深度學習在蘇寧知識抽取領域的嘗試與實踐
原創【51CTO.com原創稿件】背景
近幾年,隨著海量數據的累積、計算能力的提升和算法模型的創新,無論是在學術界還是工業界,深度學習在NLP領域已經得到越來越多的關注與應用,并且有很多可喜的落地成果。知識的抽取和挖掘一直是Data Mining、Knowledge Graph等NLP子領域的重要問題,知識抽取的范圍包括實體抽取、關系抽取、屬性抽取等,本文主要介紹深度學習在蘇寧小店商品標題上的應用,重點挖掘屬性詞、品牌詞、物品詞等和業務強相關的實體信息。
知識抽取任務按照文本結構可分為以下幾類:
面向結構化數據的知識抽取:比如用D2R從結構化數據庫中提取知識,其難點在于對復雜表數據的處理,包括嵌套表、多列、外鍵關聯等;采用圖映射的方式從鏈接數據中獲取知識,難點在于數據的對齊。
面向半結構化的知識抽取:使用包裝器從半結構化(比如網站)數據中獲取知識,難點在于包裝器的自動生成、更新與維護。
面向文本的知識抽取:與上面結構/半結構化方式不同,由于非結構文本的知識格式基本上沒有固定的規則可尋,業界也缺乏能直接應用于中文的處理工具,所以本文采用深度學習方法,重點關注word embedding質量的角度,從隨機初始化向量到主流預訓練方法,去有效提升抽取結果的準確率和覆蓋率。
B-LSTM+CRF模型
B-LSTM+CRF是2016年卡耐基梅隆大學和龐培法布拉大學NLP組提出的一種解決NER問題的網絡架構,并經實驗在4種語言(英語、德語、荷蘭語、西班牙語)上表現亮眼,其中在德語和西班牙語上取得了SOA效果,所以本文將采用這種網絡結構作為蘇寧搜索知識抽取任務的關鍵模型之一,下面先簡單介紹這種模型。
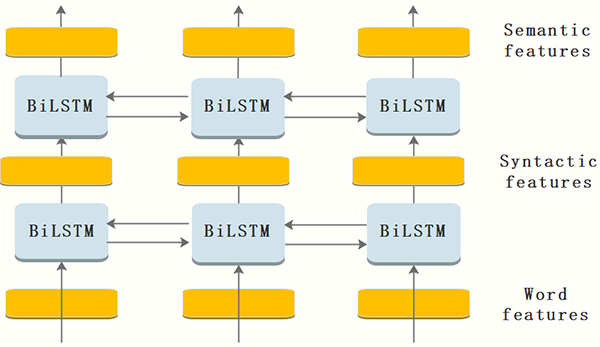
模型框架
模型數據的輸入采用兩種方案,***種不使用任何分詞算法,采用BIO的標注方法直接以“字”為單位做序列標注,第二種采用業務自定義的標簽集對分詞后的word進行標注。利用蘇寧搜索平臺累積的業務詞表對蘇寧小店的商品標題做自動標注,經過運營的篩選和剔除,獲取干凈的數據集。
這里以***種標注方法為例(ATT:屬性詞,BRA:品牌詞,GOD:物品詞),以小店商品標題為單位,將一個含有n個字的title(字的序列)記作:
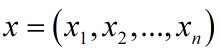
其中 xi 表示標題的第 i 個字在字典中的id,暫不考慮預訓練,進而可以得到每個字的one-hot向量,維數是字典大小。
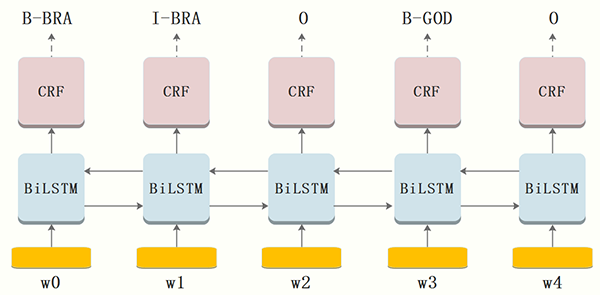
***層:look-up 層,利用word2vec或隨機初始化的embedding矩陣將title中的每個字 xi 由one-hot向量映射為低維稠密的字向量(character embedding)xi∈Rd ,d是embedding的維度。在輸入下一層之前,設置dropout以緩解過擬合。
第二層:雙向LSTM層,自動提取title特征。將一個title的各個字的char embedding序列 (x1,x2,...,xn) 作為雙向LSTM各個時間步的輸入,再將正向LSTM輸出的隱狀態序列
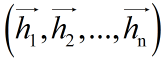
與反向LSTM的
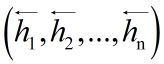
在各個位置輸出的隱狀態進行按位置拼接,
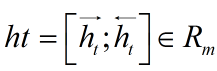
得到完整的隱狀態序列

對隱層的輸出設置dropout后,再外接一個線性層,將隱狀態向量從 m 維映射到 k 維,k 是標注集的標簽數,從而得到自動提取的title特征,記作矩陣 P=(p1,p2,...,pn)∈Rn×k 。可以把 pi∈Rk的每一維 pij 都視作將字 xi 分類到第 j 個標簽的打分值,如果再對 P 進行Softmax的話,就相當于對各個位置獨立進行 k 類分類。但是這樣對各個位置進行標注時無法利用已經標注過的信息,所以接下來將接入一個CRF層來進行標注。
第三層:CRF層,進行title級的序列標注。CRF層的參數是一個(k+2)×(k+2)的矩陣A ,Aij表示的是從第 i 個標簽到第 j 個標簽的轉移得分,進而在為一個位置進行標注的時候可以利用此前已經標注過的標簽。如果記一個長度等于title長度的標簽序列 y=(y1,y2,...,yn) ,那么模型將整個title x 的標簽標注為序列 y 的打分函數為:(公式1)
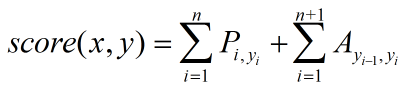
可以看出整個序列的打分等于各個位置的打分之和,而每個位置的打分由兩部分得到,一部分是由LSTM輸出的 pi 決定,另一部分則由CRF的轉移矩陣 A 決定。進而可以利用Softmax得到歸一化后的概率:(公式2)
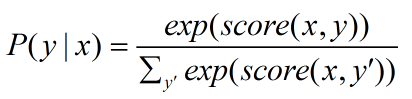
模型訓練時通過***化對數似然函數,下式給出了對一個訓練樣本 (x,y) 的對數似然:(公式3)
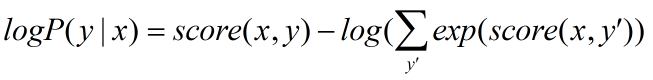
模型在預測過程時使用動態規劃的Viterbi算法來求解***路徑,從而得到每個字的預測標簽:(公式4)
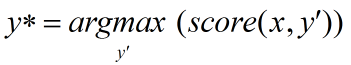
CRF層約束性規則
由于B-LSTM的輸出為單元的每一個標簽分值,我們可以挑選分值***的一個作為該單元的標簽。例如,對于單元w0,“I-BRA”有***分值 1.5,因此我們可以挑選“I-BRA”作為w0的預測標簽。同理,我們可以得到其他token的標簽,w1:“B-BRA”,w2:“O” ,w3:“B-GOD”,w4:“O”。
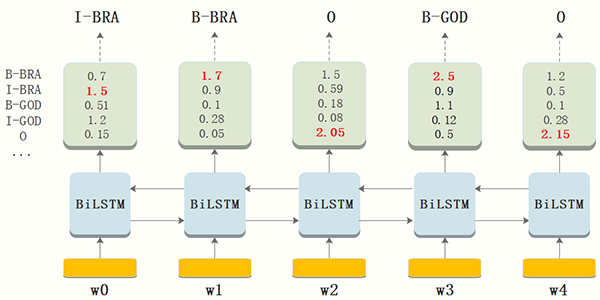
雖然單純的通過B-LSTM我們可以得到title中每個token的標簽,但是不能保證標簽每次都是預測正確的。例如,上圖中的例子,標簽序列是“I-BRA B-BRA”很顯然是錯誤的。

在神經網絡的輸出層接入CRF層(重點是利用標簽轉移概率)來做句子級別的標簽預測,使得標注過程不再是對各個token獨立分類。B-LSTM計算出的是每個詞的各標簽概率,而CRF層引入序列的轉移概率,最終計算出loss反饋回網絡,所以上圖在CRF的作用下,序列能根據轉移概率做出符合常理的調整。
CRF層可以為***預測的標簽添加一些約束來保證預測的標簽是符合規則的,這些約束可以在訓練數據訓練過程中,通過CRF層自動學習到。
比如:
1、title中***個詞總是以標簽“B-” 或 “O”開始,而不是“I-”;
2、標簽“B-label1 I-label2 I-label3 I-…”,label1, label2, label3應該屬于同一類實體。例如,“B-BRA I-BRA” 是合法的序列, 但是“B-BRA I-GOD” 是非法標簽序列;
3、標簽序列“O I-label” 是非法的.實體標簽的***標簽應該是 “B-” ,而非 “I-”, 換句話說,有效的標簽序列應該是“O B-label”。
有了以上自動學習到的約束規則,標簽序列預測中非法序列出現的概率將會顯著降低。
實驗效果
論文[1]基于語料CoNLL-2003,在4種語言(英語、德語、荷蘭語、西班牙語)上表現亮眼,其中在德語和西班牙語上取得了SOA效果。
在蘇寧小店商品標題標注語料上,我們進行了隨機初始向量和word2vec預訓練的對比實驗,實驗1的方式比較粗糙,我們以“字”為單位,對非數字和字母的字符進行one-hot編碼并經過look-up層獲得字符的低維稠密編碼,所有數字和字母的編碼分別被固化;實驗2對非數字和字母的字符采用word2vec預訓練的編碼方式;考慮到商品title中的數字和英文字母對編碼的重要性,實驗3對實驗2稍加改造,同時訓練出字母、數字的字向量;實驗4舍棄實驗3中基于character的編碼方式,按照分詞后的token重新標注后作為模型的輸入,下表展示了實驗結果(N表示未對字母與數字進行區分編碼,Y相反):

從上面的實驗可知,將每個字母與數字視為和漢字相同意義的字符后對F1值的提升有較大作用。從小店實際要提取的實體信息結構我們也可以知道,字母和數字是屬性詞、品牌詞的重要構成部分,比如:1000g的洗衣粉,“1000g”是需要提取的屬性詞;HUAWEI p20手機套,“HUAWEI”是需要提取的品牌詞。Word2vec對分詞后的token進行預訓練后,模型的準確率又得到了進一步提升,由此可見,word相對于char包含的語義更豐富,有助于模型參數的正確擬合。
ELMO
上文B-LSTM+CRF輸入的word embedding是通過隨機化或word2vec訓練得到的,這種方式得到的embedding質量不高,包含的隱含特征很有限且無法解決一詞多義,比如“蘋果”,如果蘋果前面是吃、咬等食用性動詞,則蘋果表示一種水果,是我們需要提取的物品詞,如果是“某某蘋果手機”,或title中含有256g、金色等屬性詞,則蘋果是我們需要提取的品牌詞。因為word2vec模型的學習目標是預測詞發生的概率,這種從海量語料中學習到的是詞的通用語義信息,無法直接應用于定制業務的匹配場景。
ELMO是2018年由AllenNLP出品,并被評為當年NAACL best paper,它的主要貢獻是訓練得到的word embedding融于了豐富的句法和語義特征,作者將它加入到下游任務中,在六項挑戰性的NLP任務中取得了SOA效果。從官網給出的效果來看,基本上在原SOA的基礎上絕對提升了2~4個百分點。
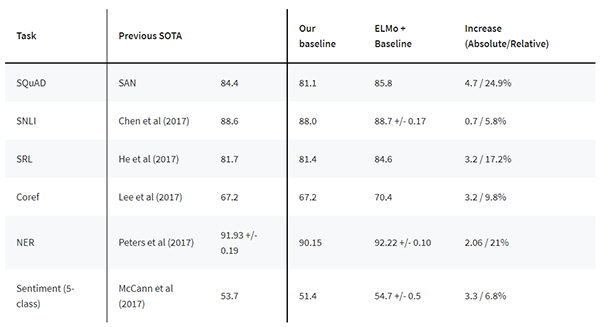
模型框架與原理
下面從模型結合源碼的角度來分析這個神奇的模型。
由于傳統NLP語言模型是一種單向的概率模型,對于預測下一個word,只利用了前向的單詞,比如預測第k個單詞,用公式表示如下:(公式5)
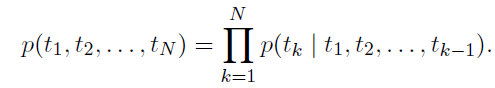
所以這種模型的弊端就很明顯,無法利用預測單詞的右側信息,尤其是在完形填空、閱讀理解、機器翻譯等領域需要考慮上下文的場合不是特別適用,對于本文目標這種提取標題中的品牌、屬性、物品詞等信息,考慮其上下文的信息也是很有必要的,只考慮右向信息的語言模型公式如下:(公式6)
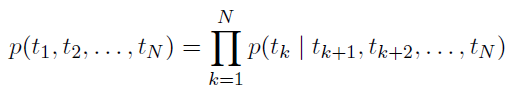
ELMO的創新之處是采用了兩層的B-LSTM模型,同時考慮左右兩側的信息,將上面公式5和6聯立起來作為目標函數:(公式7)
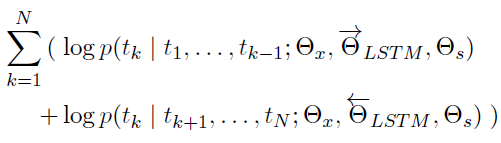
通過***化上面的似然函數,求得模型的參數。其中, 表示模型的初始化輸入的token representation,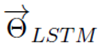 、
、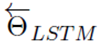 分別表示前向、后向隱層的token representation,
分別表示前向、后向隱層的token representation,
表示前后向的softmax參數,用來調節隱層representation的比重。
當喂訓練數據給這個網絡時,經過一定的迭代訓練次數,我們就可以得到各個隱層以及初始token的embedding,下面k表示第k個token,j表示網絡的層數:(公式8)
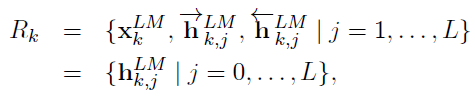
上面是一個token的三層embedding綜合表達,要獲取最終的embedding,我們需要去調節每個隱層(包含初始輸入,當做第0層)在最終embedding中所占的比重。論文中給出了這個公式:(公式9)
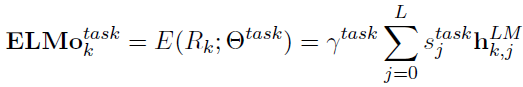
其中,sj是一個和task相關的權值,是由softmax函數normalized得到。
由源碼可知,如果只是利用ELMO去產出詞向量,而不和下游的任務結合使用的話,這里的task就是指上面公式7的語言模型task,sj是單純由這個“改進的”語言模型task而訓練得到。如果和下游的task配合使用,則是由兩者共同訓練得到。
按照論文的說法,***隱層的embedding能獲取更多的語法特征,第二隱層embedding能獲取更多的語義特征,所以當下游任務是偏句法分析的task時,會學習到更大的s1,反之,如果下游任務偏語義分析時,s2相對更大一些。
使用方式
從是否使用預訓練模型的角度,ELMO有兩種使用方式,***種就是直接使用官方提供的預訓練模型,它給我們提供了預訓練好的模型參數并給出了超參(官方的預訓練模型是基于英文的,10億token word的新聞語料,在3個GTX 1080上迭代10次訓練了長達2周的時間)。而我們的任務是中文對話語料的NER問題,不能直接使用其提供好的模型,但我們不妨先看一下官方對于使用其預訓練模型的幾種方式:

***種是使用字符輸入方式動態的去訓練你的語料,這種方式比較通用但是代價較高,它的好處是對于能一定程度減少未登錄詞的影響。第二種是將一些和上下文無關,沒什么歧義的詞事先訓練好緩存起來,等到用的時候就不用重復訓練了,這種方式相對1來說代價低一些,但是這些詞需要事先指定好。第三種是將你所有的語料,比如爬取的新聞數據、采集的對話數據等等全部喂給ELMO,把訓練好的***詞向量和中間隱層詞向量全部存起來,等到下游任務需要的時候直接去load就好了,我覺得這種方式一開始的代價比較高,但由于embedding可以復用,所以能給以后的task節約不少時間,在下游的task使用這些 embedding時和預訓練時一樣,做個動態的加權就好了。

上面介紹了使用預訓練模型的方式,歸根到底是在原來模型的基礎上對模型參數做了一個微調,從而間接對輸出的embedding做了微調,使輸出的embedding更符合當前上下文的語義。
從是否使用預訓練模型角度的第二種方式:自然就是不直接使用預訓練好的模型,那我們需要從零開始去訓練所有的參數,這個代價很高,但如果要使用ELMO去獲取中文的embedding,這個工作是必須要做的,步驟如下:

處理細節可參考哈工大的博文(如何將ELMo詞向量用于中文)。
實驗效果
說了這么多,EMLO到底有沒有解決一詞多義呢?請看下圖作者的實驗(論文[2]):

Glove根據它的 embedding 找出的最接近的其它單詞大多數集中在體育領域,這很明顯是因為訓練數據中包含 play 的句子中體育領域的數量明顯占優導致;而使用 ELMO,根據上下文動態調整后的 embedding 不僅能夠找出對應的「演出」的相同語義的句子,而且還可以保證找出的句子中的 play 對應的詞性也是相同的,這是超出期待之處。
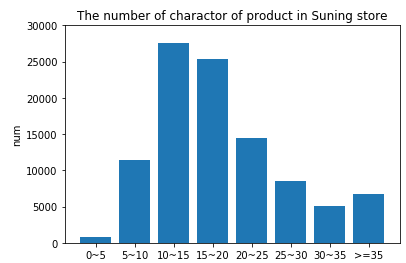
同樣的,在我們的蘇寧小店商品title知識抽取任務中,底層的預訓練方式由上文實驗4中的word2vec換為ELMO,對于相同的訓練數據,經過實驗得到的F1值稍有提升,但不太明顯。下圖采樣了10萬條蘇寧小店商品標題,統計了每條文本的字符個數,大部分集中在10~20個字符之間,可能這種短文本蘊含的句法和語義信息有限,ELMO相對word2vec學習到額外的特征也有限。
那ELMO有沒有什么缺點呢?顯然是有的!由于ELMO的特征提取器采用的是老將LSTM,其特征抽取能力遠弱于新貴Transformer,而且雙層B-LSTM拼接方式的雙向融合特征融合能力偏弱,所以這種模型架構還是有一些弊端的,因此下面嘗試采用18年大火的BERT架構作為底層word embedding的編碼器。
BERT
BERT是google在2018年的代表作,其在11項NLP任務中取得SOA效果,幾乎可以說是橫掃各種牛馬蛇神。BERT的主要創新在于提出了MLM(Mask Language Mode),并同時融入了預測句子的子任務,使Transformer可以實現雙向編碼。
Transformer是17年谷歌在論文《Attention is all you need》中提出的一種新的編解碼模型。模型創新性的提出了self-attention機制,在克服傳統RNN無法并行計算問題的同時,還能抽取到更多的語義信息,現在已經得到了工業界和學術界的青睞并有逐漸替代RNN、CNN等傳統模型的趨勢。
Self-attention機制利用查詢向量Q、鍵向量K和值向量V獲得了當前token和其他每個token的相關度,每個token根據這種相關度都自適應的融入了其他token的representation,用公式表示如下:(公式10)
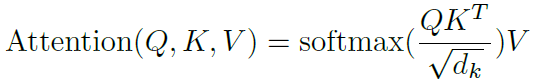
類似于CNN中的多核卷積操作,論文中同時使用了multi-head機制,因為每一個head都會使某個token和其他token產生關聯,這種關聯或多或少有強有弱,mutil-head通過拼接每個head的輸出,再乘以一個聯合模型訓練的權重矩陣,有效擴展了模型專注于不同位置的能力,有點博覽眾家之長的意思,公式表示如下:(公式11)

論文《Attention is all you need》主要驗證了Transformer在機器翻譯中的良好表現,和本文訓練word embedding的目標不一樣,機器翻譯是一個監督型任務,在給定的雙語語料下,模型的輸入是一個完整待翻譯sentence,sentence中的每個token都并行參與編碼,而詞向量訓練是一個無監督任務,常常使用傳統NLP語言模型去***化語言模型的極大似然,從而得到每個token的representation,它僅僅考慮單向的token信息。說到使用transformer進行詞向量訓練就不得不提2018年OpenAI提出的論文《Improving Language Understanding by Generative Pre-Training》(簡稱GPT),但其在非監督預訓練階段使用的仍然是單向的語言模型,訓練出的word embedding固然損失了許多精度。
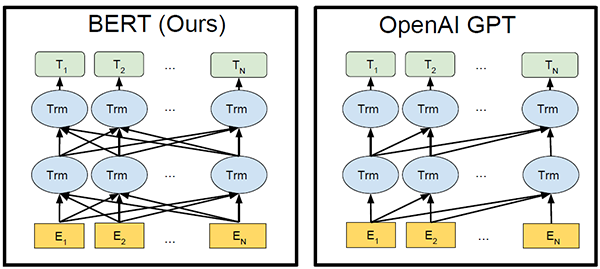
最近openAI基于GPT的擴展又公布了新的通用NLP模型—GPT-2,無需預訓練就能完成多種不同任務且取得良好結果,這個我們保持關注。言歸正傳,bert拋棄了傳統的單向語言模型,創新性的提出了MLM語言模型,類似于word2vec中的CBOW模型,利用窗口內的上下文來預測中心詞,同時引入預測下一句文本的子任務,有效解決了預測單詞這種細粒度任務不能很好編碼到句子層級的問題。
BERT從頭訓練的代價十分高昂,好在google開源了中文的預訓練模型參數,所以本文直接用小店的商品標題語料對預訓練好的模型進行fine-tune。
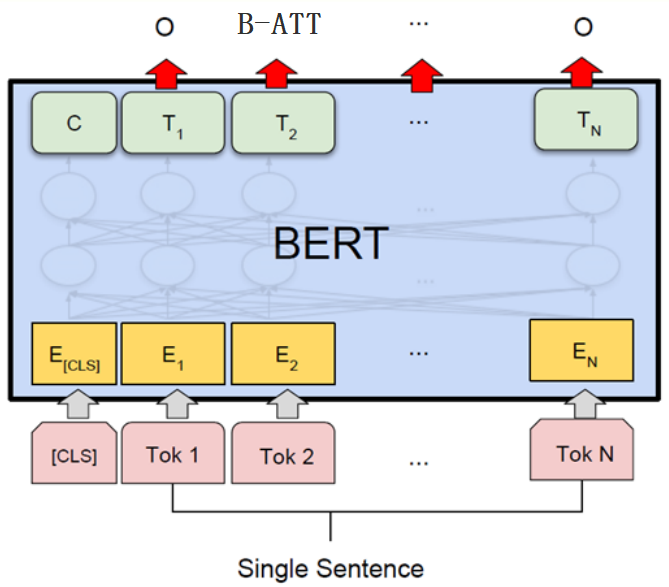
數據按照one-hot預處理好后喂給BertModel,再將模型輸出的sequence embedding傳入下游的B-LSTM+CRF,最終的標注結果相對實驗3(word2vec+字+Y)提升2.002%,足以說明BERT的強大。
總結
深度學習較強的參數擬合能力,省去了許多繁瑣的特征工程工作。本文介紹了幾種常見的預訓練方式,闡述了算法的基本原理并應用于蘇寧小店商品標題的知識抽取任務。蘇寧搜索團隊在NER、關系抽取、事件抽取、共指消解等知識挖掘的子任務有很多的嘗試與實踐,限于篇幅本文不做介紹,歡迎讀者關注后續的文章分享。
參考文獻
1、Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[J]. arXiv preprint arXiv:1603.01360, 2016.
2、Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations[J]. arXiv preprint arXiv:1802.05365, 2018.
3、Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
4、https://github.com/allenai/bilm-tf
5、https://allennlp.org/elmo
6、張俊林. 從Word Embedding到Bert模型——自然語言處理預訓練技術發展史
7、DL4NLP —— 序列標注:BiLSTM-CRF模型做基于字的中文命名實體識別
8、簡書 御風之星.BiLSTM模型中CRF層的運行原理
9、The Annotated Transformer
10、Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J].
作者簡介
呂建新,蘇寧搜索研發中心算法工程師,主要從事語義理解、知識圖譜、對話系統等研發工作,在知識抽取與挖掘、圖表示學習、遷移學習等傳統機器學習、深度學習領域有豐富實戰經驗。
李春生,蘇寧易購搜索技術總監,負責商品、情報與搜索技術線架構設計與核心技術規劃等方面的工作,在搜索領域有多年的實戰經驗,從0到1構建蘇寧易購搜索平臺,在搜索領域上耕耘7年有余,精通搜索架構設計與性能優化,同時在機器學習、大數據等領域對搜索的場景化應用有豐富的經驗。
孫鵬飛,蘇寧易購搜索算法團隊負責人,專注于NLP,搜索排序,智能問答方向的研究。帶領團隊從無到有搭建了搜索排序系統、個性化系統、智能搜索系統、反作弊系統等。對算法在產品中的調優及工程應用實踐上有著豐富的經驗。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】