從源碼看Spark讀取Hive表數據小文件和分塊的問題
前言
有同事問到,Spark讀取一張Hive表的數據Task有一萬多個,看了Hive表分區下都是3MB~4MB的小文件,每個Task只處理這么小的文件,實在浪費資源浪費時間。而我們都知道Spark的Task數由partitions決定,所以他想通過repartition(num)的方式來改變分區數,結果發現讀取文件的時候Task數并沒有改變。遂問我有什么參數可以設置,從而改變讀取Hive表時的Task數,將小文件合并大文件讀上來
本文涉及源碼基于Spark2.0.0和Hadoop2.6.0,不同版本代碼可能不一致,需自己對應。此外針對TextInputFormat格式的Hive表,其他格式的比如Parquet有Spark自己的高效實現,不在討論范圍之內
分析
Spark讀取Hive表是通過HadoopRDD掃描上來的,具體可見 org.apache.spark.sql.hive.TableReader類,構建HadoopRDD的代碼如下
- val rdd = new HadoopRDD(
- sparkSession.sparkContext,
- _broadcastedHadoopConf.asInstanceOf[Broadcast[SerializableConfiguration]],
- Some(initializeJobConfFunc),
- inputFormatClass,
- classOf[Writable],
- classOf[Writable],
- _minSplitsPerRDD)
這里inputFormatClass是Hive創建時指定的,默認不指定為 org.apache.hadoop.mapred.TextInputFormat,由它就涉及到了HDFS文件的FileSplit數,從而決定了上層Spark的partition數。在進入HadoopRDD類查看之前,還有一個參數需要我們注意,就是 _minSplitsPerRDD,它在后面SplitSize的計算中是起了作用的。
我們看一下它的定義
- private val _minSplitsPerRDD = if (sparkSession.sparkContext.isLocal) {
- 0 // will splitted based on block by default.
- } else {
- math.max(hadoopConf.getInt("mapred.map.tasks", 1),
- sparkSession.sparkContext.defaultMinPartitions)
- }
在我們指定以--master local模式跑的時候,它為0,而在其他模式下,則是求的一個***值。這里重點看 defaultMinPartitions,如下
- def defaultMinPartitions: Int = math.min(defaultParallelism, 2)
- // defaultParallelism 在yarn和standalone模式下的計算
- def defaultParallelism(): Int = {
- conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
- }
從這里可以看到,defaultMinPartitions的值一般為2,而 mapred.map.tasks 或者 mapreduce.job.maps( 新版參數)是Hadoop的內建參數,其默認值也為2,一般很少去改變它。所以這里_minSplitsPerRDD的值基本就是2了。
下面我們跟到HadoopRDD類里,去看看它的partitions是如何來的
- def getPartitions: Array[Partition] = {
- val jobConf = getJobConf()
- // add the credentials here as this can be called before SparkContext initialized
- SparkHadoopUtil.get.addCredentials(jobConf)
- // inputFormat就是上面參數inputFormatClass所配置的類的實例
- val inputFormat = getInputFormat(jobConf)
- // 此處獲取FileSplit數,minPartitions就是上面的_minSplitsPerRDD
- val inputSplits = inputFormat.getSplits(jobConf, minPartitions)
- val array = new Array[Partition](inputSplits.size)
- // 從這里可以看出FileSplit數決定了Spark掃描Hive表的partition數
- for (i <- 0 until inputSplits.size) {
- array(i) = new HadoopPartition(id, i, inputSplits(i))
- }
- array
- }
在 getPartitions 方法里我們可以看到 FileSplit數***決定了Spark讀取Hive表的Task數,下面我們再來看看 mapred.TextInputFormat 類里 getSplits 的實現
分兩步來看,首先是掃描文件,計算文件大小的部分
- FileStatus[] files = listStatus(job);
- .....
- long totalSize = 0; // compute total size
- for (FileStatus file: files) { // check we have valid files
- if (file.isDirectory()) {
- throw new IOException("Not a file: "+ file.getPath());
- }
- totalSize += file.getLen();
- }
- // numSplits就是上面傳入的minPartitions,為2
- long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
- long minSize = Math.max(job.getLong("mapreduce.input.fileinputformat.split.minsize", 1), minSplitSize);
- // minSplitSize 默認為1,唯一可通過 setMinSplitSize 方法設置
- private long minSplitSize = 1;
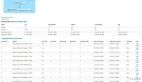
針對Hive表的分區,Spark對每個分區都構建了一個HadoopRDD,每個分區目錄下就是實際的數據文件,例如我們集群的某一張表按天分區,每天下面有200個數據文件,每個文件大概3MB~4MB之間,這些實際上是reduce設置不合理導致的小文件產生,如下圖

此處 listStatus 方法就是掃描的分區目錄,它返回的就是圖中顯示的具體 part-*****文件的FileStatus對象,一共200個。從 totalSize 的計算可以看出,它是這200個文件的總大小,為838MB,因此 goalSize 就為419MB。
參數 mapreduce.input.fileinputformat.split.minsize 在Spark程序沒有配的情況下,獲取的值為0,而 minSplitSize在Spark獲取FileSplits的時候并沒有被設置,所以為默認值1,那么 minSize 就為1
其次,我們再來看從文件劃分Split,部分代碼如下(部分解釋見注釋)
- ArrayList splits = new ArrayList(numSplits);
- NetworkTopology clusterMap = new NetworkTopology();
- // files是上面掃描的分區目錄下的part-*****文件
- for (FileStatus file: files) {
- Path path = file.getPath();
- long length = file.getLen();
- if (length != 0) {
- FileSystem fs = path.getFileSystem(job);
- BlockLocation[] blkLocations;
- if (file instanceof LocatedFileStatus) {
- blkLocations = ((LocatedFileStatus) file).getBlockLocations();
- } else {
- blkLocations = fs.getFileBlockLocations(file, 0, length);
- }
- // 判斷文件是否可切割
- if (isSplitable(fs, path)) {
- // 這里獲取的不是文件本身的大小,它的大小從上面的length就可以知道,這里獲取的是HDFS文件塊(跟文件本身沒有關系)的大小
- // HDFS文件塊的大小由兩個參數決定,分別是 dfs.block.size 和 fs.local.block.size
- // 在HDFS集群模式下,由 dfs.block.size 決定,對于Hadoop2.0來說,默認值是128MB
- // 在HDFS的local模式下,由 fs.local.block.size 決定,默認值是32MB
- long blockSize = file.getBlockSize(); // 128MB
- // 這里計算splitSize,根據前面計算的goalSize=419MB,minSize為1
- long splitSize = computeSplitSize(goalSize, minSize, blockSize);
- long bytesRemaining = length;
- // 如果文件大小大于splitSize,就按照splitSize對它進行分塊
- // 由此可以看出,這里是為了并行化更好,所以按照splitSize會對文件分的更細,因而split會更多
- while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
- String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
- length-bytesRemaining, splitSize, clusterMap);
- splits.add(makeSplit(path, length-bytesRemaining, splitSize,
- splitHosts[0], splitHosts[1]));
- bytesRemaining -= splitSize;
- }
- if (bytesRemaining != 0) {
- String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- - bytesRemaining, bytesRemaining, clusterMap);
- splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
- splitHosts[0], splitHosts[1]));
- }
- } else {
- String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
- splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
- }
- } else {
- //Create empty hosts array for zero length files
- splits.add(makeSplit(path, 0, length, new String[0]));
- }
- }
從上面可以看到,splitSize是從 computeSplitSize(goalSize, minSize, blockSize) 計算來的,這三個參數我們都知道大小,那么計算規則是怎么樣的呢
規則:Math.max(minSize, Math.min(goalSize, blockSize)),從而我們可以知道 splitSize = 128MB,對于3MB~4MB的小文件來說,就 決定了一個小文件就是一個split了,從而對應了一個Spark的partition,所以我們一個分區下就有200個partition,當取兩個月的數據時,就是 200 * 30 * 2 = 12000,從而是12000個Task,跟同事所說的吻合!
> 而從TextInputFormat里分Split的邏輯來看,它只會把一個文件分得越來越小,而不會對小文件采取合并,所以無論調整哪個參數,都沒法改變這種情況!而通過repartition強行分區,也是在拿到HDFS文件之后對這12000個partition進行重分區,改變不了小文件的問題,也無法改變讀取Hive表Task數多的情況
總結
1、Block是物理概念,而Split是邏輯概念,***數據的分片是根據Split來的。一個文件可能大于BlockSize也可能小于BlockSize,大于它就會被分成多個Block存儲到不同的機器上,SplitSize可能大于BlockSize也可能小于BlockSize,SplitSize如果大于BlockSize,那么一個Split就可能要跨多個Block。對于數據分隔符而言,不用擔心一個完整的句子分在兩個Block里,因為在Split構建RecordReader時,它會被補充完整
2、對于采用 org.apache.hadoop.mapred.TextInputFormat 作為InputFormat的Hive表,如果存在小文件,Spark在讀取的時候單憑調參數和repartition是改變不了分區數的!對于小文件的合并,目前除了Hadoop提供的Archive方式之外,也只能通過寫MR來手動合了,***的方式還是寫數據的時候自己控制reduce的個數,把握文件數
3、對于Spark直接通過SparkContext的 textFile(inputPath, numPartitions) 方法讀取HDFS文件的,它底層也是通過HadoopRDD構建的,它的參數numPartitions就是上面計算goalSize的numSplits參數,這篇 文章 對原理描述的非常詳細,非常值得一讀
4、對于小文件合并的InputFormat有 org.apache.hadoop.mapred.lib.CombineFileInputFormat,跟它相關的參數是 mapreduce.input.fileinputformat.split.maxsize,它用于設置一個Split的***值
5、跟mapred.TextInputFormat 里的Split劃分相關的參數
- mapreduce.input.fileinputformat.split.minsize : 決定了計算Split劃分時的minSize
- mapreduce.job.maps 或 mapred.map.tasks : 決定了getSplits(JobConf job, int numSplits)方法里的numSplits,從而可以影響goalSize的大小
- dfs.block.size 或 fs.local.block.size : 決定了HDFS的BlockSize
6、MapReduce新版API里的 org.apache.hadoop.mapreduce.lib.input.TextInputFormat,它的SplitSize與上面說到的計算方式不一樣,getSplits方法的簽名為 getSplits(JobContext job),不再有numSplilts這個參數,splitSize的計算規則改為 Math.max(minSize, Math.min(maxSize, blockSize)),minSize和blockSize跟之前一樣,新的maxSize為conf.getLong("mapreduce.input.fileinputformat.split.maxsize", Long.MAX_VALUE)
7、在Spark2.0.0里,設置Hadoop相關的參數(比如mapreduce開頭的)要通過 spark.sparkContext.hadoopConfiguration 來設置