牛逼了,用Python寫個會做詩的機器人
上一次的聊天機器人,大家關(guān)注度非常的高,閱讀量破萬了(不到20行代碼,用Python做一個智能聊天機器人),通過簡單的代碼就能實現(xiàn)一個簡單的聊天機器人,今天小編就帶領(lǐng)大家,利用自然語言處理技術(shù)和聊天機器人結(jié)合,做一個自動做詩的聊天機器人。
1.原理介紹
首先,讓機器自動做詩,就需要運用自然語言處理的手段,讓機器能夠?qū)W會理解“詩句”,進而做出我們需要的詩句。如何讓機器“理解”詩句呢?我們用到了深度學(xué)習(xí)中的長短期記憶網(wǎng)絡(luò)(LSTM)。有點暈,不要急,我們后面會用白話給大家解釋。
LSTM是循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)的一種變形,RNN能夠很好的解決自然語言處理的任務(wù),但是對于長依賴的句子表現(xiàn)卻不是很好,例如:

上面的例子中后面使用“was”還是“were”取決于前面的單復(fù)數(shù)形式,但是由于“was”距離“dog”距離過長,所以RNN并不能夠很好的解決這個問題。
為了解決上述的問題,便引入了LSTM,為了更加直觀的解釋,我這里引入一個不是很恰當(dāng)?shù)睦?
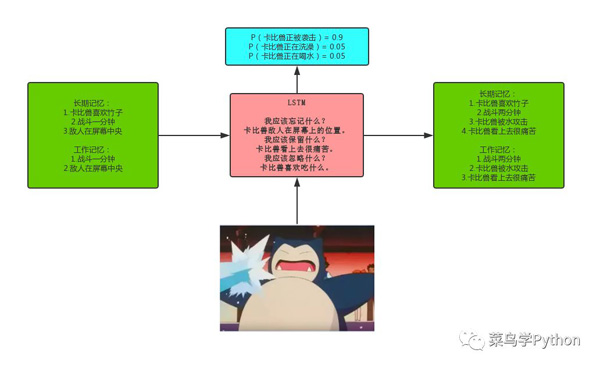
比如我們正在看一場電影,我們能夠通過鏡頭的切換來了解故事的進展。而且隨著故事的發(fā)展,我們會知道某些主角的性格,年齡,喜好等等,這些都不會隨著鏡頭的切換而立馬被忘掉,這些就是長期記憶,而當(dāng)故事發(fā)生在某個特定的場景下,比如下面喜洋洋的這張圖:
通過我們對于這部動漫的長期記憶,我們知道這是喜洋洋在思考,而在這個鏡頭中,我們利用到了長期記憶中關(guān)于“喜洋洋思考動作”的記憶,而在該鏡頭下需要被用到的長期記憶就被稱為“工作記憶”。
2.白話解釋LSTM
那么LSTM是如何工作的呢?
1).首先得讓LSTM學(xué)會遺忘
比如,當(dāng)一個鏡頭結(jié)束后,LSTM應(yīng)該忘記該鏡頭的位置,時間,或者說忘記該鏡頭的所有信息。但是如果發(fā)生某一演員領(lǐng)了盒飯的事情,那么LSTM就應(yīng)該記住這個人已經(jīng)領(lǐng)盒飯了,這也跟我們觀看影片一樣,我們會選擇忘記一些記憶,而保留我們需要的記憶。所以LSTM應(yīng)該有能力知道當(dāng)有新的鏡頭輸入時,什么該記住,什么該忘記。
2).其次是添加保留機制
當(dāng)LSTM輸入新的鏡頭信息時,LSTM應(yīng)該去學(xué)習(xí)什么樣的信息值得使用和保存。然后是根據(jù)前面的兩條,當(dāng)有新的鏡頭輸入時,LSTM會遺忘那些不需要的長期記憶,然后學(xué)習(xí)輸入鏡頭中哪些值得使用,并將這些保存到長期記憶當(dāng)中。
3).***是需要知道長期記憶的哪些點要被立即使用
比如,我們看到影片當(dāng)中有個人在寫東西,那么我們可能會調(diào)用年齡這個長期記憶(小學(xué)生可能在寫作業(yè),而大人可能再寫文案),但是年齡信息跟當(dāng)前的場景可能不相關(guān)。
4).因此LSTM只是學(xué)習(xí)它需要關(guān)注的部分,而不是一次使用所有的記憶。因此LSTM能夠很好的解決上述的問題。下圖是對于LSTM的一個很形象的展示:
3.實戰(zhàn)機器人
下面便是實戰(zhàn)的環(huán)節(jié),雖然LSTM效果非常出色,但是仍舊需要對于數(shù)據(jù)的預(yù)處理工作,LSTM需要將每個詩句處理成相同的長度,而且需要將漢字轉(zhuǎn)換成為數(shù)字形式。那么如何進行預(yù)處理呢,主要分為3步 :
- 讀入數(shù)據(jù),我們收集了眾多的詩詞數(shù)據(jù)
- 統(tǒng)計每一個字出現(xiàn)的次數(shù),同時以其出現(xiàn)的次數(shù)作為每個漢字的id。
- 在產(chǎn)生批量數(shù)據(jù)的時候,我們需要將每一個詩句的長度都統(tǒng)一到同樣的長度,因此,對于長度不夠的句子,我們會以“*”進行填充
- 所以在***的效果展示的時候,可能在詩句中出現(xiàn)“*”的字樣。數(shù)據(jù)預(yù)處理的部分代碼如下圖所示:

上述的代碼中主要完成了下面幾步:
1).首先是讀入數(shù)據(jù),并將句長大于100的進行縮減,刪掉100個字符后面的部分。
2).然后在每個句子的開頭和結(jié)尾加入‘^’和‘$’作為句子的標(biāo)志。對于句長小于MIN_LENGTH的直接刪除
3).***將處理好的詩句,進行字?jǐn)?shù)的統(tǒng)計,統(tǒng)計每個字出現(xiàn)的次數(shù),并按照出現(xiàn)的次數(shù)作為每個漢字的id。
對于數(shù)據(jù)預(yù)處理部分的代碼,我都進行了注釋,方便大家進行理解,對于我們對于數(shù)據(jù)處理,以及python語句的理解都有極大的幫助。
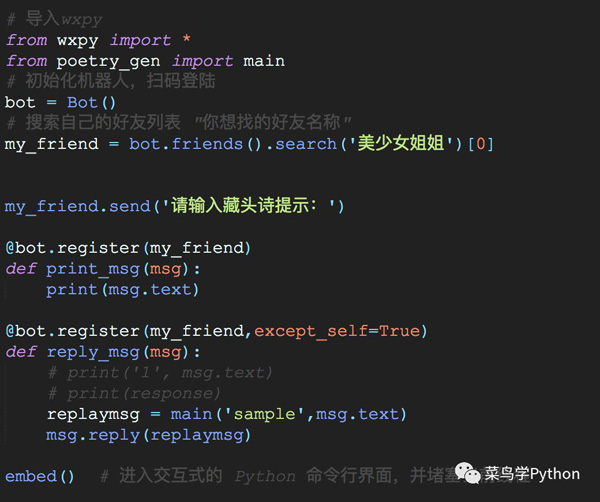
模型的訓(xùn)練,需要確保電腦中已經(jīng)配置了tensorflow和numpy庫。當(dāng)模型訓(xùn)練完成后,我們可以直接對于模型進行調(diào)用,嵌入到我們的聊天機器人程序中,來實現(xiàn)我們的聊天機器人(對于聊天機器人的介紹,可以參照文末歷史文章)。
下面是部分代碼的展示:
4. 效果展示
說了這么多,我們來看一些訓(xùn)練完的機器人作詩的效果
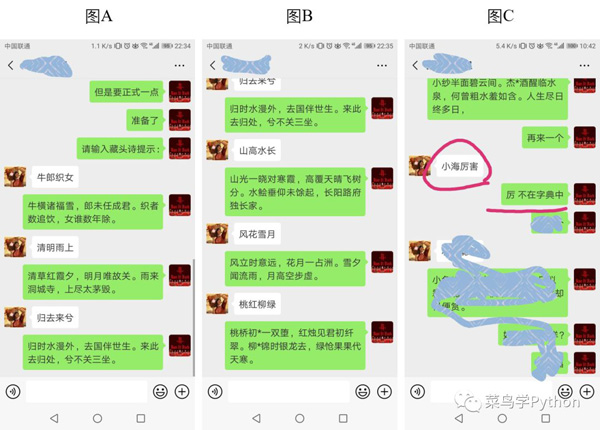
在圖A中展示了做詩機器人效果,機器人輸出“請輸入藏頭詩提示:”,當(dāng)我們輸入藏頭詩提示時,機器人便會做出符合我們要求的藏頭詩。
在圖B中展示了有“*”字符存在的情況,當(dāng)然由于中華文化的博大精深,也受制于訓(xùn)練資料的限制,當(dāng)我們的藏頭詩提示中存在沒有在訓(xùn)練資料里出現(xiàn)的字符時,機器人便會提示該字符不在字典中,
在如圖C中紅色標(biāo)識出來的部分,會處理異常的情況,提示不在字典中!