億萬人搶10億紅包的數據監控,如何實現業務零資損?
一、什么是HTAP
1、OLTP與OLAP
在介紹HTAP概念之前,請允許我先介紹一下另外兩個概念——OLTP和OLAP,這兩者在數據庫領域是很重要的應用場景的劃分。
OLTP數據庫承載的應用通常是高并發、高吞吐、高可用的,應用SQL很簡單(大部分都是點查點寫),但這種應用對數據的實時性、一致性要求很高,對查詢時間延遲很敏感,一般要求是幾毫秒以內。
相反地,OLAP數據庫承載的應用的SQL通常會比較復雜(多含Join、GroupBy或SubQuery等復雜語法),所涉及到都是大范圍的數據讀取,數據量可能是百萬千萬,甚至億,所以這種SQL查詢延時比較大,但應用并發不高。
由于OLTP與OLAP這兩類數據庫所應對的場景的巨大差異,因此兩者在查詢優化策略、數據組織方式與物理存儲結構都會不一樣。在企業內部,OLTP與OLAP一般都是獨立的兩套系統。所以,業務上常見的做法,就是配置一條數據同步鏈路,把OLTP數據庫每天產生新數據同步到OLAP數據庫,以方便進行做統計分析的工作。
舉個例子,我們在盒馬鮮生用手機APP做商品查詢、下訂單和付款,這就是OLTP的業務。盒馬鮮生將MySQL產生的數據通過阿里集團數據同步工具(精衛同步、云梯等)導入到ODPS平臺(阿里集團Hadoop平臺),進行每天的庫存結算對賬、各渠道銷售額統計等,這都是業務里的OLAP業務。
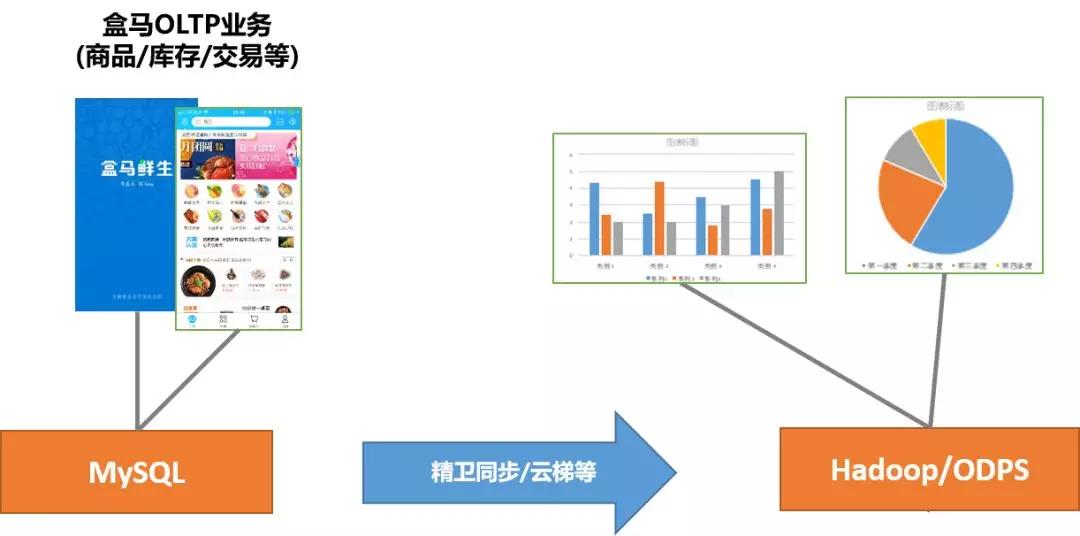
業務上將OLTP數據復制一份并導入到給OLAP,達到OLTP與OLAP相互隔離的效果,這個方案很通用,但這有一個代價--應用的開發人員要額外負責承擔這些數據同步鏈路穩定性的保障性工作,那必然會帶來其它很多不可忽視的問題。
首當其沖的是數據質量的下降以及運維成本的上升。業務以后每加一個新的數據庫或新增一張表,表就要新配一條數據的同步鏈路,像盒馬已經有幾十個業務同步鏈路、幾百張表,這樣數據同步鏈路的維護成本很高。
比如,某個需求需要給某個表加個列、改列名等DDL操作,同步鏈路的工作都需要暫時,等到完成了才能重新開始。這中間的過程容易遺漏導致故障。
一般來說,根據數據量的大小,同步系統會有分鐘級、小時級甚至天級的時間延遲。因此,同步后的數據的時效性是比較差的。
同步鏈路的上下游系統一般眾多,如果中間某一個系統因為程序Bug導致數據丟失或不可用,就可能會直接產生嚴重的數據故障。這對業務的穩定性帶來很大的風險。
此外,同步鏈路上下游各系統不一定兼容MySQL協議,這樣開發人員還可能要修改業務代碼適配這類系統,從而帶來額外的開發成本。
為了解決這一系列的問題,HTAP數據庫就剛好可以派上用場。
2、HTAP簡介
HTAP數據庫簡單理解就是OLAP業務和OLTP業務都統一地在一套數據庫系統里內完成。HTAP數據庫相對于傳統TP數據庫有TP所不具備的計算引擎,可以加快SQL執行效率,而HTAP數據庫基于于傳統AP數據庫,又有AP所不具備的事務引擎,能做到所寫即可見,數據具有高時效性。
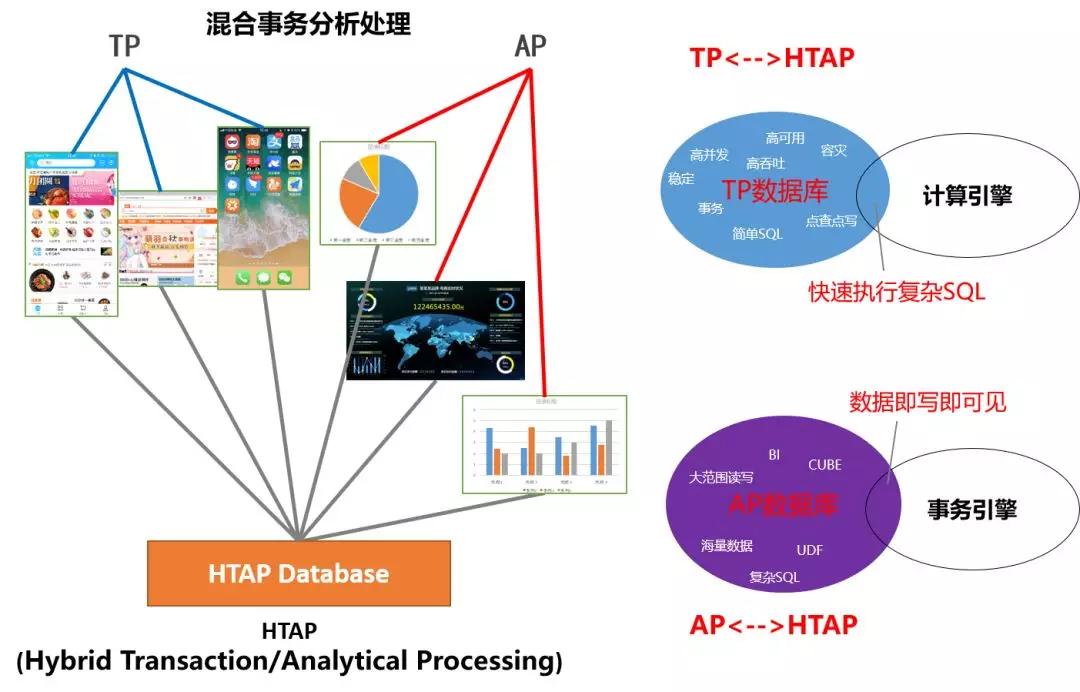
HTAP型數據庫可以具備哪些技術點呢?以下是我們對它的幾點總結:
- TP/AP數據時效性:簡單說,就是業務的TP查詢和AP查詢看到總是“同一份數據”,不會有明顯的延遲。目前成熟的MySQL主備同步機制能保證數據延遲達到毫秒級或亞秒級,用戶幾乎不會察覺,并且同步準確性非常高,這比依賴于異步的外部數據同步系統的可靠性高很多;
- TP/AP 穩定性與高可用:TP與AP兩者相互隔離,保證各自的穩定可靠是HTAP的基本要求。要做到這一點,可以基于獨立部署進行物理隔離,也可以基于鏈路隔離以及備庫自動容災與切換方案進行隔離;
- 跨業務庫的關聯查詢:跨業務庫關聯分析是HTAP常見場景,這要求HTAP查詢引擎能基于MySQL協議對接不同的類MySQL存儲;
- 復雜SQL處理能力:除了要有強大的優化器之外,MPP計算引擎和Streaming的計算引擎等加速SQL執行的手段也必須要有的。
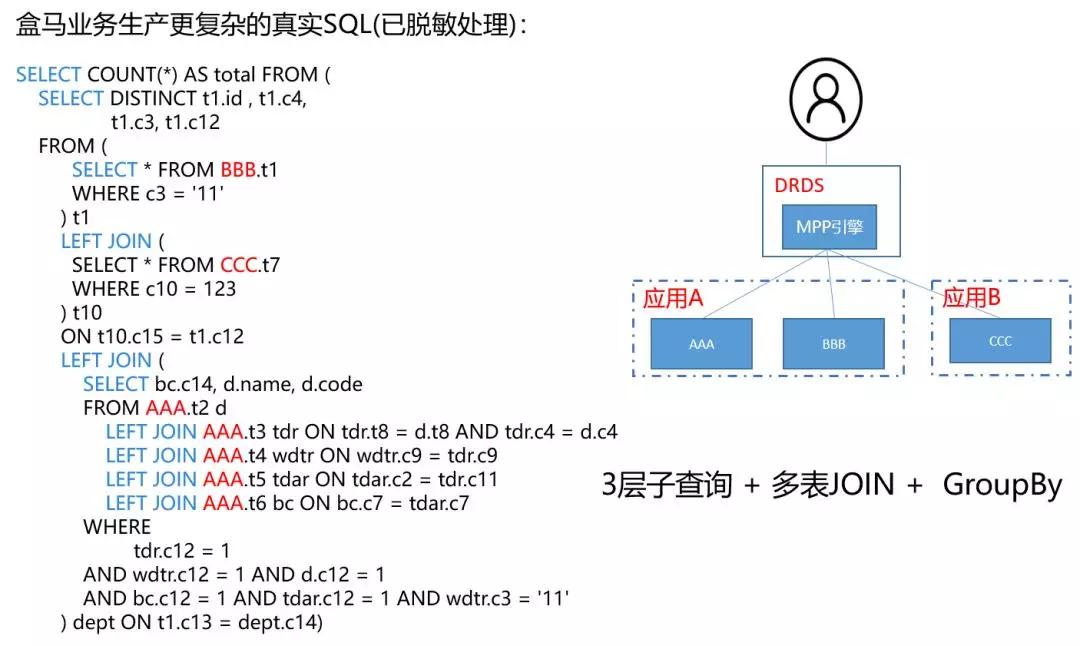
舉個HTAP的應用例子。雙11主互動及合伙人集能量的搶紅包活動,活動在設計時已經涉及到10多個業務的數據庫,活動參與的任務有億萬紅包金額,所以這個活動的業務邏輯是很復雜的。
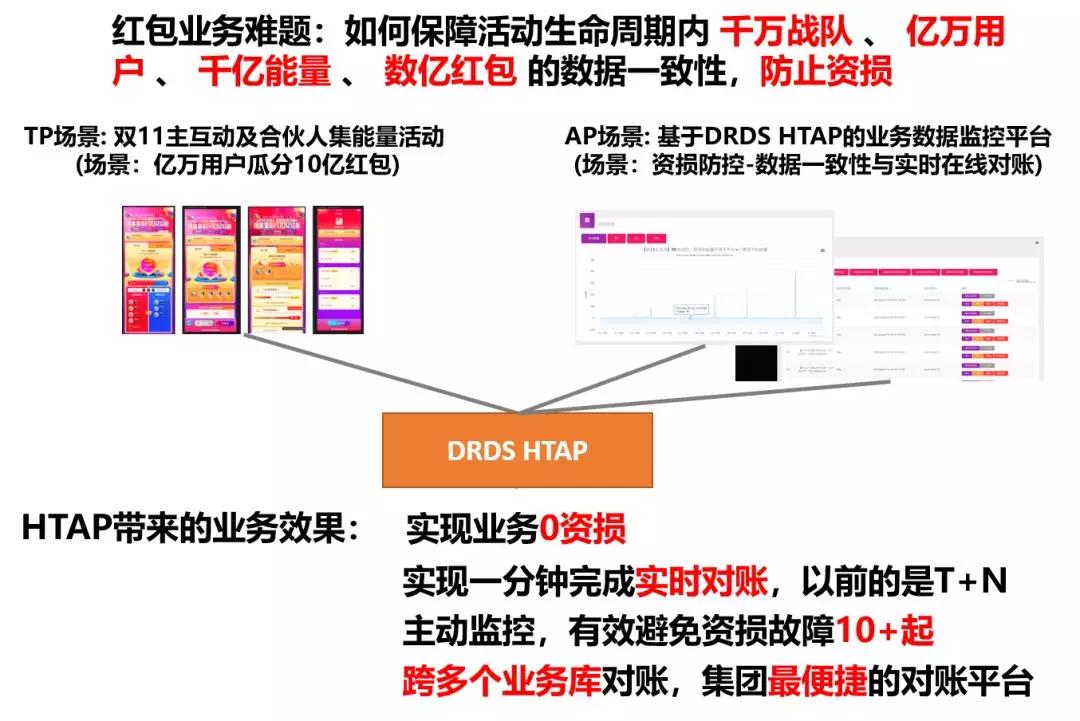
在這樣復雜的場景中,業務如何做到快速的業務監控以及資損防控是整個活動***的技術挑戰。業務開發在進行方案調研的時候發現DRDS HTAP這個產品,除了具有承載普通的OLTP的能力外,還具有跨多個數據庫做實時關聯分析的能力,非常符合業務的場景。
因此,開發同學直接將業務的監控系統直接基于DRDS HTAP來搭建,***的結果超出他們期望。
DRDS HTAP不但幫助業務監控平臺成功避免了10+起的資損故障的出現,還具備了在1分鐘以內完成多個業務庫實時對賬的能力,這相比于以前的離線方案,要將數據要上傳到數據倉庫里,像對賬這種操作需要在T+1、T+2的時間才能完成。
那么HTAP是如何達到這種效果的呢?下面一起來看一下DRDS HTAP的架構和關鍵技術。
二、DRDS HTAP架構與關鍵技術
下圖是DRDS HTAP的技術架構圖,架構圖分為兩層——引擎層和存儲層:
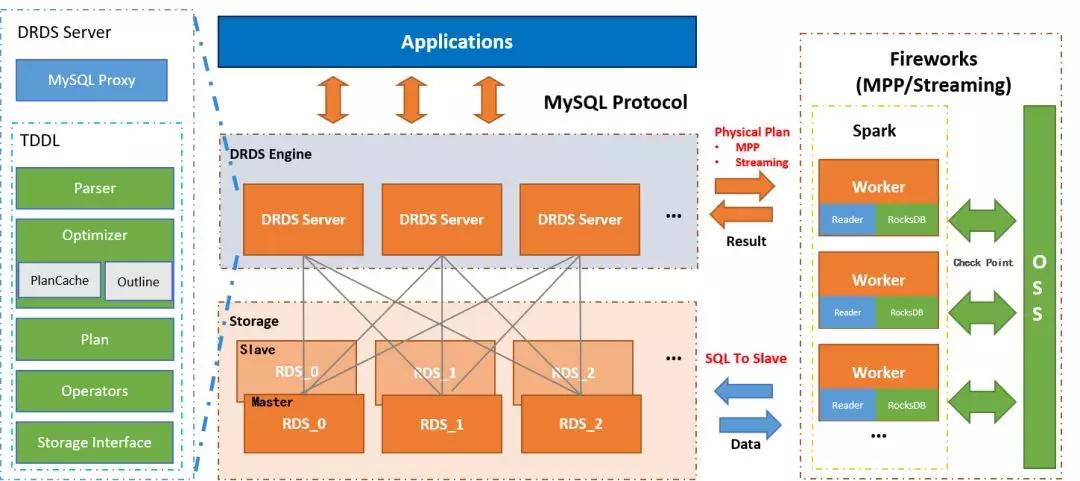
橙色的一層是存儲層,這層一般都是DRDS HTAP分庫分表的MySQL實例(云上就是RDS實例),通常每一個物理分庫都會配一主多備保證高可用。灰色的一層是引擎層, 引擎層使用集群提供高可用,集群的每一個節點都DRDS的無狀態的Server節點。Server里包含了用于處理MySQL協議的網絡模塊、查詢優化器以及一整套TP引擎對應的執行算子。
通常業務OLTP類的SQL在Server的TP引擎內完成全部執行。但如果業務的SQL是OLAP類的復雜SQL,引擎層會將SQL對應的物理查詢計劃發到右側Fireworks引擎進行計算。
Fireworks是一個基于Spark 的具有DAG能力并行執行引擎,它能夠進行MPP計算及Streaming計算。Fireworks內部的每一個Worker會主動連用戶MySQL的備庫獲取數據并進行計算。
DRDS HTAP 的Fireworks引擎的細節如下圖所示:
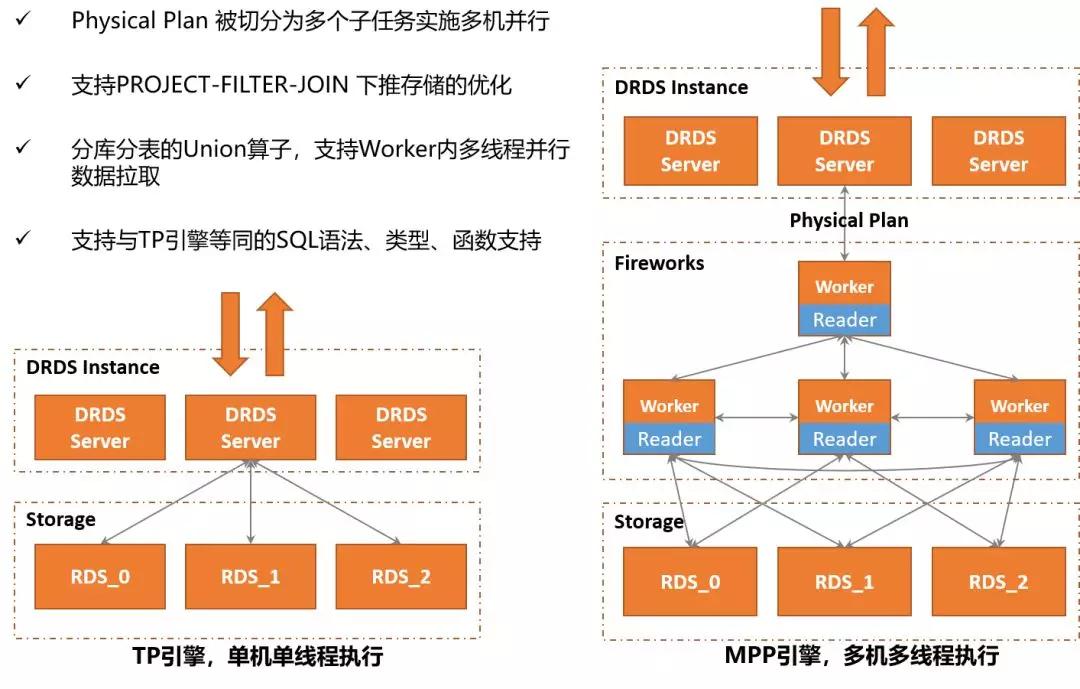
左右兩圖是一條SQL分別在TP引擎的對比圖。在TP引擎中,SQL采用單機單線程執行策略。但是,在Fireworks引擎中,SQL的物理查詢計劃會被拆分為多個子任務,然后分發到多臺Worker機器實施并行計算。
值得提及是,相比于開源Spark的Worker只能下推PROJECT/SELECT兩種算子,Fireworks的Worker接收到的物理執行計劃是被DRDS優化器進行過優化的。
因此,一些常見的PROJECT/SELECT/JOIN(分庫內的JOIN)/AGGREATION(分庫內的AGG)/SORT等算子操作,都會被DRDS優化器盡可能下推到物理存儲,這樣可以避免大量的中間數據的網絡開銷以及本地計算開銷,從而使MPP引擎執行得到加速。
對于有一些需要跨多個分庫分表讀取數據才能完成的查詢, Worker機器都會采用多線程并行掃描單個分片數據,以避免查詢時間大量耗在網絡IO上 。
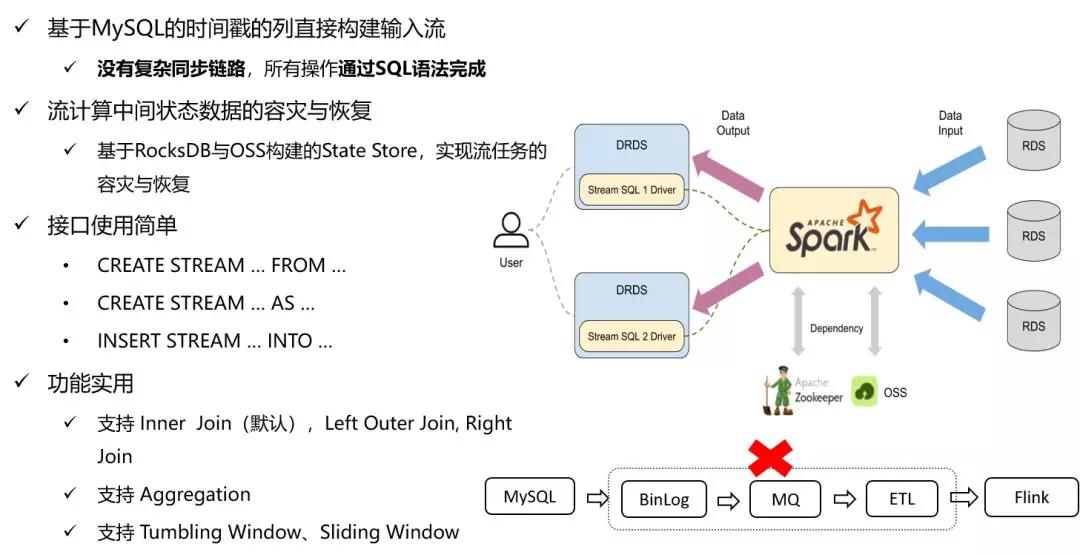
再說一下DRDS HTAP Streaming的引擎,DRDS HTAP的Streaming引擎是在Spark Streaming的基礎上開發的。但我們在將Spark Streaming引入DRDS HTAP體系過程中,對Streaming的穩定性與可靠性做了很多優化工作。
例如,DRDS HTAP引入了RocksDB作為Streaming的State Store,并實現流計算任務中間關態的自動容災與恢復。又如,DRDS HTAP基于MySQL的Schema的時間戳列實現輸入流。
這樣用戶在DRDS HTAP可以使用標準的Streaming SQL語法完成諸如 Streaming-Streaming JOIN常見Streaming計算操作。業務開發也不再需要像使用開源的Streaming引擎(如Flink)那樣,需要自己配置復雜數據同步鏈路,從而能給用戶使用帶來極大的方便。
在HTAP里保證業務TP和AP查詢穩定及高可用是非常重要的,DRDS為達到這個目標,采用了查詢鏈路隔離的技術方案。下圖是鏈路隔離方案的架構,分為引擎層和存儲層:
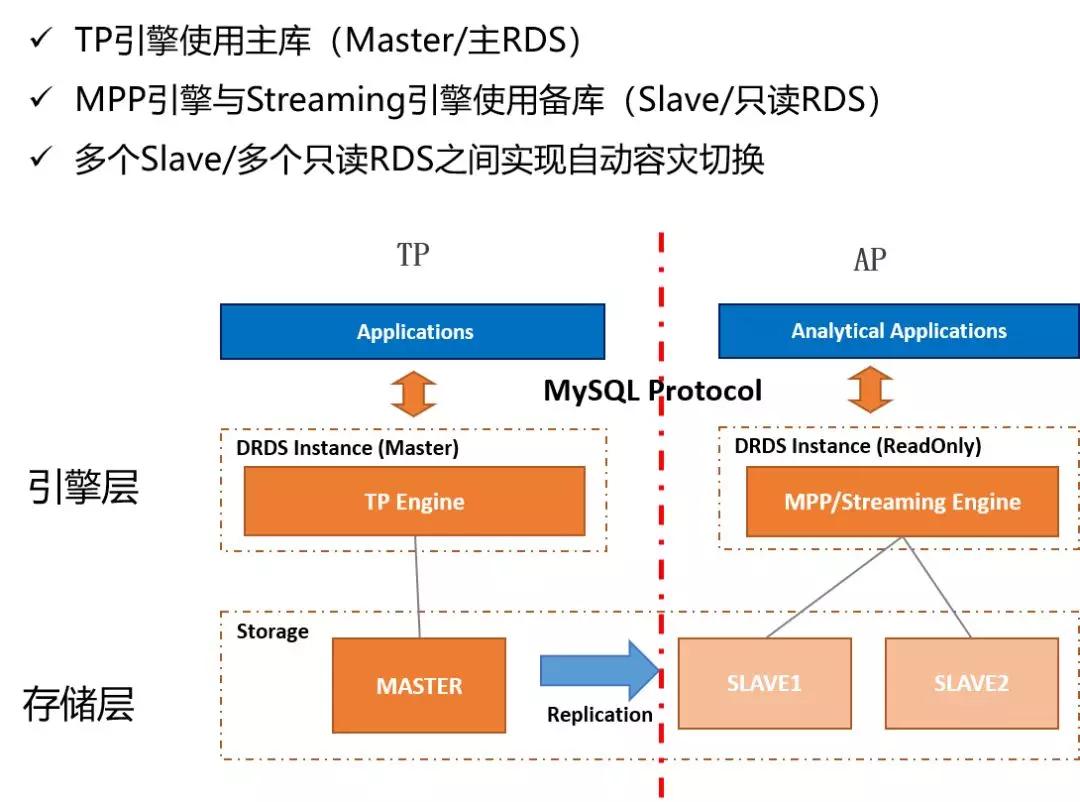
在存儲層默認用MySQL的一主多備來實現。像TP引擎會默認只訪問主庫,這樣數據可以保持是保持數據一致性。而像Fireworks引擎默認只允許訪問應用的備庫,這樣業務在存儲層AP流量和TP是天然的物理隔離,保證相互不受干擾。
由于備庫承載的是OLAP類的SQL, SQL通常有相當的復雜性,備庫被打垮是高概率事件,所以,DRDS HTAP能在多個備庫之間實施自動的容災和切換,這樣就算一個備庫宕機了,另一個備庫也可以繼續提供服務,從而高可用。
在引擎層,DRDS通常建議業務將OLTP流量用DRDS主實例來承載,業務的OLAP流量用DRDS只讀實例來承載,這樣業務的AP和TP業務就能在引擎上也能實現物理隔離,從而保證各自的穩定性和高可用。
接下來看一下DRDS HTAP的查詢優化器,下圖是查詢優化器的架構,優化策略是以RBO為主,CBO為輔的策略。優化過程可以分為三個階段:
- PreOptimizer,Sql的很多Rewrite操作(例如, SubQuery Unnesting/Constant Folding等)會在這個階段完成,產生出一份經過簡單SQL改寫的邏輯計劃;
- Optimizer,這個階段優化器會進行很多常見算子優化(例如,Predicate Inference /Operator Pushdown/Column Pruning/Join Cluster /Join Reorder等),然后再產生出一份經過優化后的邏輯計劃;
- PostOptimizer,這個階段DRDS HTAP作為分布式查詢引擎所特有的階段。這個階段中,優化器會基于SQL的查詢條件進行分庫分表的Sharding計算,然后再針對特定分片重做類似上一階段的Partition-aware的優化操作。
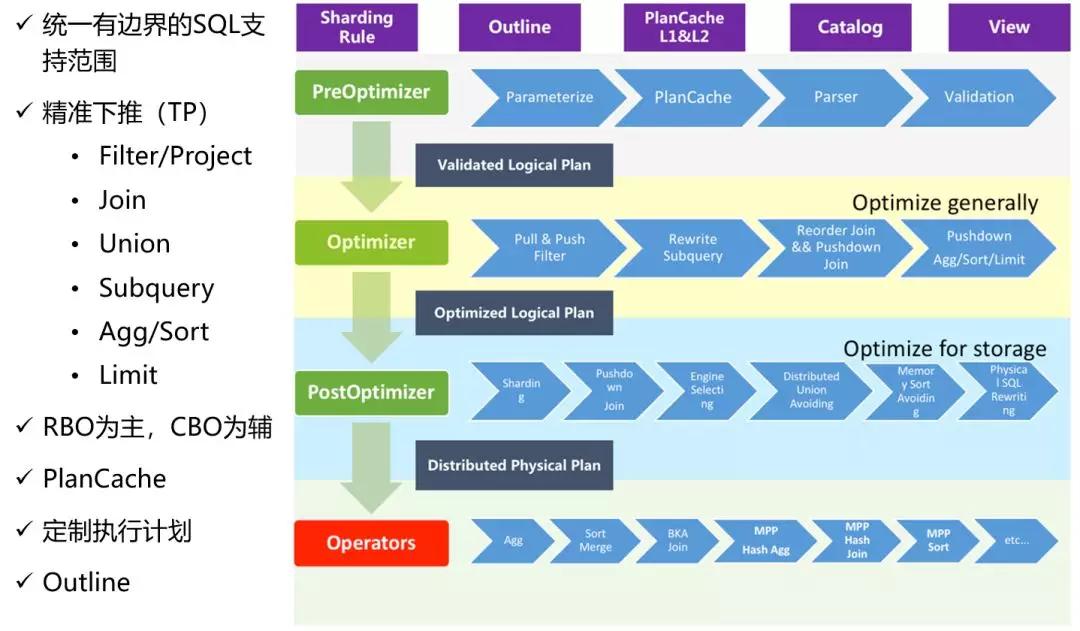
原則上,優化器會盡可能地算子下推到物理存儲,這樣可以大大減少引擎成本的執行壓力以及中間數據的網絡傳輸代價,從而提升執行效率。
對于一些諸如必須要跨多個物理分片的或跨多個邏輯庫才完成計算的算子(如跨庫JOIN), 它們沒法下推物理存儲的,優化器會自動采用MPP的執行策略,直接將物理計劃發給Fireworks引擎做MPP計算。
三、DRDS HTAP功能演示
1、跨業務庫的MPP查詢
在電商場景,業務系統里為了降低耦合性, 通常被會拆分成很多子系統。下圖就是模擬電商場景分別對交易庫、商品庫、用戶庫進行關聯查詢的示意圖,各個子系統會使用單獨MySQL實例(即RDS實例)進行存儲:
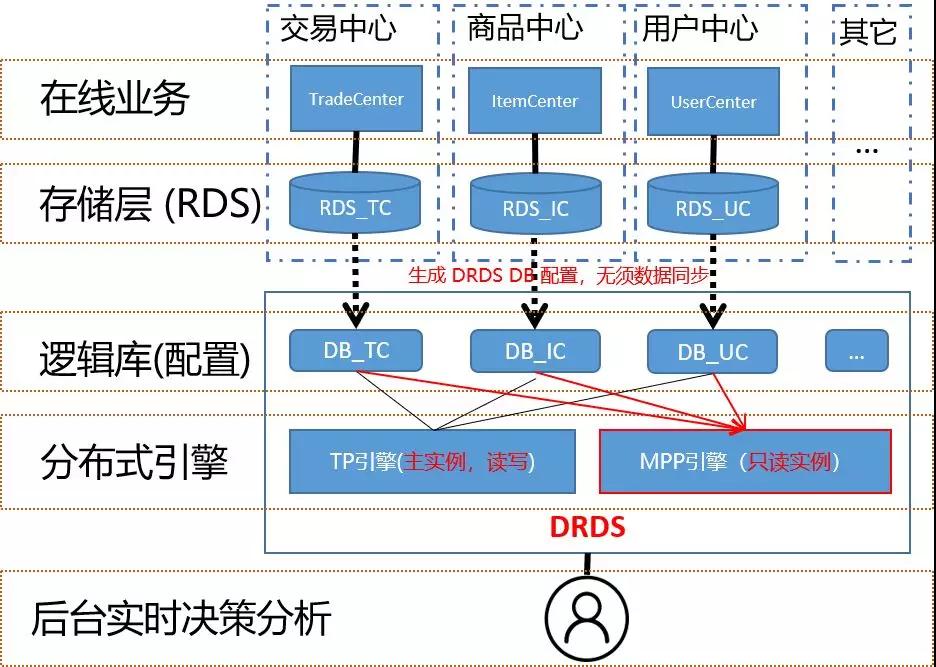
一旦業務要搞營銷活動,如雙11大促、發紅包等,應用的邏輯必然會涉及到多個數據庫實例的讀寫,由于MySQL本身是不能支持跨實例級別的關聯聚合查詢的,這會對業務后臺的數據分析、監控、對賬等場景會帶來很大的麻煩,而使用DRDS HTAP則可以解決這個問題。
DRDS對于每一個RDS數據庫會統一抽象成邏輯庫的概念,簡單理解,就是會為每個庫生成一份配置信息和元數據,在整個過程中用戶本身并不需要做任何數據導入或數據同步的操作。
基于這一層邏輯庫的抽象,普通用戶可以如同在單機MySQL一般地隨意執行跨DRDS數據庫的關聯分析查詢,并且不需要對業務的數據庫任何其它改造,帶來極大的使用便利。
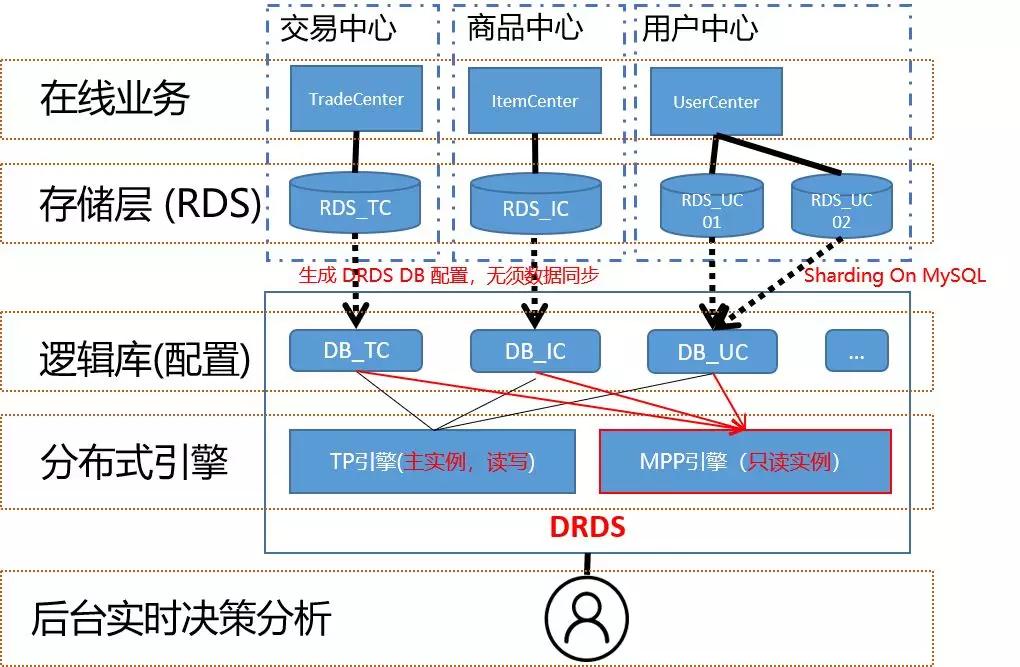
業務將多個RDS的數據庫(不做分庫分表的拆分)接入DRDS后,當其中某個業務數據庫因業務發展了,單機RDS無法承載并需要做分庫分表時,那DRDS的所有拆分的細節會隱藏在一個邏輯庫之下。
這一過程本身應用是透明的,因此,業務后臺的分析應用的SQL也不需要做改造, 從而避免了大量的SQL改造成本。
為了演示方便我已經提前將交易庫、用戶庫、商品庫的表信息建好。其中交易庫和用戶庫分別在RDS A上,商品庫在RDS B上。右邊的SQL是一條跨三個業務庫做JOIN SQL。
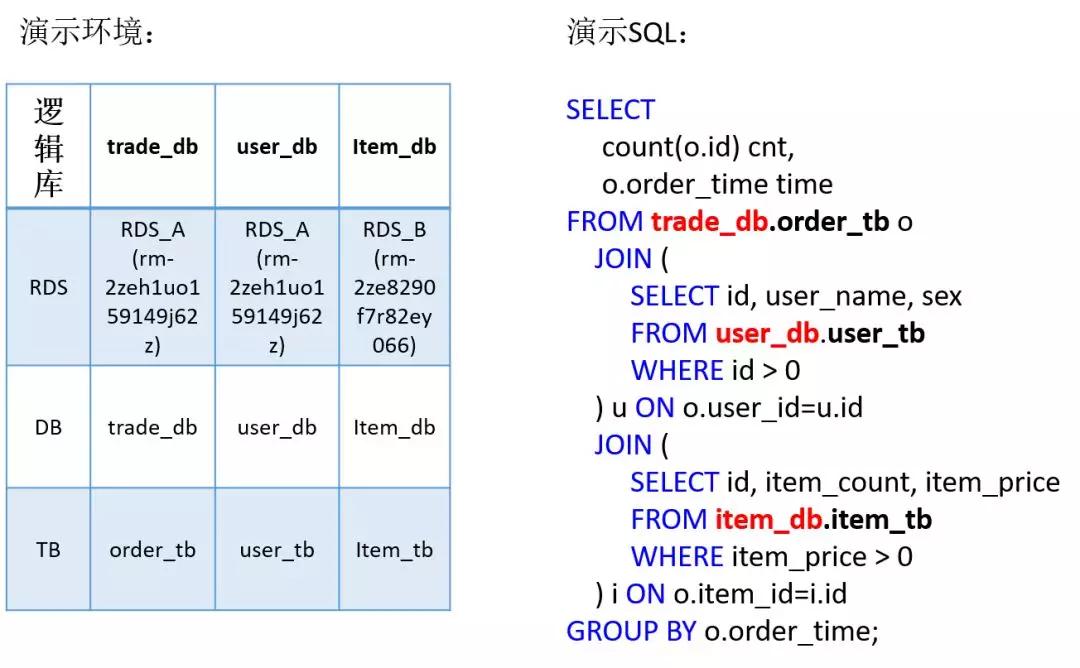
首先我分別登到RDS A和 RDS B的信息,可以看到上面數據庫的信息。RDS A有交易庫和用戶庫,RDS B有商品庫。再通過命令登錄到DRDS里,可以看到三個庫都在同一個地方。***會出現一個結果,這就是我要演示的跨多個業務庫進行復雜查詢的場景。
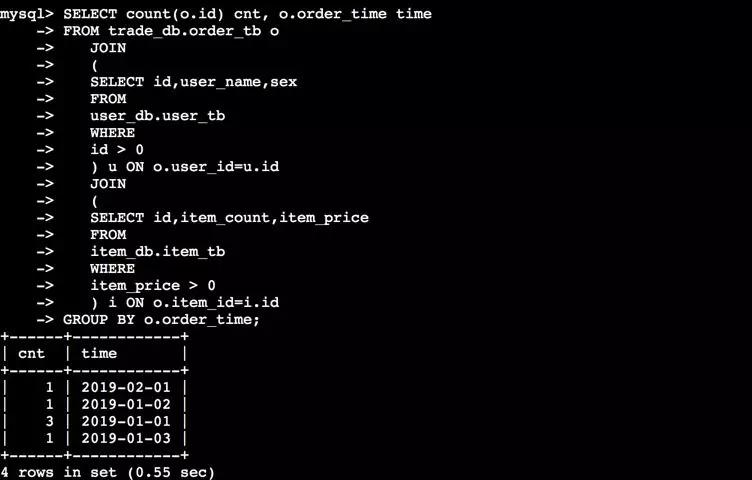
在實際場景中SQL會更為復雜,比如說盒馬聚合查詢的SQL,如果要用以前那種方案,業務肯定要導到統一的數據倉庫才能執行,現在在DRDS HTAP上只冉一條跨Schema的SQL查詢就可以完成,這樣在保證用戶子系統獨立性的同時給實時分析帶來了很大便利。
2、Streaming Join
再看一下Streaming引擎的功能演示,這里要演示的場景是大寬表。很多應用在數據庫表設計的時候會遵守一些標準的設計范式。
比如,用戶購買下單的行為會將用戶的詳情、商品的詳情與用戶下單的行為用三張不同的表存儲,用戶后臺做數據分析的時候會通過JOIN打成大寬表,這樣做方便做上鉆分析或下鉆分析。
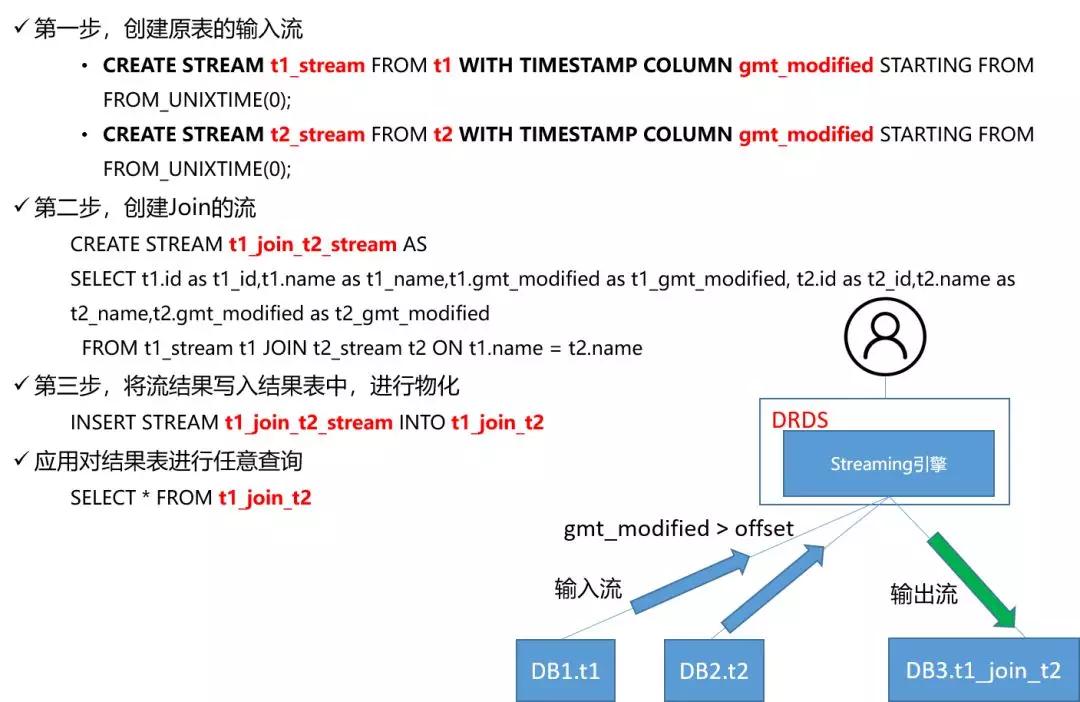
我要模擬的場景是怎么使用流JOIN來打大寬表,Streaming很適用用于跟時間強相關的JOIN查詢。例如,每天都要查一下最近一天的交易量、訂單量的新增數目等。整個演示場景先是假設T1跟T2表是已經存在的表,再額外建一張結果表,結果表是可以用來固化做流式業務的結果。

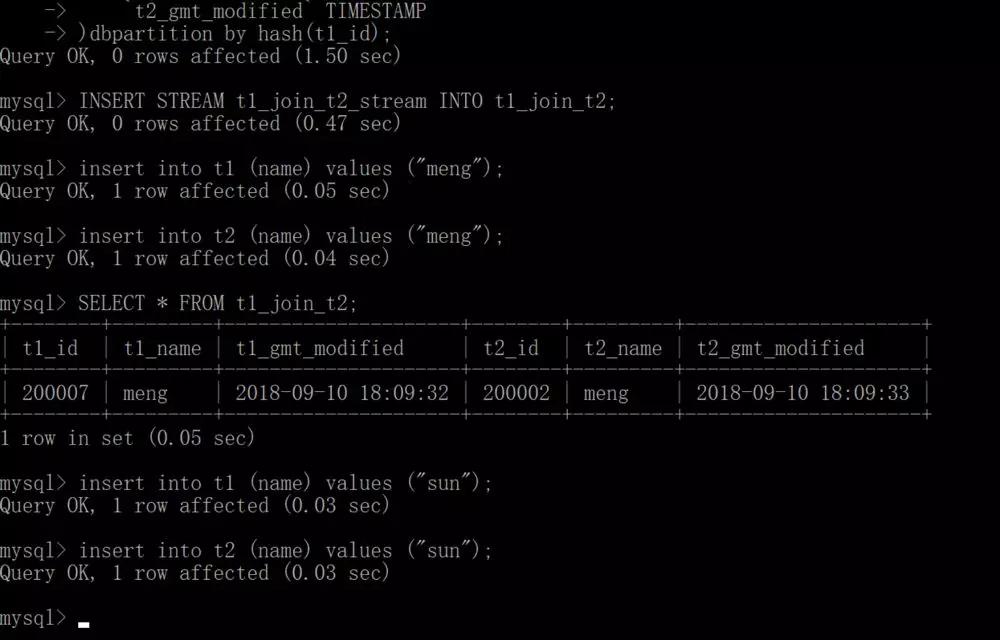
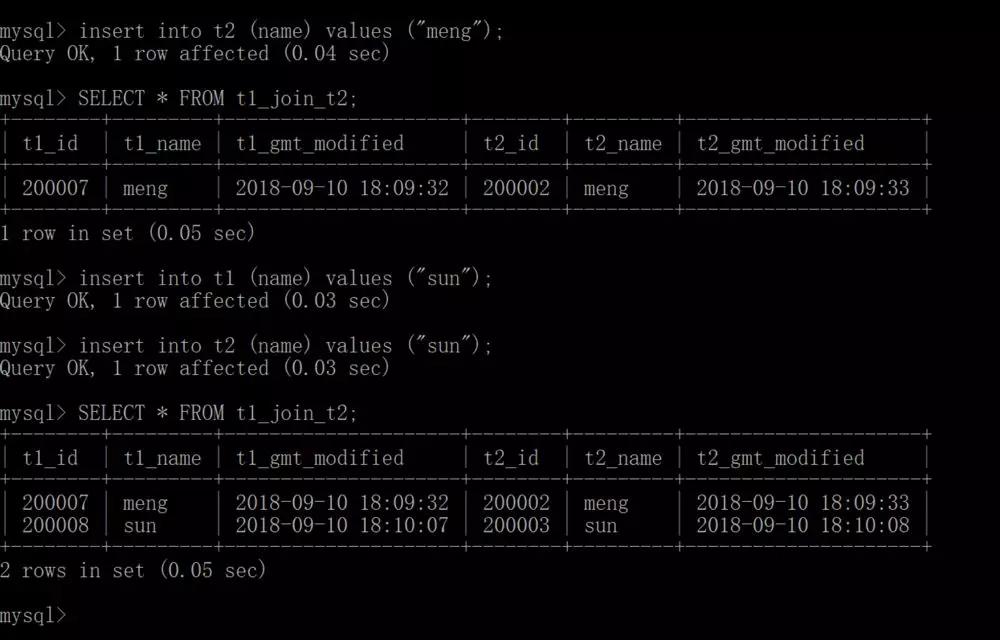
我開始模擬一個普通用戶在DRDS HTAP上使用Streaming JOIN。首先會在CERATE STREAM上建設T1和T2,***使用JOIN建T1 JION和T2 Stream。***將流結果寫入結果表中。
看一下SQL的具體操作,先使用命令執行建了兩個流T1和T2,再建一個T1和T2 JOIN的流。現在模擬向T1、T2引入數據,你會發現有JOIN的結果出來。這樣的好處在于這種結果突然固化業務做查詢可以非常快速,因為不需要再做中間的計算。
四、DRDS HTAP使用場景與限制
沒有數據庫能適用所有的業務場景,DRDS HTAP同樣也是。DRDS HTAP適用AP類場景(TP類場景這里先忽略)主要有兩個:
- 那些低并發且對時延要求不是特別高的應用,特別有跨多個業務庫、跨多個表進行實時分析的場景;
- 基于時間做流式JOIN的場景,例如事實表的流Join或者維表和事實表的流Join也適合用DRDS HTAP來使用。
但是OLAP的查詢場景是多種多樣的,還有很多查詢場景對于DRDS HTAP還不太適合, 比如,常見的全文快速檢索、AdHoc等查詢場景。
目前,DRDS HTAP在公有云已經以分析型只讀實例的方式向用戶開放。但DRDS HTAP后續會在技術層繼續不斷優化,以支持更多更復雜的在線場景與分析場景。
講師介紹
梁成輝(城璧),阿里數據庫事業部技術專家,阿里分布式數據層中間件TDDL、云產品分布式關系型數據庫服務DRDS技術負責人。曾多次擔任數據層穩定性負責人并保障雙十一TDDL & DRDS的穩定性,目前主要聚焦在DRDS HTAP的技術研發,致力于提供云上OLTP與OLAP一體式解決方案。