生產環境突發高負載!是“誰”偷走了你的服務器性能?
場景描述
網站上線后一直穩定運行,事情發生在今天早上,剛到公司,還沒走到工位,手機收到告警信息,生產環境中的某臺服務器突發高負載!立馬開啟電腦,放下手中早餐,開始排查處理。下面是診斷引起系統CPU性能問題的過程,希望能給到大家一些診斷問題時的一些思路。
業務環境:PHP
排查過程
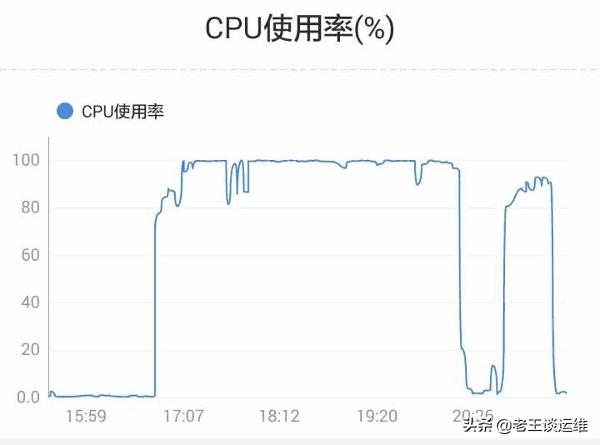
1、使用top命令查看當前系統情況,并按[1]展開CPU列表
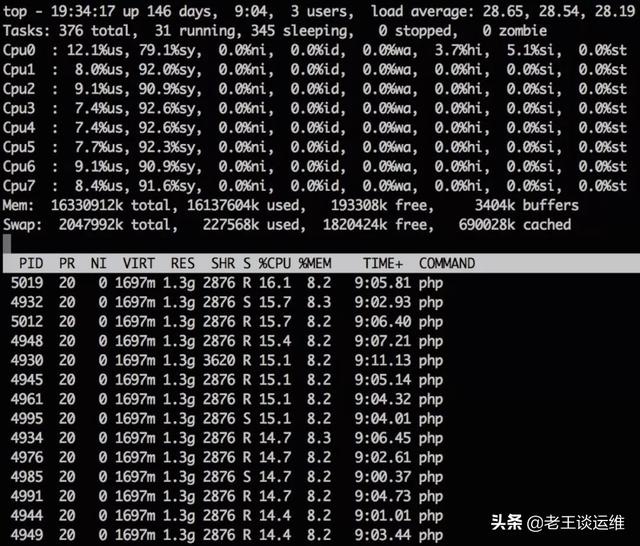
2、上圖可以看出來CPU占用主要是php進程導致,當前可用內存足夠。現在重點看下CPU的情況。
此例子中CPU 主要消耗在內核態「sy」,而非用戶態「us」。 需要跟蹤程序行為一般會用到兩個工具:
- 內核態的函數調用跟蹤用「strace」
- 用戶態的函數調用跟蹤用「ltrace」
下面使用strace來分析這次的問題:
- [root@localhost ~]# strace -cp <PID>
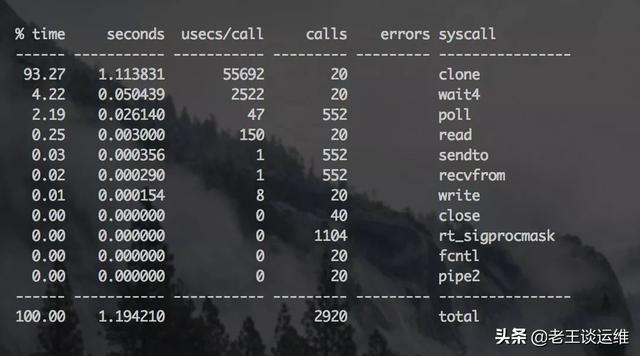
從上圖可以看到CPU總耗時最長的操作是一個名為clone的調用函數,單獨追蹤下這個命令:
- [root@localhost ~]# strace -T -e clone -p <PID>
- # -T: 獲取操作實際消耗的時間
- # -e: 指定需要追蹤的操作
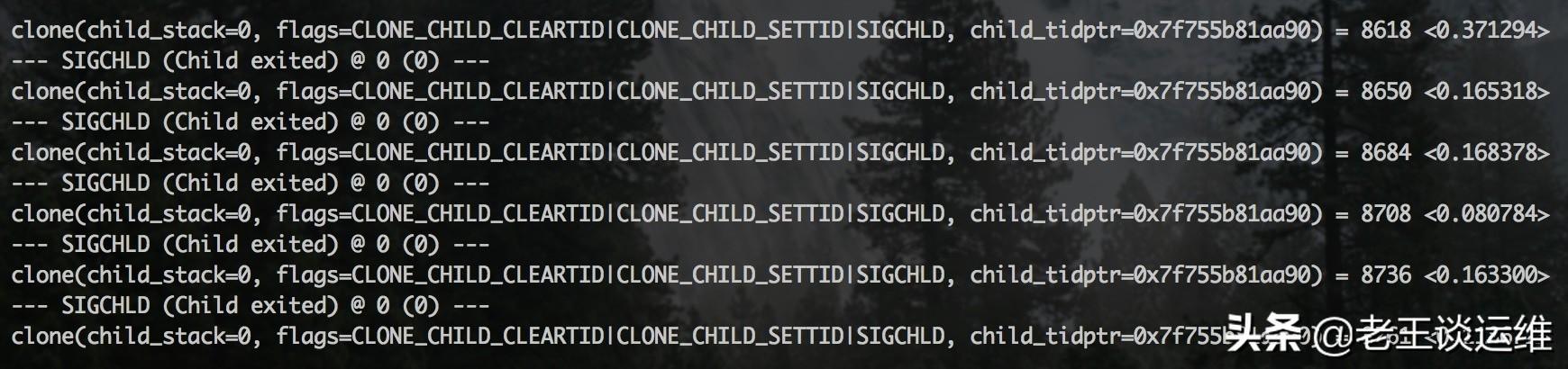
可以看到,一個 clone 操作需要幾百毫秒,clone操作的作用簡單來說就是調用系統函數去創建(fork)一個新進程。現在回歸到PHP側分析為什么會出現此類系統調用。
查詢業務代碼看到了 exec 函數,這個命令導致了系統不斷會fork進程,去處理exec執行的外部命令,導致CPU開銷很大。
通過如下命令驗證它確實會導致 clone 系統調用:
- [root@localhost ~]# strace -e clone php -r 'exec("ls");'
有同學要疑問了,同是Linux運維工程師,自己從來都是登陸服務器觀察資源使用情況才獲取到高負載告警,之前還有因未及時發現服務器高負載情況,使得業務短時間崩潰,損失慘重。
你是如何在還沒到工位時就收到服務器高負載的告警信息的呢?
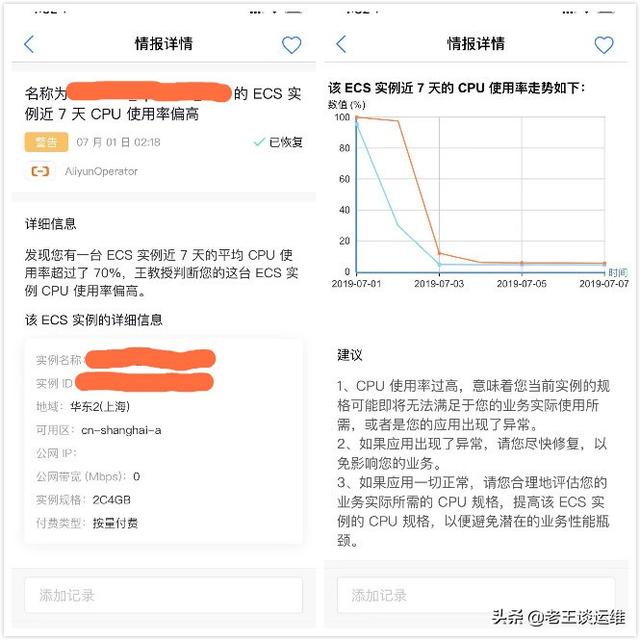
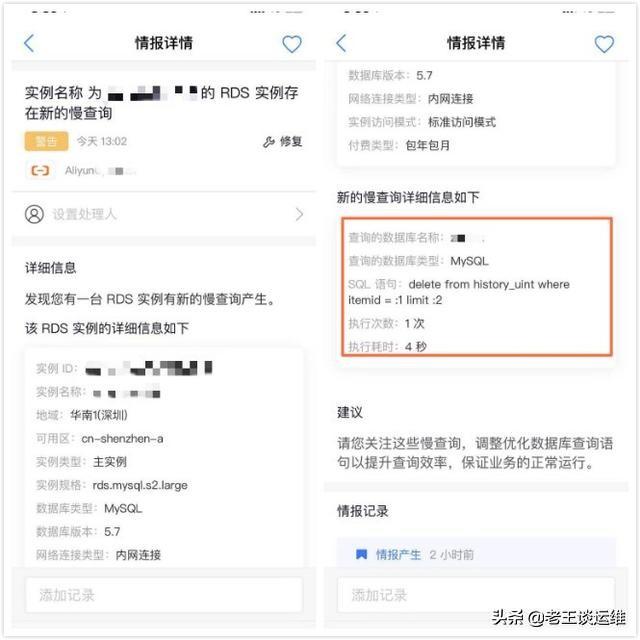
我是使用了一個云運維工具——王教授,對于日常運維工作幫助確實非常大,可以及時提醒我云資源的變化情況,例如:服務器 CPU 使用率偏高、服務器安全組設置不安全、云數據庫存在慢SQL等。使用云,運維云的同學可以選擇使用。
王教授工具地址:https://prof.wang。