機器學習能革了數據庫索引的命嗎?
關系數據庫帝國已經獨孤求敗幾十年了!
自從1970年E.F.Codd 的《大型共享數據庫的關系模型》論文橫空出世,為關系型數據庫奠定了堅實的理論基礎,一眾關系數據庫System R,DB2 ,Oracle,MySQL,Postgres相繼誕生,一舉推翻了層次和網狀數據庫的統治。
在過去的幾十年中, 對象數據庫, NoSQL等相繼挑戰,但是依然無法撼動它的地位。
當然關系數據庫也不是停滯不前,它也在進化,統一的SQL標準,強大的事務支持,更加聰明的查詢優化器......
但是帝國也有一個巨大的硬傷,數據都保存在硬盤上,比起內存和CPU來,硬盤實在是太慢了。 如果說內存是火箭的話,硬盤就是驢車。
帝國想出了很多辦法,但總是不能徹底解決問題,到目前為止,一個比較好的辦法就是使用B+樹。
比如有一張表User, 假設它只有兩列(id, age),ID為主鍵Key。
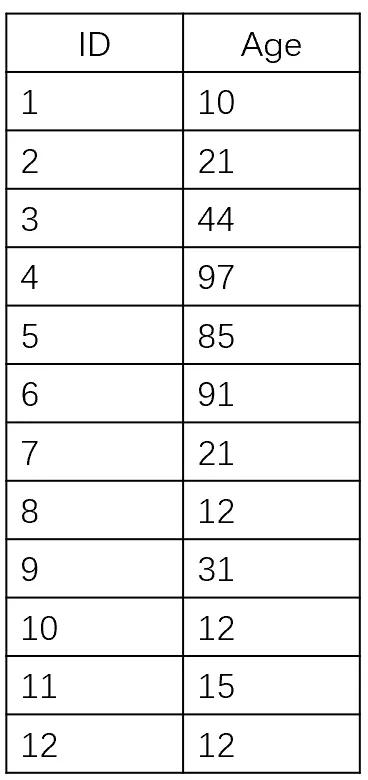
圖1
那么它的B+樹存儲結構為:

(圖2:B+樹中節點也保存在磁盤塊中)
***一層為有序的數據頁,每個頁包含指向下一個數據頁的頁號(也就是地址),這里假設一條記錄占據一個數據頁,那么***條記錄在1號數據頁,第二條記錄在2號數據頁,依次類推。
這樣以來,如果用戶想獲取ID = 4的記錄,數據庫只需要讀取三次磁盤就可以找到記錄所在的數據的頁號(page)為4。

圖3
機器學習大使
這一天, 帝國的早朝上來了一位神秘的客人,號稱是機器學習王國的大使,他自稱帶來了一個咒語,能夠根據一個數據庫記錄的索引列的值(比如主鍵Key=4),瞬間定位到記錄的頁號( page = 4),連那三次硬盤讀寫都不需要。
這絕對是個革命性的技術,國王非常感興趣,下旨讓大使詳細講述。
B+樹大臣馬上就感受到了威脅,如果真有這個咒語,自己官位不保,于是他趕緊阻止:“陛下,老夫有所耳聞,機器學習雖然風靡IT世界,但是也有很多招搖撞騙,不著邊際的故事,這個大使,很有可能就是想推銷幾個鬼都看不懂的數學模型來騙錢!”
國王把沒有說話,把目光射向大使。
機器學習大使臉微微一沉,心中想到,不把這個老頭子搞定,也就無法說服國王, 既然你送上門來,我就拿你開刀吧。
他主意打定,胸有成竹,先給B+樹大臣戴高帽挖個坑: “大人誤會了,小人知道您在數據庫王國是絕對的中流砥柱, 您采用多叉平衡樹的方式,降低了索引層次,減少了硬盤I/O時間,并在葉子節點上維護一個根據key(索引列)排序的線性表(S),獲得了范圍查詢的能力....”
B+樹微微一笑,心想這小子是有備而來啊,懂得不少。
從key直接找到page
然而大使話鋒一變:“但是,說白了,它就是一個通過key獲取數據記錄頁面(page)一個映射關系!而這和機器學習中的回歸要干的事情是一樣的,都是通過一些特征預測目標值,比如通過每個人的年齡,收入等信息預測你的潛力值,只不過說在數據庫這個場景下key是特征,page是目標值。”
B+樹不屑道:“難道機器學習只要是映射就可以學嗎?有點忽悠了吧!”
大使忍住這當面的嘲諷,平心靜氣地說:“您要知道,這個key和page之間是有關系的!而您正是忽略它兩者可能存在的強關聯!。”
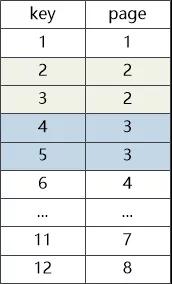
說到這里,大使不知道從哪里變出一塊小黑板,在上面畫了圖2,然后說:“比如說我現在有一堆數據,每條記錄占一個數據頁,他們的key和page之間的關系是這樣的 ”

機器學習大使清了清嗓子:“對于機器學習模型,比如我用一個簡單的線性回歸算法,假定模型為page=a * key + b,而我們當前訓練集,也就是這棵B+樹中key與之對應page數據(1,1),(2,2)…(12,12),也就是說a,b必須得滿足1=a+b,2=2a+b…12=12a+b這12個等式,就相當于我們小時候求解二元一次方程組一般,我們得到a = 1,b = 0, 于是乎我們得到了最終模型page = key!”
應對復雜情況
B+樹大臣冷笑一聲,轉向國王:“陛下,別被他的數學公式蒙蔽,這是騙小孩的把戲!哪有page = key這么簡單的情況! 再說了,這種簡單的情況,還用得著機器學習? 我用肉眼都看出來他們的關系是page=key! 來來來,機器學習大使,我給你說個復雜點兒的情況,如果有些數據頁能裝兩條記錄呢?你給我說說page 和key 之間的關系是啥?”

現在的對應關系不是那么簡單了。
機器學習大使不僅不慢不緊不慢地回答道:“線性模型只是我們大家族中最簡單的地模型罷了,不管你一個數據頁能存儲幾條記錄, 只要給出(key,page)對應的數據集合,我們都可以訓練神經網絡,找到滿足他們之間關系的一個函數 page = f(key)!通過這個函數,只要你給出key的值,立刻就能得出page! ”
B+樹有點明白了,這機器學習就是為了找到一個key和頁面之間的關系啊,以后訪問起來就方便了,他背上開始冒汗了。
機器學習大使窮追不舍,亮出了***殺招:“使用B+樹, 存儲開銷是O(n/m)(m為樹的出度),查詢開銷是O(log(n)), 而使用神經網絡,查詢開銷是O(1) !”
O(1) !
聽到這句話, 全場一片嘩然,所有人都知道這意味著什么,這就是革命呀,革B+樹的命呀!
大臣們開始竊竊私語:“這神經網絡很厲害啊!”
“是啊!神經網絡最擅長干這個事情了!從一堆數據中找到關聯關系。”
“聽說神經網絡在兩層的情況下就能夠擬合一切函數!”
B+樹大臣有點慌,語氣也弱了下來:“你們機器學習是很牛逼,但像LR,GBDT,SVR,包括你說的這些神經網絡,一些深度學習的方法,哪個不是有一定錯誤率的,位置預測錯誤,難道要全部掃描一遍數據不成,你們懂不懂我們索引的業務呀!”
機器學習大使早就預料到了會有這個問題, 他一字一句鄭重道:“將機器學習賦能數據庫,我們是認真的! 傳統這些預測算法的應用場景,都是在訓練數據數據集里做訓練,然后對未知的數據做預測。但索引這個場景,嘿嘿,它是一個封閉場景,沒有新的數據,只需要對數據庫中存在的數據做預測即可,這種場景下,就像我剛才提到的神經網絡完全可以勝任,直接就在當前數據上,訓練到做到***的正確率即可。”
全場再次嘩然,眾位大臣齊刷刷地看著國王,似乎等待著最終的宣判。
絕地反擊
B+樹大臣頓時印堂發黑,心想幾十年的風光就要今日終結嗎,本來隨著SSD等新型硬件的誕生我的日子就不好過了, 難道今日命喪機器學習之手?悲傷難以平復,搖搖欲墜。
這個時候,CBO(基于代價的優化器)從后面走過來,一把扶住B+樹,看著這個日益蒼老的老頭,說道:“大人莫慌,別看他和囂張,但是有巨大漏洞,看我來對付他。”
CBO大臣說道:“你之前說的只是查找和存儲性能,索引的維護(增/刪/改)代價難道不用考慮嗎,如果索引發生了變化,之前的page= f(key)這個函數還有效嗎? 是不是還得重新訓練神經網絡,找到新的函數 page = f1(key)? 這還是O(1)的時間復雜度嗎?我們數據庫面對的是通用場景,不要以為只考慮幾個case就覺得可以替代我們了!”
機器學習大使大驚,功敗垂成!自己已經隱藏的這么深,還是被發現了缺陷,頓時紅了個臉:“您說的對,我們在索引的更新上還沒有很好的解決方案,但我們只是想為數據庫索引帶來一些新鮮想法,做現在的技術選項的補充,并沒有想著取代誰。”
B+樹一聽,立刻滿血復活:“陛下,您看看,這是一個不成熟的方案,對于數據查找能做到O(1), 但是對于數據更新就完全不行了,居然還想替代我!我就說這機器學習是招搖撞騙嘛!”
數據庫國王搖搖頭:“愛卿所言差矣,這個機器學習的思路還是非常新奇的,我們還是要學習一下的, 來人,給機器學習大使送上白銀千兩,好好安頓。”
后記
這篇文章的靈感來源于一篇論文《The Case for Learned Index Structures》,實際上真正要把機器學習應用的索引上,就算考慮只讀場景,往往也會因為數量太大,關系太多復雜,導致計算量、模型復雜度方面的問題,所以提出這個論文的作者提到通過建立層次模型的方式解決:根節點的分類器將記錄劃分成n份,給下一層分類器進行分類,這樣節點的預測器學習的數據少而簡單,總體的時間成本也能夠保證。

【本文為51CTO專欄作者“劉欣”的原創稿件,轉載請通過作者微信公眾號coderising獲取授權】