“ZAO”涼涼!教你用Deepfakes換臉
近日,一款名為"ZAO"的 AI 換臉軟件在社交媒體刷屏,火爆的同時也引發了不少質疑。詳情可查看《3天登頂蘋果免費榜,“ZAO”作起來會死》
只要在 App 中上傳一張照片,你想變成哪個明星,就能變成哪個明星。聽起來很夢幻,但卻觸手可及。

AI 換臉 App“ZAO”零門檻,操作簡單……具備走紅基因。然而,一夜“爆火”被追捧,一天就“爆雷”被封殺,短短不過 24 小時。



9 月 3 日,ZAO 正式發表道歉聲明。ZAO 表示,不會存儲個人面部生物識別特征信息,不會產生支付風險,公司非常重視個人信息保護和數據安全。
“ZAO”道歉的相關話題很快沖上熱搜榜,但由此引發的隱私保護爭議和反思并未平息。隨后,工信部約談 ZAO :要求自查整改,依法依規收集使用個人信息!
作為程序員,不會換臉軟件怎么能忍?下面教大家徒手使用 Deepfakes 換臉。
如何使用 Deepfakes 換臉?
獲取 deepfakes 工具包
- git clone https://github.com/deepfakes/faceswap.git
補齊依賴包:
- pip install tqdm
- pip install cv2
- pip install opencv-contrib-python
- pip install dlib
- pip install keras
- pip install tensorflow
- pip install tensorflow-gpu(如機器帶有gpu)
- pip install face_recognition
收集樣本
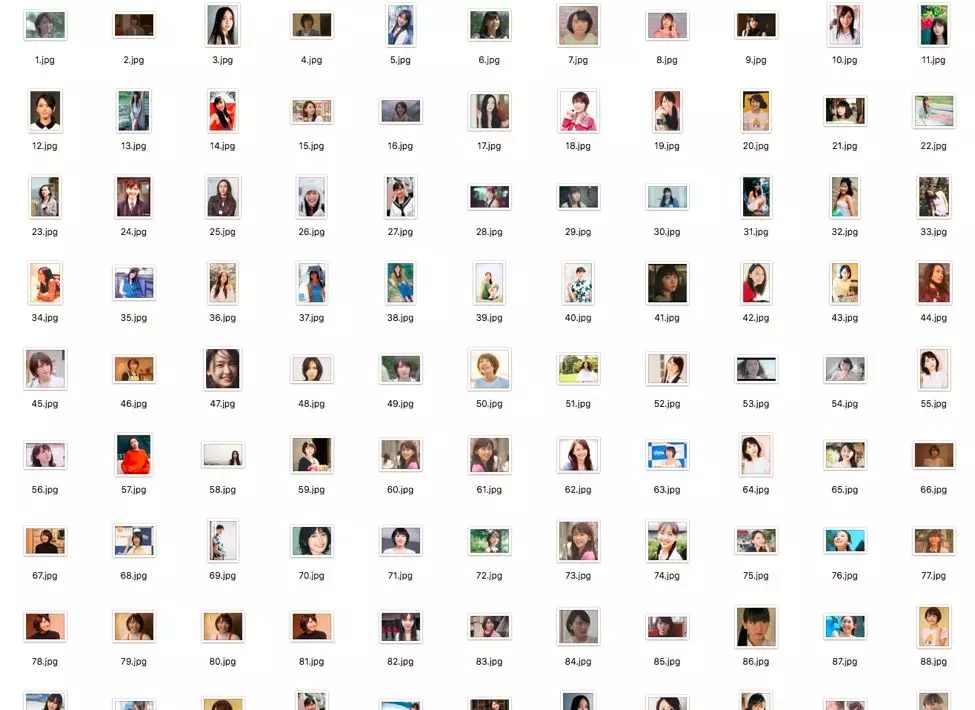
這里我選用的是新垣結衣的樣本,費了好半天,下了 100 張圖片:
另外一個人的樣本是凱瑞穆里根,由于實在是找圖片麻煩,所以直接截取了《The Great Gatsby》里的視頻,然后用 ffmpeg 轉化為圖片,大概有 70 張的樣子。
面部抓取
在收集完樣本后,使用如下命令對樣本圖片進行面部抓取:
./faceswap.py extract –i input_folder/ –o output_folder/
做這個的原因是因為我們主要關注的是換臉,所以只需要獲取臉部的特征,其他環境因素對換臉的影響并不大。

在面部抓取的過程完成后,我們可以得到所有臉部圖片。在此,我們可以人工篩選一下不合適的樣本(如下圖中的 49_1.jpg),將之去除。

面部檢測算法 HOG
這里簡單提一下臉部特征提取算法 HOG(Histogram of Oriented Gradient)。
嚴格來說,其實 HOG 是一個特征,是一種在計算機視覺和圖像處理中用來進行物體檢測的特征描述因子。HOG 特征結合 SVM 分類器已經被廣泛應用于圖像識別中。
此處臉部檢測的一個簡單過程如下:
①首先使用黑白來表示一個圖片,以此簡化這個過程(因為我們并不需要顏色數據來檢測一個臉部)。

②然后依次掃描圖片上的每一個像素點 。對每個像素點,找到與它直接相鄰的像素點。然后找出這個點周圍暗度變化的方向。
例如下圖所示,這個點周圍由明到暗的方向為從左下角到右上角,所以它的梯度方向為如下箭頭所示:

③在上一個步驟完成后,一個圖片里所有的像素點均可由一個對應的梯度表示。這些箭頭表示了整個圖片里由明到暗的一個趨勢。
如果我們直接分析這些像素點(也就是按色彩的方式分析),那么那些非常亮的點和非常暗的點,它們的值(RGB 值)肯定有非常大的差別。
但是因為我們在這只關注明亮度改變的方向,所以由有色圖和黑白圖最終得到的結果都是一樣的,這樣可以極大簡化問題解決的過程。

④但是保存所有這些梯度會是一個較為消耗存儲的過程,所以我們將整個圖片分成多個小方塊,并且計算里面有多少不同的梯度。
然后我們使用相同梯度最多的方向來表示這個小方塊的梯度方向。這樣可以將原圖片轉化為一個非常簡單的表現方式,并以一種較簡單的方法抓取到面部的基本結構。

⑤當計算到一個圖片的 HOG 特征后,可以使用這個特征來對通過訓練大量圖片得出的 HOG 特征進行比對。如果相似度超過某個閾值,則認為面部被檢測到。

開始訓練
在提取兩個人臉的面部信息后,直接使用下面命令開始進行模型的訓練:
- ./faceswap.py train -A faceA_folder/ -B faceB_folder -m models/
其中 -m 指定被保存的 Models 所在的文件夾。也可以在命令里加上 -p 參數開啟 Preview 模式。
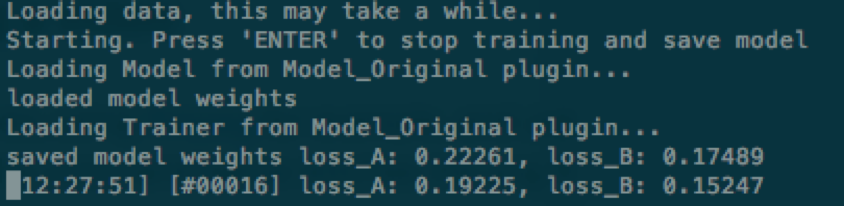
在訓練過程中,可以隨時鍵入 Enter 停止訓練,模型會保存在目標文件夾。
訓練使用的深度學習框架是 Tensorflow,它提供了保存 Checkpoint 的機制(當然代碼里必須用上)。
在停止訓練后,以后也可以隨時使用上面的命令讀取之前訓練得出的權重參數,并繼續訓練。
轉換人臉
在訓練完模型后(損失值較低),可以使用以下命令對目標圖進行換臉:
- ./faceswap.py –i input_images_folder/ -o output_images_folder/ -m models/
此處的例子是找的一個視頻,所以我們可以先用下面的命令將一個視頻以一個固定頻率轉化為圖片:
- ffmpeg –i video.mp4 output/video-frame-%d.png
然后執行轉換人臉操作。最后將轉換后的人臉圖片集合,合成一個視頻:
- ffmpeg –i video-frame-%0d.png -c:v libx264 -vf “fps=25, format=yuv420p” out.mp4
下面是兩個換臉圖(樣本 A,110 張圖片;樣本 B,70 張圖片,訓練時間 6 小時):


嗯…效果不咋樣… 建議大家可以增大樣本量,并延長訓練時間。
轉換人臉的過程
下面簡單的聊一下轉換人臉的過程。這里用到了 AutoEncoder(一種卷積神經網絡),它會根據輸入圖片,重構這個圖片(也就是根據這個圖片再生成這個圖片):
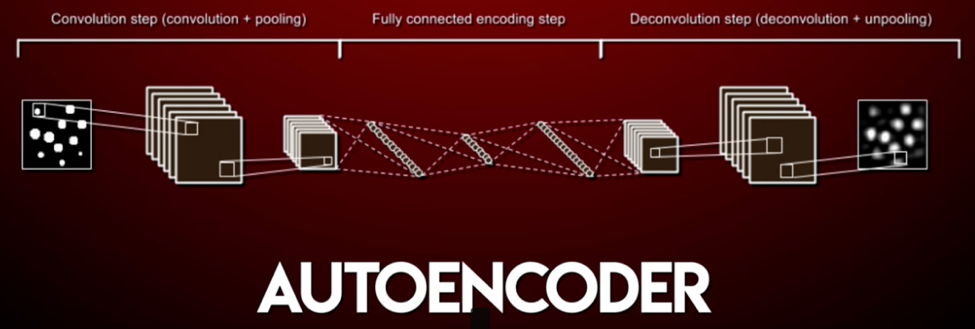
這里 AutoEncoder 模型做的是:首先使用 Encoder 將一個圖片進行處理(卷積神經網絡抽取特征),以一種壓縮的方式來表示這個圖片。然后 Decoder 將這個圖片還原。
具體在 Deepfakes 中,它用了一個 Encoder 和兩個 Decoder。在訓練的部分,其實它訓練了兩個神經網絡,兩個神經網絡都共用一個 Encoder,但是均有不同的 Decoder。
首先 Encoder 將一個圖片轉化為面部特征(通過卷積神經網絡抽取面部的細節特征)。然后 Decoder 通過這個面部特征數據,將圖片還原。
這里有一個 error function(loss function)來判斷這個轉換的好壞程度,模型訓練的過程就是最小化這個 loss function(value)的過程。
第一個網絡只訓練圖片 A,第二個網絡只訓練圖片 B。Encoder 學習如何將一個圖片轉化為面部特征值。
Decoder A 用于學習如何通過面部特征值重構圖片 A,Decoder B 用于學習如何通過面部特征值重構圖片 B。
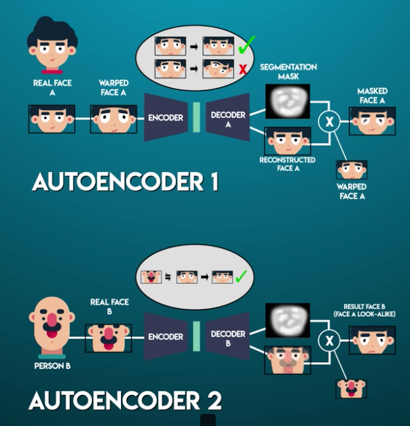

所以在訓練時,我們會將兩個圖片均送入同一個 Encoder,但是用兩個不同的 Decoder 還原圖片。
這樣最后我們用圖片 B 獲取到的臉,使用 Encoder 抽取特征,再使用 A 的 Decoder 還原,便會得到 A 的臉,B 的表情。