超原版速度110倍,針對PyTorch的CPU到GPU張量遷移工具開源
機器學習中,有一個限制速度的環節,那就是從 CPU 到 GPU 之間的張量遷移。很多計算只能在 CPU 上進行,然后遷移到 GPU 進行后續的訓練工作,因此遷移中如果速度太慢,則會拖累整個模型的訓練效率。近日,有一位開發者開源了針對 PyTorch 的 CPU->GPU 遷移工具,相比原版加速了 110 倍之多。
神經網絡的訓練中往往需要進行很多環節的加速,這就是為什么我們逐漸使用 GPU 替代 CPU、使用各種各樣的算法來加速機器學習過程。但是,在很多情況下,GPU 并不能完成 CPU 進行的很多操作。比如訓練詞嵌入時,計算是在 CPU 上進行的,然后需要將訓練好的詞嵌入轉移到 GPU 上進行訓練。
在這一過程中,張量遷移可能會變得非常緩慢,這成為了機器學習訓練的一個瓶頸。
面對這樣的問題,在很多優化方法中,就是將操作盡可能放在 GPU 上(如直接在 GPU 上進行數據預處理、詞嵌入等的操作),并努力減少兩者之間的數據交互,因為這些環節都很費時。機器之心就曾報道過這樣的一個教程,將數據預處理放在了 GPU 上,減少了不少時間。
以上事例說明,如果能夠做好 CPU 和 GPU 之間的遷移,則可以幫助開發者更好地優化機器學習模型,使 CPU、GPU 等硬件更好地完成自己的工作。
近日,有一位開發者就開源了一個名為 SpeedTorch 的工具。這一工具庫可以實現高達 110 倍的 CPU 到 GPU 遷移加速。
項目地址:https://github.com/Santosh-Gupta/SpeedTorch
項目背景
作者表示,最初想要創建 SpeedTorch 庫是為了幫助訓練大量的嵌入向量,而 GPU 在 RAM 保存這些嵌入時可能有困難。為了解決這個問題,他發現在 CPU 上托管一些此類嵌入有助于在 GPU 上保存它們。嵌入系統采用稀疏訓練,只有一部分參數參與前饋/更新操作,剩余參數處于閑置狀態。所以作者想到,為什么不在訓練的過程中關閉這些閑置參數呢?這就需要快速的 CPU→GPU 數據遷移能力。
隨著 CPU→GPU 遷移速度的加快,除了加速了 CPU 到 GPU 的張量轉移外,開發者還可以實現很多新的功能。
- 將 SpeedTorch 庫嵌入數據管道中,實現 CPU 和 GPU 之間快速的雙向數據交互;
- 通過 CPU 存儲將模型的訓練參數增加近兩倍(閑置參數保存在 CPU 中,需要更新時再移動到 GPU 里,因此可以擴大模型整體的參數量);
- 在訓練稀疏嵌入向量中采用 Adadelta、Adamax、RMSprop、Rprop、ASGD、AdamW 和 Adam 優化器。之前只有 SpraseAdam、Adagrad 和 SGD 適合稀疏嵌入訓練。
那么,能夠實現如此驚人的加速的庫是怎么實現的呢?
SpeedTorch
背后的技術
SpeedTorch 如此之快的技術是因為它是基于 Cupy 開發的。CuPy 是一個借助 CUDA GPU 庫在英偉達 GPU 上實現 Numpy 數組的庫。基于 Numpy 數組的實現,GPU 自身具有的多個 CUDA 核心可以促成更好的并行加速。

CuPy 接口是 Numpy 的一個鏡像,并且在大多情況下,它可以直接替換 Numpy 使用。只要用兼容的 CuPy 代碼替換 Numpy 代碼,用戶就可以實現 GPU 加速。
CuPy 支持 Numpy 的大多數數組運算,包括索引、廣播、數組數學以及各種矩陣變換。
有了這樣強大的底層支持,再加上一些優化方法,SpeedTorch 就能達到 110 倍的速度了。
使用方法
SpeedTorch 可以通過 pip 安裝。你需要在導入 SpeedTorch 之前事先安裝和導入 Cupy。
安裝步驟如下:
- !pip install SpeedTorch
- import cupy
- import SpeedTorch
利用 SpeedTorch 加快 CPU→GPU 數據遷移速度
如下 colab notebook 所示,如何利用 Data Gadget 將數據載入 SpeedTorch,以及如何將數據移入/移出 Pytorch cuda 變量。

代碼示例:https://colab.research.google.com/drive/185Z5Gi62AZxh-EeMfrTtjqxEifHOBXxF
借助于 SpeedTorch 將非稀疏優化器(本例中為 Adamax)用于稀疏訓練
- SkipGram_ModelRegular = SkipGramModelRegular(numEmbeds=number_items, emb_dimension=128, sparseB=True)
- use_cuda = torch.cuda.is_available()
- if use_cuda:
- SkipGram_ModelRegular.cuda()
- optimizer = optim.SparseAdam(
- SkipGram_ModelRegular.parameters())
- runningLoss = 0
- runnngTime = 0
- batch_size = 512
- negSamp = 64
- numPos = 4
- skip_window = int(numPos/2)
- targets = torch.ones( batch_size, numPos + negSamp , dtype = torch.float32 ).cuda()
- for i in range(500):
- batch, labels, negz = generate_batch(batch_size=batch_size, skip_window=skip_window, negRate= negSamp)
- batchTensor = torch.from_numpy(batch)
- LabelTensor = torch.from_numpy(labels)
- negTensor = torch.from_numpy(negz)
- pos_u = Variable(torch.LongTensor(LabelTensor.long()))
- pos_v = Variable(torch.LongTensor(batchTensor.long()))
- neg_v = Variable(torch.LongTensor(negTensor.long()))
- if use_cuda:
- pos_u = pos_u.cuda()
- pos_v = pos_v.cuda()
- neg_v = neg_v.cuda()
- optimizer.zero_grad()
- loss = SkipGram_ModelRegular.forward(pos_u, pos_v, neg_v, targets)
- runningLoss = runningLoss + loss.data.item()
- loss.backward()
- optimizer.step()
代碼示例: https://colab.research.google.com/drive/1ApJR3onbgQWM3FBcBKMvwaGXIDXlDXOt
以上展示了如何以常規的方式訓練 word2vec,隨后展示了如何使用 SpeedTorch 在同樣的數據上進行訓練——在通常不支持稀疏訓練的優化器上。因為嵌入變量包含的所有嵌入在每一部上都有更新,你可以在初始化期間將 sparse=False。
效果
這一部分記錄了 Cupy/PyTorch 張量和 PyTorch 變量之間的數據遷移速度。其中,需要遷移 128 維的嵌入向量,共有 131,072 個 32 位浮點數。使用了如下的代碼進行測試工作。所有測試都使用了特斯拉 K80 GPU。
測試代碼鏈接:https://colab.research.google.com/drive/1b3QpfSETePo-J2TjyO6D2LgTCjVrT1lu
下表是結果摘要。在同樣情況下,將數據從 PyTorch CUDA 張量傳遞到 CUDA PyTorch 嵌入變量上是要比 SpeedTorch 更快的,但對于所有其他的傳輸類型,SpeedTorch 更快。對于轉移到 Cuda Pytorch 嵌入,或從 Cuda Pytorch 嵌入轉移的兩個步驟的總和上來說,SpeedTorch 比常規 GPU 和 CPU Pinned 張量的 Pytorch 速度同樣快。
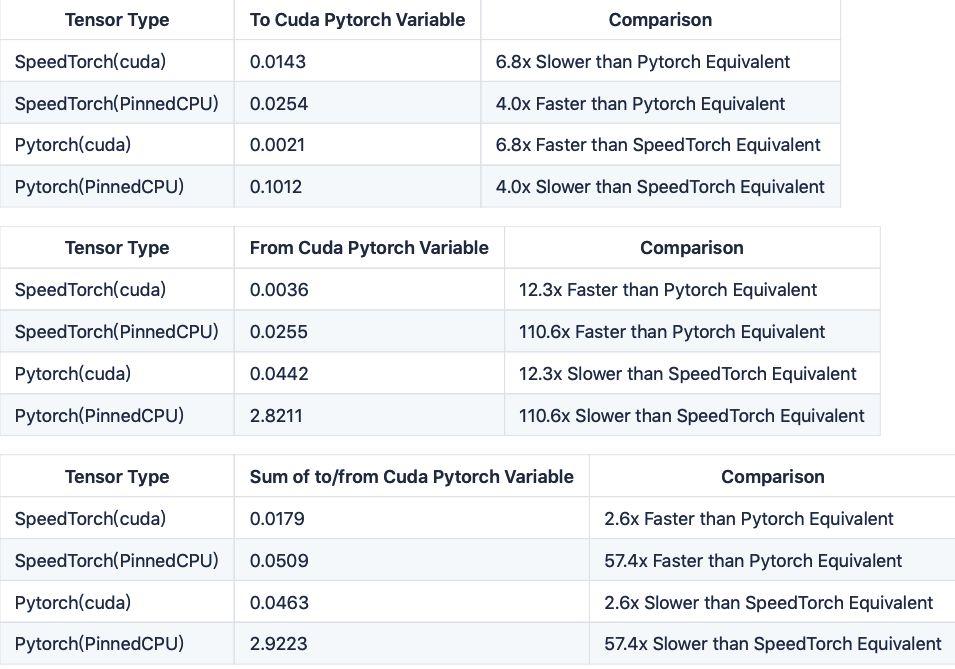
從表中可以看出,這是 SpeedTorch 確實比 PyTorch 自帶的數據遷移方法要快很多。