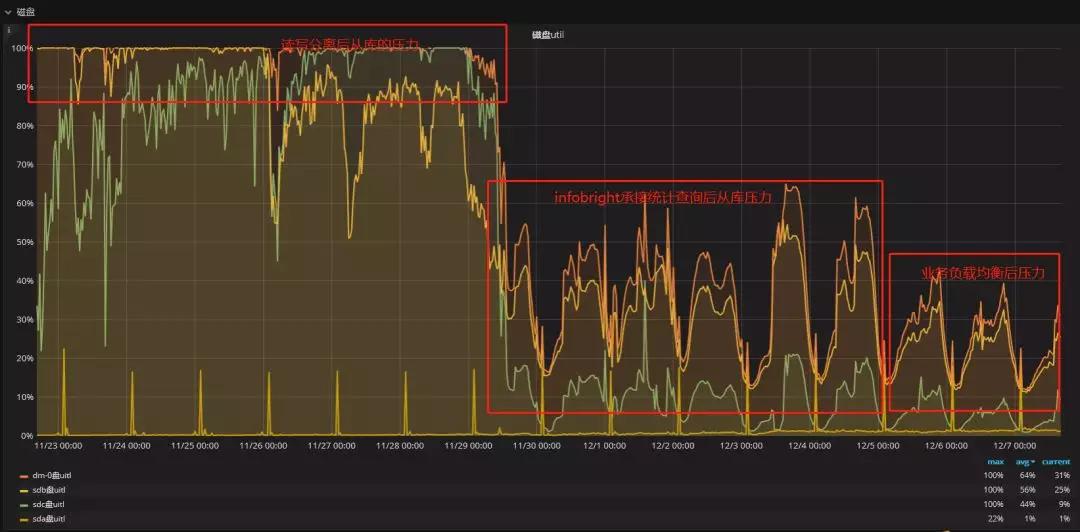
經過陸續幾次地解決問題、補充并跟進方案,我們完成了從最初的故障到落地成功,MySQL 性能擴展的架構優化分享也已經基本了結。如有更好的實現方式,歡迎大家在留言區交流分享!
作者:楊建榮
簡介:競技世界資深 DBA,前搜狐暢游數據庫專家,Oracle ACE,YEP 成員。擁有近十年數據庫開發和運維經驗,目前專注于開源技術、運維自動化和性能調優。擁有 Oracle 10g OCP、OCM、MySQL OCP 認證,對 Shell、Java 有一定功底。每天通過微信、 博客進行技術分享,已連續堅持 1800 多天。