













讓模型訓練速度提升兩到四倍,「彩票假設」作者的這個全新PyTorch庫火了
隨著越來越多的企業轉向人工智能來完成各種各樣的任務,企業很快發現,訓練人工智能模型是昂貴的、困難的和耗時的。
一家公司 MosaicML 的目標正是找到一種新的方法來應對這些層出不窮的挑戰。近日, MosaicML 推出了一個用于高效神經網絡訓練的 PyTorch 庫「Composer」,旨在更快地訓練模型、降低成本,并獲得表現更好的模型。
Composer 是一個用 PyTorch 編寫的開源庫,旨在集成更好的算法來加速深度學習模型的訓練,同時實現更低的成本和更高的準確度。目前項目在 GitHub 平臺已經收獲了超過 800 個 Star。

項目地址:https://github.com/mosaicml/composer

Composer 具有一個功能界面(類似于 torch.nn.functional),用戶可以將其集成到自己的訓練循環中;它還包含一個 Trainer,可以將高效的訓練算法無縫集成到訓練循環中。
項目中已經部署了 20 幾種加速方法,只需幾行代碼就能應用在用戶的訓練之中,或者與內置 Trainer 一起使用。
總體而言,Composer 具備幾個亮點:
- 20 多種加速計算機視覺和語言建模訓練網絡的方法。當 Composer 為你完成工作時,你就不需要浪費時間嘗試復現研究論文。
- 一個易于使用的 Trainer,其編寫的目的是盡可能提高性能,并集成了高效訓練的最佳實踐。
- 所有加速方法的功能形式,都允許用戶將它們集成到現有的訓練循環中。
- 強大、可重現的基線,讓你盡可能地快開始工作。
那么,使用 Composer 能夠獲得怎樣的訓練效果提升呢?
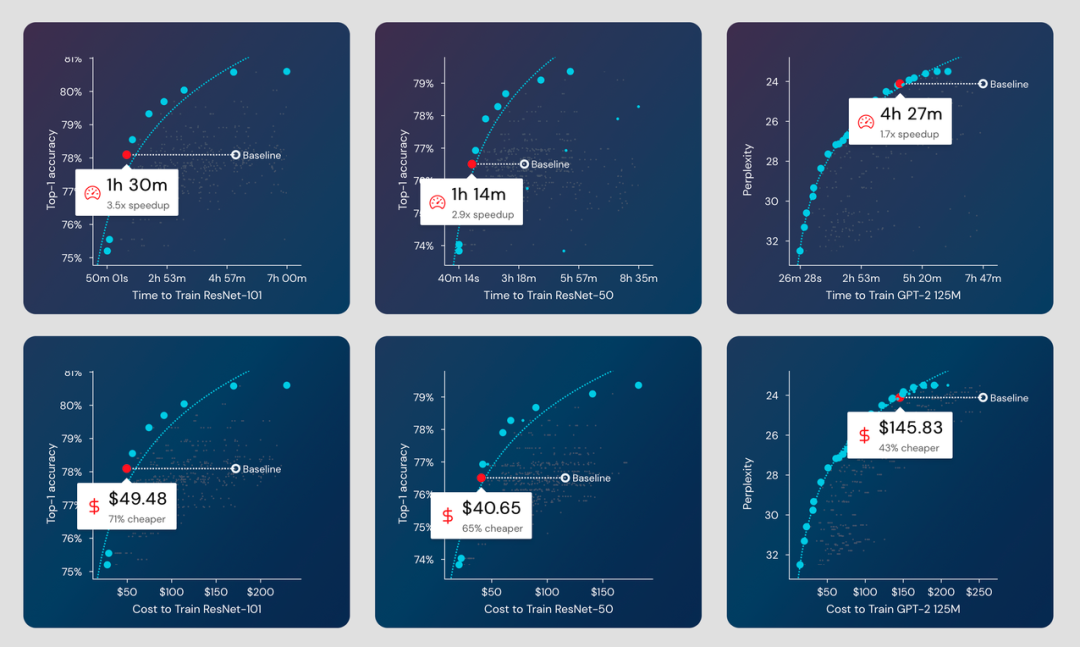 多個模型系列的訓練中減少的時間和成本。
多個模型系列的訓練中減少的時間和成本。
據項目信息介紹,使用 Composer 訓練,你可以做到:
- ResNet-101 在 ImageNet 上的準確率在 1 小時 30 分鐘內達到 78.1%(AWS 上 49 美元),比基線快 3.5 倍,便宜 71%。
- ResNet-50 在 ImageNet 上的準確率在 1 小時 14 分鐘內達到 76.51%(AWS 上 40 美元),比基線快 2.9 倍,便宜 65%。
- 在 4 小時 27 分鐘內將 GPT-2 在 OpenWebText 上的困惑度提高到 24.11(AWS 上 145 美元),比基線快 1.7 倍,便宜 43%。
在 Reddit 社區,項目作者 Jonathan Frankle 現身說法,他介紹說,Composer 是自己關于彩票假設研究的直接延續。
2019 年,Frankle 和 Carbin 的《The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks》獲得了 ICLR 2019 的最佳論文榮譽。在這篇論文中,Frankle 等人發現標準的剪枝技術會自然地發現子網絡,這些子網絡經過初始化后能夠有效進行訓練。二人基于這些結果提出了「彩票假設」(lottery ticket hypothesis):密集、隨機初始化的前饋網絡包含子網絡(「中獎彩票」),當獨立訓練時,這些子網絡能夠在相似的迭代次數內達到與原始網絡相當的測試準確率。
目前,Frankle 是 Mosaic 公司的首席科學家,推動了 Composer 的打造。
這次,Frankle 表示,深度學習背后的「數學」并沒有什么神圣之處。從根本上改變「數學」是完全沒問題的(比如刪除很多權重)。你將獲得與其他方式不同的網絡,但這不像原始網絡是「正確的」網絡。如果改變「數學」讓你的網絡變得同樣好(例如同樣的準確性)而速度更快,那就是勝利。
如果你愿意打破深度學習背后的「數學」,彩票假設就是一個例子。Composer 有幾十種技術可以做到這一點,并且擁有與之匹配的加速。
同時,項目作者們也將 Composer 與 PyTorch Lightning 進行了對比:「PyTorch Lightning 是一個具有不同 API 的不同訓練庫。實際上,我們在 PTL 之上構建了我們的第一個 Composer 實現。」

PyTorch Lightning 的創建者 William Falcon 也出現在了后續討論中,但二人似乎未達成共識。
目前,Composer 的訓練器可以應用于眾多模型,包括對于 Resnet-50、Resnet-101、UNet 和 GPT-2 的加速。
作者表示,未來還將擴展至更多模型,比如 ViT、BERT、分割和目標檢測等等。

























