一文讀懂如何在Kubernetes上輕松實現自動化部署Prometheus

簡介
Prometheus 是當下火熱的監控解決方案,尤其是容器微服務架構,Kubernetes 的首選監控方案。關于為什么要用 Prometheus,我這里就不多講,相關的文章太多了,大家也可以看看官方的說法。本文就講講如何自動化的搭建一套基于 Kubernetes 集群的 Prometheus 監控系統。
我這里使用 Prometheus Operator 以及 helm 工具在 Kubernetes 集群上部署,后面給大家提供一個全自動運維 (http://t.cn/Ai8t4jLw) 的例子參考,這里直接看代碼。
關于 helm 的使用不清楚的可以參考這幾篇文章:
- Helm 入門指南
- 利用 Helm 快速部署 Ingress
- Kubernetes 實操手冊-Helm使用 (http://t.cn/Ai85DU9N)
關于什么是 Prometheus Operator 以及為什么要用 Prometheus Operator?
Operator 是以軟件的方式定義運維過程,是一系列打包、部署和管理 Kubernetes 應用的方法。簡單來說就是將運維過程中的手動操作轉換為自動化流程,通過 Kubernetes 的 CRD(Custom Resource Definition)將部署前后的相關操作自動化,同時以參數的方式提供了靈活性。而 Prometheus Operator 是 CoreOS 提供的一整套 Prometheus 的 Operator,方便了 Prometheus 的部署。
下面我們先簡單講講 Prometheus 的架構。
Prometheus 核心
下圖是 Promtheus 官方的架構圖
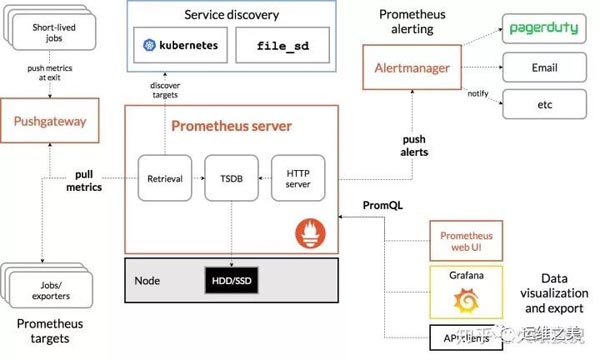
Prometheus Server
Prometheus Server 是監控系統的服務端,服務端通過服務發現的方式,抓取被監控服務的指標,或者通過 pushgateway 的間接抓取,抓取到指標數據后,通過特定的存儲引擎進行存儲,同時暴露一個 HTTP 服務,提供用 PromQL 來進行數據查詢。注意,Prometheus 是定時采樣數據,而不是全量數據。
Exporter
Prometheus 需要服務暴露 http 接口,如果服務本身沒有,我們不需要改造服務,可以通過 exporter 來間接獲取。Exporter 就充當了 Prometheus 采集的目標,而由各個 exporter 去直接獲取指標。目前大多數的服務都有現成的 exporter,我們不需要重復造輪子,拿來用即可,如 MySQL,MongoDB 等,可以參考這里。
Push Gateway
Prometheus 采集指標的方式主要有兩種,一種是服務端暴露接口(Exporter),由 Prometheus 主動去抓取指標,稱為 pull 模式。另一種是服務端主動上報,服務端將指標主動上報至 Push Gateway,Prometheus 再從 Push Gateway 中獲取,稱為 push 模式。而 Push Gateway 就是 push 模式中重要的中介角色,用于暫存服務端上報的指標,等待 Prometheus 收集。
為什么要有兩種模式呢?我們來比較一下這兩種模式的特點。
Pull 模式:Prometheus 主動抓取的方式,可以由 Prometheus 服務端控制抓取的頻率,簡單清晰,控制權在 Prometheus 服務端。通過服務發現機制,可以自動接入新服務,去掉下線的服務,無需任何人工干預。對于各種常見的服務,官方或社區有大量 Exporter 來提供指標采集接口,基本無需開發。是官方推薦的方式。
Push 模式:由服務端主動上報至 Push Gateway,采集最小粒度由服務端決定,等于 Push Gateway 充當了中介的角色,收集各個服務主動上報的指標,然后再由 Prometheus 來采集。但是這樣就存在了 Push Gateway 這個性能單點,而且 Push Gateway 也要處理持久化問題,不然宕機也會丟失部分數據。同時需要服務端提供主動上報的功能,可能涉及一些開發改動。不是首選的方式,但是在一些場景下很適用。例如,一些臨時性的任務,存在時間可能非常短,如果采用 Pull 模式,可能抓取不到數據。
Alert Manager
Alert Manager 是 Prometheus 的報警組件,當 Prometheus 服務端發現報警時,推送 alert 到 Alert Manager,再由 Alert Manager 發送到通知端,如 Email,Slack,微信,釘釘等。Alert Manager 根據相關規則提供了報警的分組、聚合、抑制、沉默等功能。
Web UI/Grafana
Prometheus 提供了一個簡單的 web UI 界面,用于查詢數據,查看告警、配置等,官方推薦使用另一個開源項目 grafana 來做指標的可視化展示,制作儀表盤等。
部署
下面詳細講講如何自動化部署 Promethues,自動化監控以及遇到的一些坑。
部署這塊 Prometheus Operator 已經幫我們做的非常好了,我們只需要調整一些參數即可實現部署。我們使用 helm 來部署 Prometheus,只需要一個命令。
- helm install --name my-release stable/prometheus-operator
不過這不可能滿足我們的需求,我們需要的不是演示,而是實戰。
下面是詳細講解,完整的項目可以參考這里:http://t.cn/Ai8tzUaR 。
我們首先要確定的是如何持久化存儲 Prometheus 的指標數據,默認的方式是以文件的方式保存在服務端的磁盤上,但這樣不利于服務端的橫向擴展以及數據的備份恢復。Prometheus 還提供了其他存儲后端的整合,詳見這里。目前比較流行的做法是使用 InfluxDB 作為存儲后端,InfluxDB 是一款強大的時序數據庫,就是為監控指標等時序數據而生的。
首先,我們來部署 InfluxDB,為了持久化 InfluxDB 的數據,我們先創建一個 PVC 來持久化數據。
pvc.yaml
- apiVersion: v1
- kind: PersistentVolumeClaim
- metadata:
- name: influxdb-pvc
- namespace: monitoring
- labels:
- app: influxdb
- release: influxdb
- spec:
- accessModes:
- - ReadWriteOnce
- storageClassName: monitor-ebs # 選擇合適的存儲類
- resources:
- requests:
- storage: 200Gi # 設置合適的存儲空間
然后我們創建 InfluxDB 的配置文件
influxdb.yaml
- # 持久化存儲配置
- persistence:
- enabled: true
- useExisting: true
- name: "influxdb-pvc" # 使用我們剛才創建的 PVC
- accessMode: "ReadWriteOnce"
- size: 200Gi
- # 創建 Prometheus 的數據庫
- env:
- - name: INFLUXDB_DB
- value: "prometheus"
- # influxdb 配置
- config:
- data:
- # 這兩個配置默認限制了數據的上限,建議設置為 0 變成無限制,不然在達到上限后插入數據會返回錯誤
- max_series_per_database: 0
- max_values_per_tag: 0
- http:
- enabled: true # 啟動 http
- initScripts:
- enabled: true
- scripts:
- # 設置數據保留策略,默認是永不失效,需要人工清理
- # 保留 180 天數據
- retention.iql: |+
- CREATE RETENTION POLICY "default_retention_policy" on "prometheus" DURATION 180d REPLICATION 1 DEFAULT
InfluxDB 的全部配置可以參考文檔,我講一下上面的兩個主要的配置。
max-series-per-database
內存中每個數據庫最大的序列數量,默認是 1000000,設置為 0 改成無限制。如果新來的數據增加了序列數量并超過了這個上限,那么數據就會被丟棄就并返回一個 500 錯誤:
- {"error":"max series per database exceeded: <series>"}
max-values-per-tag
內存中每個標簽的最大數據量,默認是 100000,設置為 0 改成無限制。如果新來的數據超過了這個限制,也會被丟棄并返回寫入失敗的錯誤。
我們使用如下命令來部署 InfluxDB:
- helm install --name=influxdb --namespace=monitoring -f influxdb.yaml stable/influxdb
存儲后端部署成功后,我們就來部署 Prometheus-operator 了,首先創建如下的配置文件:
prometheus.yaml
- # prometheus 服務端
- prometheus:
- prometheusSpec:
- # 遠端存儲配置
- remoteWrite:
- - url: "http://influxdb:8086/api/v1/prom/write?db=prometheus"
- remoteRead:
- - url: "http://influxdb:8086/api/v1/prom/read?db=prometheus"
- # ingress 配置,暴露 web 界面
- ingress:
- enabled: true
- annotations:
- kubernetes.io/ingress.class: traefik # ingress class
- hosts:
- - "prometheus.mydomain.io" # 配置域名
- alertmanager:
- # alertmanager 配置
- config:
- global:
- # SMTP 配置
- smtp_smarthost: 'xxx'
- smtp_from: 'xxx'
- smtp_auth_username: 'xxx'
- smtp_auth_password: 'xxx'
- # 全局 opsgenie 配置
- # opsgenie_api_key: ""
- # 報警路由
- route:
- receiver: 'monitoring-warning'
- group_by: ['alertname']
- group_wait: 30s
- group_interval: 3m
- repeat_interval: 8h
- routes:
- - match:
- severity: critical
- receiver: monitoring-critical
- group_by: ['alertname']
- - match:
- severity: warning
- receiver: monitoring-warning
- group_by: ['alertname']
- # 報警抑制規則
- inhibit_rules:
- - source_match:
- severity: 'critical'
- target_match:
- severity: 'warning'
- # 抑制相同的報警
- equal: ['alertname']
- # 接收者配置
- receivers:
- - name: 'monitoring-critical'
- email_configs:
- - to: 'monitor@mydomain.com'
- # 發送到釘釘的 webhook,需要部署一個轉發服務,詳見項目代碼
- webhook_configs:
- - send_resolved: true
- url: http://prometheus-webhook-dingtalk/dingtalk/monitoring/send
- - name: 'monitoring-warning'
- email_configs:
- - to: 'monitor@mydomain.com'
- alertmanagerSpec:
- # alertmanager 存儲配置,alertmanager 會以文件形式存儲報警靜默等配置
- storage:
- volumeClaimTemplate:
- spec:
- accessModes:
- - ReadWriteOnce
- storageClassName: monitor-ebs # 選擇合適的存儲類
- resources:
- requests:
- storage: 20Gi # 選擇合適的大小
- # ingress 配置,暴露 alert 的界面
- ingress:
- enabled: true
- annotations:
- kubernetes.io/ingress.class: traefik # ingress class
- hosts:
- - "alert.mydomain.io" # 配置域名
- # grafana 配置
- grafana:
- replicas: 1
- adminPassword: "admin" # 管理員賬戶 admin,密碼 admin
- env:
- # GF_SERVER_DOMAIN: "" # 域名
- GF_SERVER_ROOT_URL: "%(protocol)s://%(domain)s/"
- # GF_DATABASE_URL: "mysql://user:secret@host:port/database" # SQL 數據庫
- # ingress 配置,暴露界面
- ingress:
- enabled: true
- annotations:
- kubernetes.io/ingress.class: traefik # ingress class
- hosts:
- - "grafana.mydomain.io" # 設置域名
- # exporter 設置,自建集群需要開啟,如果是云服務商托管集群,則獲取不到這些信息,可以關閉
- kubeControllerManager:
- enabled: true
- kubeEtcd:
- enabled: true
- kubeScheduler:
- enabled: true
然后我們使用如下命令來部署 Prometheus-Operator。
- helm install --name=prometheus --namespace=monitoring -f prometheus.yam stable/prometheus-operator
如果需要 Prometheus-Pushgateway 的話,創建如下配置:
prometheus-pushgateway.yaml
- replicaCount: 1
- # 自動在 Prometheus 中添加 target
- serviceMonitor:
- enabled: true
- namespace: monitoring
- selector:
- app: prometheus-pushgateway
- release: prometheus
- # ingress 配置,暴露界面
- ingress:
- enabled: true
- annotations:
- kubernetes.io/ingress.class: traefik # ingress class
- hosts:
- - "pushgateway.mydomain.io" # 設置域名
同樣的方式部署:
- helm install --name=prometheus-pushgateway --namespace=monitoring -f prometheus-pushgateway.yaml stable/prometheus-pushgateway
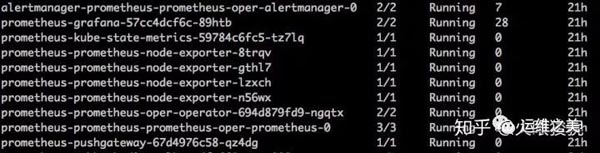
這樣 Prometheus 的核心組件都部署完成了,查看集群中的 Pod,有類似如下圖所示的 Pod。
這里有個注意點,如果通過 Prometheus 收集 kube-proxy 的指標,需要 kube-proxy 開通訪問,默認 kube-proxy 只允許本機訪問。
需要修改 kube-proxy 的 ConfigMap 中的 metricsBindAddress 值為 0.0.0.0:10249。
- kubectl -n kube-system edit cm kube-proxy
會看到如下內容,將 metricsBindAddress: 127.0.0.1:10249 這行修改為 metricsBindAddress: 0.0.0.0:10249 保存即可。
- apiVersion: v1
- data:
- config.conf: |-
- apiVersion: kubeproxy.config.k8s.io/v1alpha1
- kind: KubeProxyConfiguration
- # ...
- # metricsBindAddress: 127.0.0.1:10249
- metricsBindAddress: 0.0.0.0:10249
- # ...
- kubeconfig.conf: |-
- # ...
- kind: ConfigMap
- metadata:
- labels:
- app: kube-proxy
- name: kube-proxy
- namespace: kube-system
然后刪除 kube-proxy 的 Pod,讓它重啟即可看到已正常抓取。

應用
至此,Prometheus 的服務端就全部部署完成了。接下來就是根據實際業務部署相應的 Exporter,ServiceMonitor 和 PrometheusRule 了。官方和社區有大量現成的 Exporters 可供使用,如果有特殊需求的也可以參考這里自行開發。
接下來我們講講如何快速集成 Prometheus 監控和報警。
我們之前提到過 Operator 通過 CRD 的方式提供了很多部署方面的自動化,Prometheus-Operator 就提供了四個 CRD,分別是:
- Prometheus,定義了 Prometheus 服務端,用來生成服務端控制器,保證了服務端的正常運行,我們只需要一個此 CRD 的實例
- Alertmanager,定義了 AlertManager 服務,用來生成服務端控制器,保證了服務的正常運行,我們也只需要一個此 CRD 的實例
- ServiceMonitor,定義了 Prometheus 抓取指標的目標,就是 Prometheus 界面 targets 頁面看到的內容,此 CRD 幫助我們創建目標的配置
- PrometheusRule,定義了 Prometheus 規則,就是 Prometheus 界面 Rules 頁面看到的內容,此 CRD 幫助我們創建規則的配置
Prometheus 和 Alertmanager CRD 主要是之前部署階段關注的,在服務應用階段,我們主要是創建各個 ServiceMonitor 和 PrometheusRule 來配置服務端。
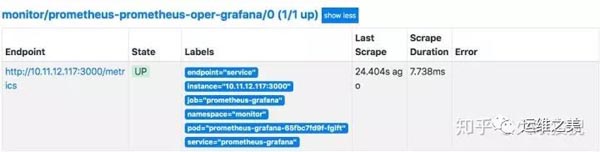
Prometheus-Operator 默認會幫我們注冊相關組件的抓取目標,如下圖所示:
我們要定義其他的抓取目標,首先來創建了一個 ServiceMonitor 抓取我們部署的 InfluxDB 的指標:
- apiVersion: monitoring.coreos.com/v1
- kind: ServiceMonitor
- metadata:
- name: influxdb-scrape-targets
- labels:
- app.kubernetes.io/name: scrape-targets
- app.kubernetes.io/instance: influxdb-target
- release: prometheus
- spec:
- # 用標簽選擇器來選擇相應的 Pod
- selector:
- matchLabels:
- app: influxdb
- release: influxdb
- # 選擇命名空間
- namespaceSelector:
- matchNames:
- - monitoring
- # 定義抓取的配置,如端口、頻率等
- endpoints:
- - interval: 15s
- port: api
我們在項目中創建了一個 Chart 模版(在 charts/scrape-targets/ 目錄),能夠快速的創建 ServiceMonitor,提供下面的配置文件:
influxdb.yaml
- selector:
- matchLabels:
- app: influxdb
- release: influxdb
- namespaceSelector:
- matchNames:
- - monitoring
- endpoints:
- - port: api
- interval: 15s
然后使用 helm 安裝:
- helm install --name influxdb-target --namespace monitoring -f influxdb.yaml charts/scrape-targets/
創建完成后無需重啟 Prometheus 服務端,服務端根據標簽自動載入,過一會可以在界面上看到:
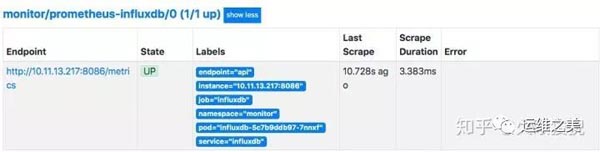
Prometheus-Operator 同樣會幫我們注冊許多相關的規則,如下圖所示:
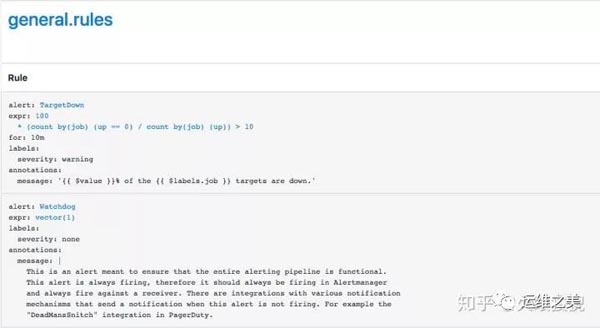
配置我們自己的 PrometheusRule 同樣很簡單,我們用如下配置生成報警規則,如果 5 分鐘內的 HTTP 500 錯誤大于 5 則報警。
- apiVersion: monitoring.coreos.com/v1
- kind: PrometheusRule
- metadata:
- name: request-rules
- labels:
- app.kubernetes.io/name: rules
- app.kubernetes.io/instance: request
- app: prometheus-operator
- release: prometheus
- spec:
- groups:
- - name: request-rules.rules
- rules:
- - alert: RequestStatusCode500
- annotations:
- summary: http status code 500 is high for `{{$labels.service}}`
- expr: http_request_total{statuscode="500"} > 5
- for: 5m
- labels:
- severity: critical
也可以用我們項目中的 Chart 模版(在 charts/rules/ 目錄)來快速配置。
request.yaml
- groups:
- - rules:
- - alert: RequestStatusCode500
- expr: http_request_total{statuscode="500"} > 5
- for: "5m"
- labels:
- severity: critical
- annotations:
- summary: http status code 500 is high for `{{$labels.service}}`
然后 helm 安裝
- helm install --name request --namespace monitoring -f request.yaml charts/rules/
關于怎么寫規則配置,可以參考官方的文檔和 PromQL 語法。
以上的操作還是手動化的,如果要全自動化的話,可以參考我的項目,定義好配置文件,寫好自動化腳本,接入 CI/CD 工作流,即可讓監控系統實現自動部署、自動配置。