分布式系統(tǒng)中的一致性模型
最近看到的一篇超棒的關于分布式系統(tǒng)中強一致性模型的blog,實在沒有不分享的道理。最近比較閑,所以干脆把它翻譯了,一是為了精讀,二是為了更友好地分享。其中會插入一些亂七八糟的個人補充,評論區(qū)的精彩討論也會有選擇性的翻譯。原文在這: https://aphyr.com/posts/313-st ... odels
網絡分區(qū)是大概率會 發(fā)生 的。交換機,網絡接口控制器(NIC,Network Interface Controller),主機硬件,操作系統(tǒng),硬盤,虛擬機,語言運行時,更不用說程序語義本身,所有的這些將導致我們的消息可能會延遲,被丟棄,重復或被重新排序。在一個充滿不確定的世界里,我們希望程序保持一種 直觀的正確性 。
是的,我們想要直觀的正確性。那就做正確的事吧!但什么是正確的事?我們如何描述它?在這篇文章里,我們會見到一些“強”一致性模型,并且看到他們是如何互相適應的。
正確性(Correctness)
其實有很多種描述一個算法抽象行為的方式——但為了統(tǒng)一,我們說一個系統(tǒng)是由 狀態(tài) 和一些 導致狀態(tài)轉移的操作 組成的。在系統(tǒng)運行期間,它將隨著操作的演進從一個狀態(tài)轉移到另一個狀態(tài)。
uniprocessor history
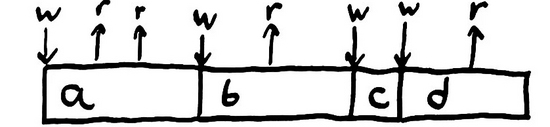
舉個例子,我們的狀態(tài)可以是個變量, 操作 可以是對這個變量的讀和寫。在這個簡單的Ruby程序里,我們會對一個變量進行幾次讀寫,以輸出的方式表示寫。
- x = "a"; puts x; puts x
- x = "b"; puts x
- x = "c"
- x = "d"; puts x
我們對程序的正確性已經有了一個直觀的概念:以上這段程序應該輸出 “aabd” 。為什么呢?因為它們是有序發(fā)生的。首先我們 寫入值a ,然后 讀到值a ,接著 讀到值a , 寫入值b ,如此進行。
一旦我們把變量寫為某個值,比如 a ,那么讀操作就應該返回 a ,直到我們再次改變變量。讀到的值應該總是返回最近寫入的值。我們把這種系統(tǒng)稱為——單值變量——單一 寄存器 (并不單指硬件層次的寄存器,而是 act like a register )。
從編程的第一天開始,我們就把這種模型奉為圭臬,像習慣一樣自然——但這并不是變量運作的唯一方式。一個變量可能被讀到任何值: a , d ,甚至是 the moon 。這樣的話,我們說系統(tǒng)是 不正確 的,因為這些操作沒有與我們模型期望的運作方式對應上。
這引出了對系統(tǒng) 正確性 的定義:給定一些涉及操作與狀態(tài)的 規(guī)則 ,隨著操作的演進,系統(tǒng)將一直 遵循這些規(guī)則 。我們把這樣的規(guī)則稱為 一致性模型 。
我們把對寄存器的規(guī)則用簡單的英語來陳述,但它們也可以是任意復雜的數學結構。“讀取兩次寫入之前的值,對值加三,如果結果為4,讀操作可能返回cat或dog”,這也可以是一種一致性模型(作者只是為了表名一致性模型的闡述原則,后同)。也可以是“每次讀操作都會返回0”。我們甚至可以說“根本沒有什么規(guī)則,所有操作都是允許的”。這就是 最簡單 的一致性模型,任何系統(tǒng)都能輕易滿足。
更加正式地說,一致性模型是 所有被允許的操作記錄 的集合。當我們運行一個程序,經過一系列集合中允許的操作,特定的執(zhí)行結果總是 一致 的。如果程序意外地執(zhí)行了 非 集合中的操作,我們就稱執(zhí)行記錄是 非一致 的。如果 任意 可能的執(zhí)行操作都在這個被允許的操作集合內,那么系統(tǒng)就 滿足 一致性模型。我們希望實際的系統(tǒng)是滿足這樣“直觀正確”的一致性模型的,這樣我們才能寫出可預測的程序。
并發(fā)記錄(Concurrent histories)
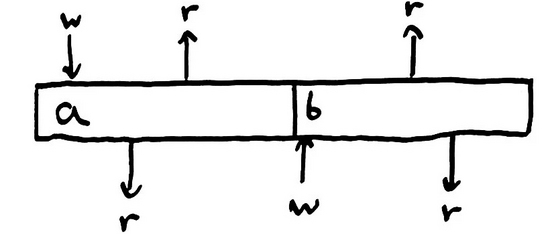
假設有一個用Node.js或Erlang寫的并發(fā)程序。現(xiàn)有多個邏輯線程,我們稱之為“多進程”。如果我們用2個進程運行這個并發(fā)程序,每個進程都對同一個寄存器進行訪問(讀和寫),那么我們之前認為的寄存器系統(tǒng)的不變性(指順序不變性)就會被 改寫 。
multiprocessor history
兩個工作進程分別稱為“top”和“bottom”。Top進程嘗試執(zhí)行 寫a , 讀 , 讀 。Bottom進程同時嘗試執(zhí)行 讀 , 寫b , 讀 。因為程序是并發(fā)的,所以兩個進程之間互相交錯的操作將導致 多個執(zhí)行順序 ——而在單核場景下,執(zhí)行順序總是程序里指定的那一個邏輯順序。圖例中,top寫入 a ,bottom讀 a ,top讀 a ,bottom寫 b ,top讀 b ,bottom讀 b 。
但是并發(fā)會讓一切表現(xiàn)的不同。我們可以 默認 地認為每個 并發(fā) 的程序——一旦執(zhí)行,操作能以任意順序發(fā)生。一個 線程 ,或者說是一個 邏輯進程 ,在執(zhí)行記錄層面的做了一個 約束 :屬于同一個線程的操作 一定 會按順序發(fā)生。邏輯線程對允許操作集合中的操作強加了部分順序保證。(一個邏輯線程即一個執(zhí)行實體,即使編譯器重排了指令,單個線程中的同步workflow順序是不會顛倒的。但是不同線程之間的事件順序無法保證。)
即使有了以上的保證,從獨立進程的角度來看,我們的寄存器不變性也被破壞了。Top寫入 a ,讀到 a ,接著讀到 b ——這 不再 是它寫入的值。 我們必須使一致性模型更 寬松 來有效描述并發(fā)。現(xiàn)在,進程可以從其他任意進程讀到最近寫入的值。寄存器變成了兩個進程之間的 協(xié)調地 :它們共享了狀態(tài)。
光錐(Light cones)
> 讀寫不再是一個瞬時的過程,而是一個類似光傳播->反射面->反向傳播的過程。
light cone history
現(xiàn)實往往沒有那么理想化:在幾乎每個實際的系統(tǒng)中,進程之間都有一定的 距離 。一個沒有被緩存的值(指沒有被CPU的local cache緩存),通常在距離CPU 30厘米 的DIMM內存條上。光需要整整一個納秒來傳播這么長的距離,實際的內存訪問會比光速慢得多。位于不同數據中心某臺計算機上的值可以相距幾千公里——意味著需要幾百毫秒的傳播時間。我們沒有更快傳播數據的方法,否則就違反了物理定律。(物理定律都違反了,就更別談什么現(xiàn)代計算機體系了。)
這意味著我們的操作 不再是瞬時的 。某些操作也許快到可以被近乎認為是瞬時的,但是通常來說,操作是 耗時 的。我們 調用 對一個變量的寫操作;寫操作傳播到內存,或其他計算機,或月球;內存改變狀態(tài);一個確認信息回傳;這樣我們才 知道 這個操作真實的發(fā)生了。
concurrent read
不同地點之間傳送消息的延遲會在操作記錄中造成 歧義 。消息傳播的快慢會導致預期外的事件順序發(fā)生。上圖中,bottom發(fā)起一個讀請求的時候,值為 a ,但在讀請求的傳播過程中,top將值寫為 b ——寫操作偶然地比讀請求 先 到達寄存器。 Bottom最終讀到了 b 而不是 a 。
這一記錄破壞了我們的寄存器并發(fā)一致性模型。Bottom并沒有讀到它在發(fā)起讀請求時的值。有人會考慮使用 完成時間 而不是 調用時間 作為操作的 真實時間 ,但反過來想想,這同樣行不通:當讀請求比寫操作先到達時,進程會在當前值為 b 時讀到 a 。
在分布式系統(tǒng)中,操作的耗時被放大了,我們必須使一致性模型 更寬松 :允許這些有歧義的順序發(fā)生。
我們該如何確定寬松的程度?我們必須允許 所有 可能的順序嗎?或許我們還是應該強加一些合理性約束?
線性一致性(Linearizability)
finite concurrency bounds
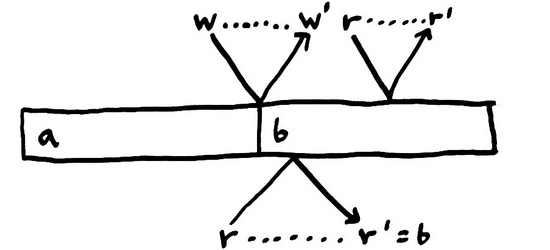
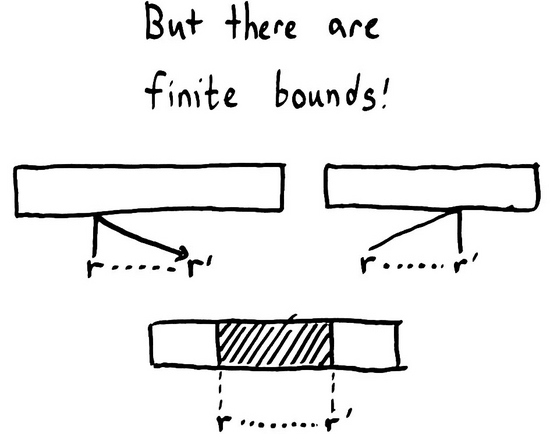
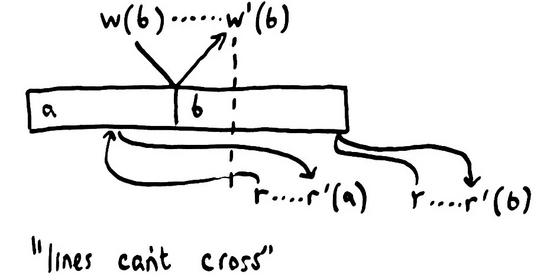
通過仔細的檢查,我們發(fā)現(xiàn)事件的順序是有邊界的。在時間維度上,消息不能被逆向發(fā)送,因此 最先到達 的消息會即刻接觸到數據源。一個操作不能在它 被調用之前 生效。
同樣的,通知完成的消息也不能回傳,這意味著一個操作 不能 在它 完成之后 生效。
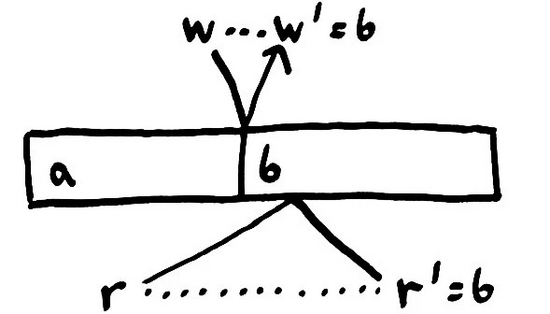
如果我們假設有一個全局的狀態(tài)與每個進程通信;繼續(xù)假設與這個全局狀態(tài)交互的操作都是 原子的 ;那我們可以排除很多可能發(fā)生的記錄。 每個操作會在它調用和完成之間的某個時間點原子地生效 。
我們把這樣的一致性模型稱為 線性一致性模型 。盡管操作都是并發(fā)且耗時的,但每一個操作都會在某地以嚴格的線性順序發(fā)生。
linearizability complete visibility
“全局單點狀態(tài)”并不一定是一個單獨的節(jié)點,同樣的,操作也并不一定全是原子的,狀態(tài)也可以被分片成橫跨多臺機器,或者分多步完成——只要從進程的角度看來,外部記錄的表現(xiàn)與 一個原子的單點狀態(tài)等效 。通常一個可線性化的系統(tǒng)由一些更小的協(xié)調進程組成,這些進程本身就是線性的,并且這些進程又是由更細粒度的協(xié)調進程組成,直到 硬件提供可線性化的操作 。
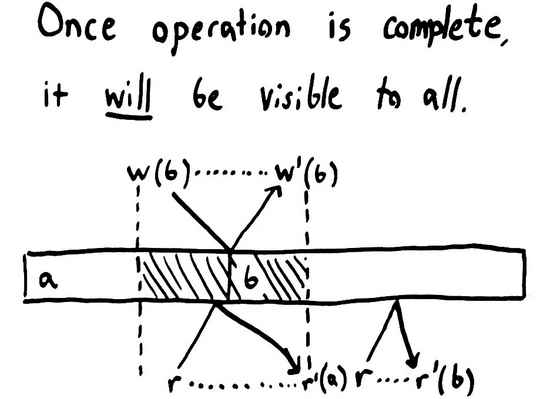
線性化是強大的武器。一旦一個操作完成,它或它之后的某一狀態(tài)將對 所有參與者 可見。因為每個操作 一定 發(fā)生在它的 完成時間 之前,且任何之后被調用的操作 一定 發(fā)生在 調用時間 之后,也就是在原操作本身之后。 一旦我們成功寫入 b ,每個之后調用的讀請求都可以讀到 b ,如果有更多的寫操作發(fā)生的話,也可以是 b 之后的某個值。
我們可以利用線性一致性的原子性約束來 安全地修改狀態(tài) 。我們定義一個類似 CAS(compare-and-set) 的操作,當且僅當寄存器持有某個值的時候,我們可以往它寫入新值。 CAS 操作可以作為互斥量,信號量,通道,計數器,列表,集合,映射,樹等等的實現(xiàn)基礎,使得這些共享數據結構變得可用。線性一致性保證了變更的 安全交錯 。
此外,線性一致性的時間界限保證了操作完成后,所有變更都對其他參與者可見。于是線性一致性禁止了過時的讀。每次讀都會讀到某一介于 調用時間 與 完成時間 的狀態(tài),但永遠不會讀到讀請求調用之前的狀態(tài)。線性一致性同樣禁止了 非單調 的讀,比如一個讀請求先讀到了一個新值,后讀到一個舊值。
由于這些強約束條件的存在,可線性化的系統(tǒng)變得更容易推理,這也是很多并發(fā)編程模型構建的時候選擇它作為基礎的原因。Javascript中的所有變量都是(獨立地)可線性化的,其他的還有Java中的volatile變量,Clojure中的atoms,Erlang中獨立的process。大多數編程語言都實現(xiàn)了互斥量和信號量,它們也是可線性化的。強約束的假設通常會產生強約束的保證。
但如果我們無法滿足這些假設會怎么辦?
(線性一致性模型提供了這樣的保證:1.對于觀察者來說,所有的讀和寫都在一個單調遞增的時間線上串行地向前推進。 2.所有的讀總能返回最近的寫操作的值。)
順序一致性(Sequential consistency)
sequencial history
如果我們允許進程在時間維度發(fā)生偏移,從而它們的操作可能會在調用之前或是完成之后生效,但仍然保證一個約束——任意進程中的操作必須按照進程中定義的順序(即編程的定義的邏輯順序)發(fā)生。這樣我們就得到了一個稍弱的一致性模型: 順序一致性 。
順序一致性允許比線性一致性產生更多的記錄,但它仍然是一個很有用的模型:我們每天都在使用它。舉個例子,當一個用戶上傳一段視頻到Youtube,Youtube把視頻放入一個處理隊列,并立刻返回一個此視頻的網頁。我們并不能立刻看到視頻,上傳的視頻會在被充分處理后的幾分鐘內生效。隊列會以入隊的順序 同步 地(取決于隊列的具體實現(xiàn))刪除隊列中的項。
很多緩存的行為和順序一致性系統(tǒng)一直。如果我在Twitter上寫了一條推文,或是在Facebook發(fā)布了一篇帖子,都會耗費一定的時間滲透進一層層的緩存系統(tǒng)。不同的用戶將在不同的時間看到我的信息,但每個用戶都以 同一個順序 看到我的操作。一旦看到,這篇帖子便不會消失。如果我寫了多條評論,其他人也會按順序的看見,而非亂序。
(順序一致性放松了對一致性的要求:1. 不要求操作按照真實的時間序發(fā)生。2. 不同進程間的操作執(zhí)行先后順序也沒有強制要求,但必須是原子的。3. 單個進程內的操作順序必須和編碼時的順序一直。)
因果一致性(Casual consistency)
我們不必對一個進程中的 每個 操作都施加順序約束。只有 因果相關 的操作必須按順序發(fā)生。同樣拿帖子舉例子:一篇帖子下的所有評論必須以同樣的順序展示給所有人,并且只有帖子可見 后 ,帖子下的回復才可見(也就是說帖子和帖子下的評論有因果關系)。如果我們將這些因果關系編碼成類似“我依賴于操作X”的形式,作為每個操作明確的一部分,數據庫就可以將這些操作延遲直到它們的依賴都就緒后才可見。
因果一致性比同一進程下對每個操作嚴格排序的一致性(即順序一致性)來的更寬松——屬于同一進程但不同因果關系鏈的操作能以相對的順序執(zhí)行(也就是說按因果關系隔離,無因果關系的操作可以并發(fā)執(zhí)行),這能防止許多不直觀的行為發(fā)生。
串行一致性(Serializable consistency)
serializable history
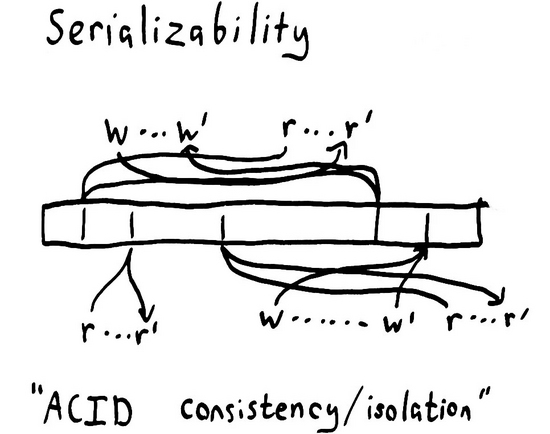
如果我們說操作記錄的發(fā)生等效于某些單一的原子序,但和調用時間與完成時間無關,那么我們就得到了名為 串行一致性 的一致性模型。這一模型比你想象的更強大同時也更脆弱。
串行一致性是 弱約束 的,因為它能允許多種類型的記錄發(fā)生,且對時間或順序不設邊界。在上面的示意圖中,消息看似可以被任意地發(fā)送至過去和未來,因果關系也可以交錯。在一個串行數據庫中,即使在0時刻, x 還沒被初始化,一個類似 read x 的讀事務也是允許執(zhí)行的。 或者它也會被延遲到無限遠的未來執(zhí)行。類似 write 2 to x 的寫事務可以立即執(zhí)行,也可能永遠都不會執(zhí)行。
舉個例子,在一個串行系統(tǒng)中,有這么一段程序:
- x = 1
- x = x + 1
- puts x
這段程序可以輸出 nil , 1 或 2 ,因為操作能以任意順序發(fā)生。 這是十分弱的約束!這里可以把每一行代碼看作是單個操作,所有操作都成功執(zhí)行了。
另一方面,串行一致性也是 強約束 的,當它要求一個線性順序時,它能攔截很大一部分操作記錄。看以下程序:
- print x if x = 3
- x = 1 if x = nil
- x = 2 if x = 1
- x = 3 if x = 2
這段程序只有一種輸出可能。它并不按我們 編寫 的順序輸出,但 x 會從 nil 開始變化: nil -> 1 -> 2 -> 3 ,最終輸出 3 。
因為串行一致性允許對操作順序執(zhí)行任意的重排(只要操作順序是原子序的), 它在實際的場景中并不是十分有用。大多數宣稱提供了串行一致性的數據庫實際上提供的是 強串行一致性 ,它有著和線性一致性一樣的時間邊界。讓事情更復雜的是,大多數SQL數據庫宣稱的串行一致性等級比 實際的更弱 ,比如可重復讀,游標穩(wěn)定性,或是快照隔離性。
(關于線性一致性和串行一致性,看似十分相似,其實不然。串行一致性是數據庫領域的概念,是針對事務而言的,描述對一組事務的執(zhí)行效果等同于某種串行的執(zhí)行,沒有ordering的概念,而線性一致性來自并行計算領域,描述了針對某種數據結構的操作所表現(xiàn)出的順序特征。 串行一致性是對多操作,多對象的保證,對總體的操作順序無要求;線性一致性是對單操作,單對象的保證,所有操作遵循真實時間序 。詳見: http://www.bailis.org/blog/lin ... lity/ )
一致性的代價(Consistency comes with costs)
之前說了“弱”一致性模型比“強”一致性模型 允許 更多的操作記錄發(fā)生(這里的強與弱是相對的)。比如線性一致性保證操作在調用時間與完成時間之間發(fā)生。不管怎樣, 需要協(xié)調來達成對順序的強制約束 。不嚴格地說,執(zhí)行越多的記錄,系統(tǒng)中的參與者就必須越謹慎且通信頻繁。
也許你聽說過 CAP理論 ,CAP理論聲明給定一致性( C onsistency),可用性( A vailability)和分區(qū)容錯性( P artition tolerance),任何系統(tǒng) 至多 能保證以上三項中的 兩項 而不可能滿足全部三項。這是Eric Brewer的CAP猜想的非正式說法,以下是準確的定義:
- 一致性(Consistency)意味著線性化,具體說,可以是一個可線性化的寄存器。寄存器可以等效為集合,列表,映射,關系型數據庫等等,因此該理論可以被拓展到各種可線性化的系統(tǒng)。
- 可用性(Availability)意味著向非故障節(jié)點發(fā)出的每個請求都將成功完成。因為網絡分區(qū)可以持續(xù) 任意長的時間 ,因此節(jié)點不能簡單地把響應推遲到分區(qū)結束。
- 分區(qū)容錯性(Partition tolerance)意味著分區(qū)很可能發(fā)生。當網絡 可靠 的時候,提供一致性和可用性將變得十分 簡單 ,但當網絡 不可靠 時,同時提供一致性和可用性將變得 幾乎不可能 。然而網絡總不是完美可靠的,所以我們不能選擇CA。所有實際可用的商用分布式系統(tǒng)至多能提供AP或CP的保證。
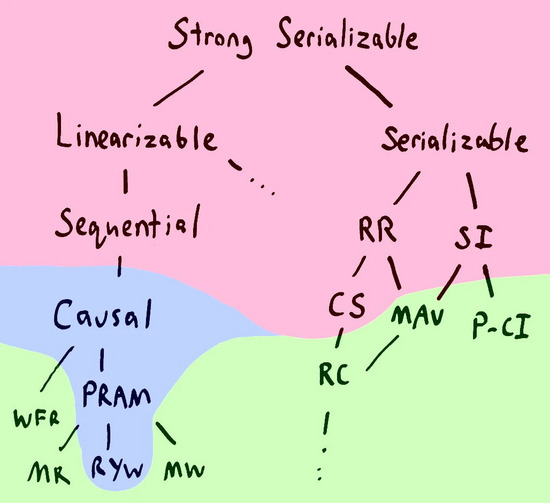
family tree
也許你會說:“等等!線性化并不是一致性模型的終極解決方案!我能圍繞著CAP理論提供順序一致性,串行一致性或是快照隔離性!”
沒錯,CAP理論只聲稱 我們不能構建一個完全可用的線性化系統(tǒng) 。但問題是我們又有了其他證據表明我們同樣不能利用順序化,串行化,可重復讀,快照隔離,游標穩(wěn)定或是其它任意一個比這些強的約束來構建完全可用的系統(tǒng)。在Peter Bailis的Highly Available Transactions這篇論文中,紅色陰影標注的模型就不能是 完全 可用的。
如果我們 放松 對可用性的定義,只要求client節(jié)點能夠一直與同一server保持通信,某種一致性就被達成了。我們能以此為基礎提供因果一致性,PRAM(pipelined random access memory)一致性和“讀你所寫”一致性。
如果我們要求 完全可用 ,那就能提供單調讀,單調寫,讀的提交,單調且原子的視角等等。這些一致性模型是由如Riak和Cassandra這樣的分布式存儲系統(tǒng),低隔離性設置的ANSI SQL數據庫提供的。這些一致性模型并沒有保證線性順序,而是在批處理任務或網絡場景下提供 部分 順序保證。只能保證部分順序是因為它們準許更豐富的記錄。
一種混合方法(A hybrid approach)
weak not unsafe
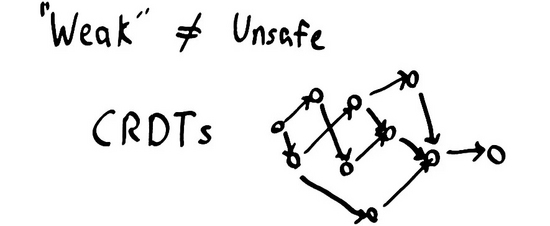
一些算法依賴于線性化提供安全性。例如當我們想構建分布式鎖的服務時,我們就需要線性化,如果沒有硬性的時間邊界的話,我們就可以持有一把將來的鎖或是過去的鎖。而另一方面,很多算法根本 不需要 線性化。即使僅提供“弱”一致性模型,比如有 最終一致性 保證的集合,列表,樹,映射等結構也能被安全地表示為 CRDTs (Commutative Replicated Data Types)
更強約束的一致性模型需要更多的協(xié)調——需要更多的消息交互,確保操作在正確的順序發(fā)生。這不僅意味著更低的可用性,還會被 導致更高的延遲 。這也是為什么現(xiàn)代CPU內存模型默認不是線性化的,除非顯示指定。(x86-64架構的CPU通常以Sequential consistency作為默認的memory order),現(xiàn)代CPU會在核之間重排內存操作,甚至更糟糕。雖然(程序的行為)更難以推理,但帶來的性能提升是驚人的。在地理位置上零落的分布式系統(tǒng),數據中心通常有幾百毫秒的延遲,通常和CPU的場景類似,代價也相似。
因此在實踐中,通常會用 混合 數據存儲,在數據庫之間混用不同的一致性模型來權衡冗余度,可用性,性能和安全性等目標。可能的話就為了可用性和性能選擇“弱”一致性模型。必要的話就選擇“強”一致性模型,因為某些算法對操作順序有嚴格要求。我們可以向S3,Riak,Cassandra等數據庫寫入大量數據,然后線性地向Postgres,ZooKeeper或etcd寫入指向數據的 指針 。一些數據庫準許多種一致性模型共存,比如關系數據庫中的可調節(jié)隔離等級,Cassandra和Riak中的線性化事務,減少了使用的系統(tǒng)數量。但底線是: 任何人宣稱它的一致性模型是最優(yōu)解,那么他一定是個大豬蹄子 。
接下來是精彩評論時間
Colin Scott:當你提到“屬于同一進程但不同因果關系鏈的操作”的時候,是否對潛在的因果關系(happens before)作了更保守的假設?我在苦想一個case,當來自同一臺機器上的兩個存在潛在因果關系(A必須先于B發(fā)生)的操作并發(fā)時,會發(fā)生什么?
Aphyr(作者):盡管來自同一個進程的操作在某一節(jié)點上按順序發(fā)生,但它們并不需要在 任何地方都 按序發(fā)生。順序一致性(Sequential consistency)作了這樣的約束,但因果一致性(Casual consistency)并沒有。只有 顯式 的因果關系在因果一致性系統(tǒng)中才是順序不變的,而 隱式 的因果關系在順序一致性系統(tǒng)中作了保證。(因為都來自同一進程,通過pid區(qū)分)
Aurojit Panda:實際上你對 Colin Scott 的回復和你在文章中的 一致性層級示意圖 是自相矛盾的。 PRAM一致性模型約定:所有節(jié)點都能按同一順序從一個給定節(jié)點觀測到它的寫操作(Lipton,Sandberg 1988)。而你描述的因果一致性是某一比PRAM一致性更弱的一致性模型,并不是經典的因果一致性模型。并且你描述中出現(xiàn)的隱式因果關系也是PRAM一致性模型約束中的一部分。如果因果一致性比PRAM一致性更強,PRAM一致性就應該用任何因果一致性系統(tǒng)來實現(xiàn),利用因果一致性對單節(jié)點的寫操作進行正確排序,使得其他節(jié)點的觀測結果一致。
Aphyr(作者):請參考: https://projects.ics.forth.gr/ ... s.pdf ,獲得為什么因果一致性比PRAM更強的詳細解釋。具體地說,有因果關系的操作可以在中間節(jié)點之間 傳遞 ,但是PRAM并沒有對因果一致性的傳遞性作任何定義。
Prakash:關于問題“在你串行一致性的示例中,各種 if 假設是如何對順序進行約束的?”你的回答中提到“這些操作發(fā)生的順序有且只有一種可能。”而我的問題是,當我們考慮在并發(fā)環(huán)境下執(zhí)行某種操作時,是怎么做到“串行有且只有一種可能”的?舉個例子,我們有不同的線程,其中一個檢查 x 值是否為3并把它打印,另一個將 x 的值設為2。你能解釋一下在這種場景中是如何維護順序的?
Aphyr(作者):串行的操作記錄實際上會轉化為單道線程下的操作記錄,單道線程下的操作記錄就是我們之前的討論中發(fā)揮作用的 狀態(tài)轉移方程 。如果以 恒等函數 作為你的模型,操作記錄中 任何 可能的路徑都是有效的,它們并不會改變狀態(tài)。為了讓某些操作記錄永遠不可串行化(限制那些非法的可能造成狀態(tài)轉移的操作發(fā)生),不得不聲明一些等效于單線程執(zhí)行的操作無效,這就是條件語句( if )強制部分操作有序的原因。