微服務分布式一致性模式
微服務拆分后遇到的一個麻煩是分布后的一致性問題。單體架構的業(yè)務處理和數據都在一個進程里面,一致性保障很成熟,開發(fā)人員基本上不用關心。當把業(yè)務系統拆分到不同進程時,就遇到了技術性一致性問題。這帶來了糾結,我們希望有一顆銀彈,一把解決問題。但由于分布式一致性在(CAP)理論上沒有完美的解決方案,我們所能選擇的方案是在特定業(yè)務場景下的選擇。
我們這里討論的分布是指業(yè)務邏輯上做了拆分導致的分布,而不是數據量特別大導致的分布。
如果業(yè)務上不拆分,數據量特別大需要做分布,可以選擇支持大數據的分布式數據庫。可以選擇Cassandra, MongoDB等NoSQL,或者TiDB這類支持SQL的分布式方案。
如果業(yè)務上進行了拆分,不論選什么數據庫都不能解決分布式一致性問題。把數據庫或者分布式數據庫看成是一個系統,能處理一個外部請求在數據庫內部的分布式問題,但不能處理多個外部請求的一致性問題。
分布式強一致的數據庫不能解決業(yè)務邏輯拆分帶來的分布式一致性問題,我們還得繼續(xù)糾結如何解決業(yè)務分布式一致性的問題。
首先我把微服務分布式一致性問題分為數據共享一致性和業(yè)務交易一致性問題。
一、數據共享一致性
在單體架構的時候用同一個數據庫,不存在數據共享問題。微服務強調要獨立數據庫,引起數據如何共享的問題。
數據共享分為拉和推兩種模式,拉指消費者去供應商那邊拉數據,推指供應商主動把數據推到消費者面前。
1. 拉-視圖共享
對于一般的企業(yè)信息系統,數據量不大,并發(fā)需求也不大,我建議所有的微服務用同一個數據庫實例,但是拆分在不同的Schema。這樣的好處是在業(yè)務邏輯上數據庫是獨立的,也可以獨立演進。然后數據庫又可以集中管理。這個方案對于大型遺留系統拆分尤其適用,因為原本就是在一個庫里面,為了業(yè)務更好的獨立演進進行數據庫Schema拆分,又能延續(xù)原有的數據庫實例管理技術。由于不同的微服務實際運行在同一個數據庫實例上,可以簡單地建視圖進行數據共享。
需要注意的是,不要拉整個表出去,根據需要選擇幾個字段。這種模式技術上簡單,壞處有兩個:一是由于視圖同步的數據是實時的,應用可能基于實時同步數據的假設進行設計,會導致以后做分布式擴展的時候特別困難;二是視圖很容易暴露出表結構,這需要特別加強對視圖的設計和結構管理,讓暴露出去的視圖不要直接綁定在現有的表結構上。視圖所需的字段是外部需要,而不是表上面有什么。這樣視圖就是接口,只不過是強耦合在特定的數據庫實例上。
2. 拉-API獲取
微服務最推薦的方式是服務方提供數據API,消費者需要的時候去拉取。好處是消費者和供應方技術上完全解耦,壞處是提高了開發(fā)成本。如果消費者使用API方式獲取所需數據,建議使用異步Stream方式進行編程。 如果一次業(yè)務請求需要拉取多個數據源,不建議用同步的方式調用,因為會延長處理時間。建議使用reactiveX模式進行異步拉取和組裝 。
3. 推-事件消息
發(fā)生事件時發(fā)送消息是DDD CQRS模式,即解決了消費者要擁有數據用的爽快的問題(根據需要建立本地數據結構、獲取性能和方式), 也解決了數據庫技術異構的問題。帶來的問題是需要一個消息平臺,并且消費者或者供應方都要耦合在一個消息平臺技術上。對于大型遺留系統改造不是很友好,一方面遺留系統的消息平臺往往不符合高并發(fā)大數據量的性能要求,另一方面對于新的微服務也不想依賴老的消息平臺,而想要用Kafka這樣的互聯網高并發(fā)輕量的消息平臺。

4. 數據共享一致性選擇總結:
對于遺留系統改造和數據量不大(日交易量不超過百萬)的應用,建議使用不同微服務創(chuàng)建不同Schema,但用同一個數據庫實例,然后通過視圖的方式進行數據共享。
如果有些業(yè)務數據量非常大又需要共享,使用API共享,利用異步Stream編程進行數據共享。
如果微服務平臺技術設施成熟,可以使用推送事件消息模式, 既解決共享數據消費便利性問題,又解決數據結構解耦,并且使用輕量消息平臺(Kafka)只是有輕度的技術耦合。
二、業(yè)務交易分布式一致性
業(yè)務交易分布式一致性指一次請求,但分布在不同的微服務系統處理,引發(fā)一致性協調的問題。
交易分布式一致性分為補償模式,二次提交模式和Saga模式。
1. 補償模式
補償模式主要是通過重試達到最后的成功,僅適用于交易請求在業(yè)務上必須沒有失敗的場景。
補償模式用的最普遍的是消息投遞,假設給A發(fā)消息,如果沒有收到A確認消息已收到,就繼續(xù)發(fā)送,直到A確認收到消息為止。
有很多業(yè)務可以變成必須成功的交易。比如下訂單付款,如果先確認訂單再去扣款,就有可能因為賬戶沒錢扣款不成功,導致業(yè)務上的失敗。如果業(yè)務改成先扣款再去確認訂單,那可以認為訂單必須要確認成功。通過業(yè)務順序的調整來實現一個交易必須成功的情境。在技術實現上比較簡單,利用一個任務隊列跟蹤任務的完成狀態(tài),來決定重試。補償模式對API的要求是必須要冪等,因為有可能任務已經成功了,但消費者不知道,再次發(fā)出任務請求。
2. 二次提交模式
由于補償模式需要對業(yè)務進行調整,適用范圍也比較小,我們還是希望有個通用的分布式一致性方案。
最有名的應該是二次提交模式,更具體點是TCC(Try,Confirm,Cancel)。先發(fā)起try請求讓業(yè)務任務參與方做好處理準備,等所有的參與方都做好準備后,再發(fā)出confirm進行確認。因為所有的業(yè)務參與方都事前做好了準備,在confirm階段可以確保一次性成功。
如果有某個參與方識別,則發(fā)cancel進行回滾。這種模式和數據的事務管理基本一樣,像Java的JTA實現Automikos就是從支持數據庫事務,也支持REST API。二次提交雖然能解決事務一致性問題,但成本比較高。一個業(yè)務處理必須要拆分為準備和確認執(zhí)行兩個階段,對業(yè)務設計要求和開發(fā)成本都比較高。
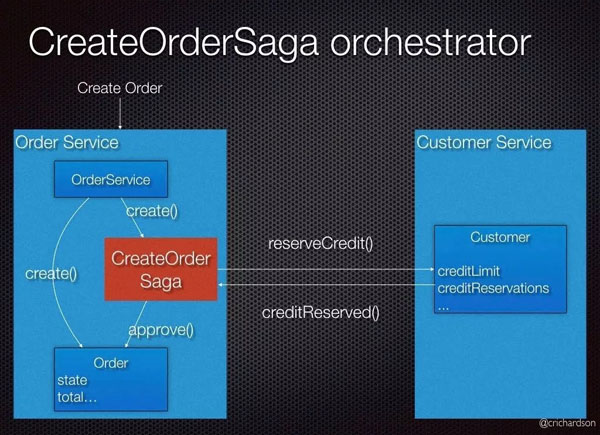
3. Sagas模式
Sagas模式在補償模式和二次提交模式,既簡單又能廣泛支持分布式事務場景。二次提交模式基于悲觀鎖,所以先要求任務參與方都做好準備,然后再做執(zhí)行。
Saga和補償模式是基于樂觀鎖,先讓任務參與方執(zhí)行,如果執(zhí)行沒響應則要求再次執(zhí)行。Saga給參與方發(fā)出任務后會記錄一個event(Saga的中文翻譯可以是事跡),所有event都會持久化。如果某個參與方執(zhí)行失敗,再發(fā)出cancel請求要求所有參與方回退。因為大部分交易請求是成功,這種基于樂觀鎖的協調機制能達成一致性目的,并降低了開發(fā)成本,業(yè)務設計上也比較容易理解。
目前支持Saga的Java框架有華為開源的servicecomb saga,京東已經有些線上系統用了。還有做CQRS的框架axoniq也實現了saga。
【本文為51CTO專欄作者“張逸”原創(chuàng)稿件,轉載請聯系原作者】