詳解全鏈路監控架構:目標、功能模塊、Dapper和方案比較
概述
隨著微服務架構的流行,服務按照不同的維度進行拆分,一次請求往往需要涉及到多個服務。互聯網應用構建在不同的軟件模塊集上,這些軟件模塊,有可能是由不同的團隊開發、可能使用不同的編程語言來實現、有可能布在了幾千臺服務器,橫跨多個不同的數據中心。因此,就需要一些可以幫助理解系統行為、用于分析性能問題的工具,以便發生故障的時候,能夠快速定位和解決問題。
全鏈路監控組件就在這樣的問題背景下產生了。最出名的是谷歌公開的論文提到的 Google Dapper。想要在這個上下文中理解分布式系統的行為,就需要監控那些橫跨了不同的應用、不同的服務器之間的關聯動作。
分布式服務調用鏈路
在復雜的微服務架構系統中,幾乎每一個前端請求都會形成一個復雜的分布式服務調用鏈路。一個請求完整調用鏈可能如下圖所示:
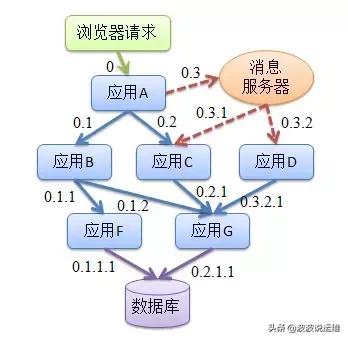
一個請求完整調用鏈
那么在業務規模不斷增大、服務不斷增多以及頻繁變更的情況下,面對復雜的調用鏈路就帶來一系列問題:
- 如何快速發現問題?
- 如何判斷故障影響范圍?
- 如何梳理服務依賴以及依賴的合理性?
- 如何分析鏈路性能問題以及實時容量規劃?
同時需要關注在請求處理期間各個調用的各項性能指標,比如:吞吐量(TPS)、響應時間及錯誤記錄等。
- 吞吐量,根據拓撲可計算相應組件、平臺、物理設備的實時吞吐量。
- 響應時間,包括整體調用的響應時間和各個服務的響應時間等。
- 錯誤記錄,根據服務返回統計單位時間異常次數。
全鏈路性能監控 從整體維度到局部維度展示各項指標,將跨應用的所有調用鏈性能信息集中展現,可方便度量整體和局部性能,并且方便找到故障產生的源頭,生產上可極大縮短故障排除時間。
有了全鏈路監控工具,能夠達到:
- 請求鏈路追蹤,故障快速定位:可以通過調用鏈結合業務日志快速定位錯誤信息。
- 可視化: 各個階段耗時,進行性能分析。
- 依賴優化:各個調用環節的可用性、梳理服務依賴關系以及優化。
- 數據分析,優化鏈路:可以得到用戶的行為路徑,匯總分析應用在很多業務場景。
1、全鏈路監控目標
如上所述,那么我們選擇全鏈路監控組件有哪些目標要求呢?Google Dapper中也提到了,總結如下:
1.探針的性能消耗
2.APM組件服務的影響應該做到足夠小。
服務調用埋點本身會帶來性能損耗,這就需要調用跟蹤的低損耗,實際中還會通過配置采樣率的方式,選擇一部分請求去分析請求路徑。在一些高度優化過的服務,即使一點點損耗也會很容易察覺到,而且有可能迫使在線服務的部署團隊不得不將跟蹤系統關停。
3.代碼的侵入性
4.即也作為業務組件,應當盡可能少入侵或者無入侵其他業務系統,對于使用方透明,減少開發人員的負擔。
5.對于應用的程序員來說,是不需要知道有跟蹤系統這回事的。
如果一個跟蹤系統想生效,就必須需要依賴應用的開發者主動配合,那么這個跟蹤系統也太脆弱了,往往由于跟蹤系統在應用中植入代碼的bug或疏忽導致應用出問題,這樣才是無法滿足對跟蹤系統“無所不在的部署”這個需求。
6.可擴展性
7.一個優秀的調用跟蹤系統必須支持分布式部署,具備良好的可擴展性。能夠支持的組件越多當然越好。
或者提供便捷的插件開發API,對于一些沒有監控到的組件,應用開發者也可以自行擴展。
8.數據的分析
9.數據的分析要快 ,分析的維度盡可能多。
跟蹤系統能提供足夠快的信息反饋,就可以對生產環境下的異常狀況做出快速反應。分析的全面,能夠避免二次開發。
2、全鏈路監控功能模塊
一般的全鏈路監控系統,大致可分為四大功能模塊:
1.埋點與生成日志
埋點即系統在當前節點的上下文信息,可以分為 客戶端埋點、服務端埋點,以及客戶端和服務端雙向型埋點。埋點日志通常要包含以下內容traceId、spanId、調用的開始時間,協議類型、調用方ip和端口,請求的服務名、調用耗時,調用結果,異常信息等,同時預留可擴展字段,為下一步擴展做準備;
2.收集和存儲日志
主要支持分布式日志采集的方案,同時增加MQ作為緩沖;
每個機器上有一個 deamon 做日志收集,業務進程把自己的Trace發到daemon,daemon把收集Trace往上一級發送;
多級的collector,類似pub/sub架構,可以負載均衡;
對聚合的數據進行 實時分析和離線存儲;
離線分析 需要將同一條調用鏈的日志匯總在一起;
3.分析和統計調用鏈路數據,以及時效性
調用鏈跟蹤分析:把同一TraceID的Span收集起來,按時間排序就是timeline。把ParentID串起來就是調用棧。
拋異常或者超時,在日志里打印TraceID。利用TraceID查詢調用鏈情況,定位問題。
依賴度量:
- 強依賴:調用失敗會直接中斷主流程
- 高度依賴:一次鏈路中調用某個依賴的幾率高
- 頻繁依賴:一次鏈路調用同一個依賴的次數多
離線分析:按TraceID匯總,通過Span的ID和ParentID還原調用關系,分析鏈路形態。
實時分析:對單條日志直接分析,不做匯總,重組。得到當前QPS,延遲。
4.展現以及決策支持
3、Google Dapper
3.1 Span
基本工作單元,一次鏈路調用(可以是RPC,DB等沒有特定的限制)創建一個span,通過一個64位ID標識它,uuid較為方便,span中還有其他的數據,例如描述信息,時間戳,key-value對的(Annotation)tag信息,parent_id等,其中parent-id可以表示span調用鏈路來源。
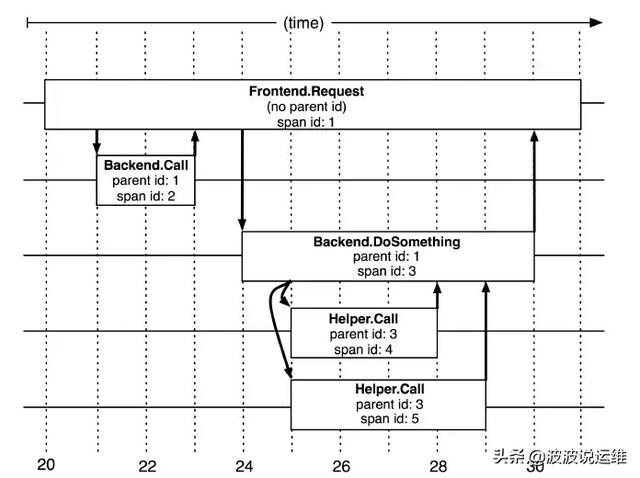
Span
上圖說明了span在一次大的跟蹤過程中是什么樣的。Dapper記錄了span名稱,以及每個span的ID和父ID,以重建在一次追蹤過程中不同span之間的關系。如果一個span沒有父ID被稱為root span。所有span都掛在一個特定的跟蹤上,也共用一個跟蹤id。
3.2 TRACE
類似于樹結構的Span集合,表示一次完整的跟蹤,從請求到服務器開始,服務器返回response結束,跟蹤每次rpc調用的耗時,存在唯一標識trace_id。比如:你運行的分布式大數據存儲一次Trace就由你的一次請求組成。
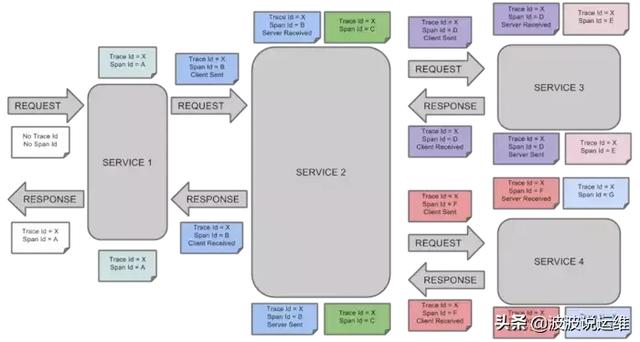
Trace
每種顏色的note標注了一個span,一條鏈路通過TraceId唯一標識,Span標識發起的請求信息。樹節點是整個架構的基本單元,而每一個節點又是對span的引用。節點之間的連線表示的span和它的父span直接的關系。雖然span在日志文件中只是簡單的代表span的開始和結束時間,他們在整個樹形結構中卻是相對獨立的。
3.3 Annotation
注解,用來記錄請求特定事件相關信息(例如時間),一個span中會有多個annotation注解描述。通常包含四個注解信息:
(1) cs:Client Start,表示客戶端發起請求
(2) sr:Server Receive,表示服務端收到請求
(3) ss:Server Send,表示服務端完成處理,并將結果發送給客戶端
(4) cr:Client Received,表示客戶端獲取到服務端返回信息
4、 方案比較
市面上的全鏈路監控理論模型大多都是借鑒Google Dapper論文,主要是以下三種APM組件:
Zipkin:由Twitter公司開源,開放源代碼分布式的跟蹤系統,用于收集服務的定時數據,以解決微服務架構中的延遲問題,包括:數據的收集、存儲、查找和展現。
Pinpoint:一款對Java編寫的大規模分布式系統的APM工具,由韓國人開源的分布式跟蹤組件。
Skywalking:國產的優秀APM組件,是一個對JAVA分布式應用程序集群的業務運行情況進行追蹤、告警和分析的系統。
相比之下,Pinpoint 具有壓倒性的優勢:無需對項目代碼進行任何改動就可以部署探針、追蹤數據細粒化到方法調用級別、功能強大的用戶界面以及幾乎比較全面的 Java 框架支持。