模仿川普語氣真假難分:從未如此逼真,超強編故事AI完全體來了
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
還記得那個編故事能以假亂真的AI模型嗎?
它叫GPT-2,因為效果太好,OpenAI說不能放出全部——讓壞人誤用就不好了。
于是,它初出茅廬時先放出了124M版本的模型,然后是355M,再然后是774M。
被業內稱為“擠牙膏式開源”。
然而沒想到,經過9個月斷斷續續發布,OpenAI終于把15億參數的完整模型,放了出來。
正所謂好飯不怕晚,官方版放出之后也引起了好多人圍觀。
有人說“好人一生平安”。也有人給OpenAI點贊,說唯一安全的AI,就是面向所有人的AI,而不是少數人的AI。
不少人也感嘆于15億參數模型的效果,表示“假論文”的時代不遠了。

但更多的人是想扒清楚:
這個當初“吊炸天”的AI模型,到底有沒有那么玄乎?
實測15億版本模型
先來看看我們上手測試的效果吧。
首先,我們問它對熬夜變傻有科學依據了怎么看,輸入是這樣的:
There’s scientific evidence that staying up late makes you stupid.
它竟然給出了一個Twitter體的回答,還順便Q了一下川建國:
There’s scientific evidence that staying up late makes you stupid. So why is it okay for the president to be up late every night, and be tweeting?
https://t.co/0j5cFZ5sXS — The Daily Show (@TheDailyShow) January 6, 2017
熬夜變傻有科學依據了。那么,為什么總統每天晚上很晚才起床,還要發推呢?
https://t.co/0j5cFZ5sXS—TheDailyShow (@TheDailyShow) 2017年1月6日
Here’s where Trump got it right:
這就是特朗普認為這樣做正確的地方:
If I had been a wiser man, I would have used the term “sad” to describe my feelings toward watching all of you go to sleep. Sad! — Donald J. Trump (@realDonaldTrump) January 6, 2017
如果我是個明智的人,我就會用“難過”這個詞來形容我看著你們所有人入睡的感受。難過!
—唐納德·特朗普(@realDonaldTrump) 2017年1月6日
甚至還有推文鏈接、具體的賬號和時間。
嚇得我們趕緊去查了查,還好鏈接是胡編的,根本打不開。但這些推文賬號都存在。
如此效果,很讓我們震驚,將這個感受輸入進去:
The editors were shocked by the effect.
然后得到了這樣的“胡編”生成結果:
A few years later, in the late 1990s, a book was published that offered evidence for the existence of a “gene for human intelligence.”
幾年后,也就是20世紀90年代末,一本書出版了,為“人類智力基因”的存在提供了證據。
“I’m just astonished that this is the case,” said Robert Rosenthal, a psychologist at the University of California at San Diego who was one of the editors of the report.
“我只是對這種情況感到驚訝,”加州大學圣地亞哥分校的心理學家、該報告的編輯之一羅伯特·羅森塔爾說。
Rosenthal called the notion that intelligence can be detected with DNA “totally implausible.”
羅森塔爾稱,智力可以通過 DNA 檢測的說法“完全不可信”
雖然真實性有待考證,但這個邏輯已經像模像樣,而且有細節、有論證,不了解實情的人,可能真的會被忽悠過去。
模型更大,胡編的能力也更強了
OpenAI在博客里說,GPT-2的生成結果,有獨立客觀第三方的檢驗,令人信服:
團隊在康奈爾大學的合作伙伴,對人類做了問卷調查,給GPT-2輸出的文本打出可信分 (Credibility Score) ,各種大小的模型都參與了。
滿分10分,大家給15億參數模型的可信分是6.91。比7.74億參數的模型 (6.72分) 和 3.55億參數的模型 (6.07分) 都要高。
也就是說在人類眼里,15億參數模型,比之前放出的那些模型,寫出的文章更逼真了。
那么在AI眼里,會不會也是如此?
于是寫個檢測算法,識別哪些是GPT-2寫的文章,哪些是人類寫的文章,同樣是一項重要的工作。
OpenAI做了一個檢測模型,識別15億模型生成的文本,準確率大約95%。但這還不代表AI生成的文本是安全的。
因為,團隊又對檢測算法做了更仔細的考察,跨數據集的那種。
比如,訓練時用3.55億參數模型的作品,測試時卻要識別15億參數模型的文章;訓練針對15億參數模型,測試時要識別3.55億參數模型的作品等等。
結果如下:
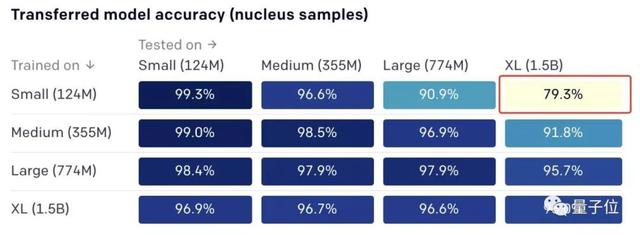
目前看來,用大模型的作品當訓練集,可以輕松識別小模型的作品;但用小模型的作品當訓練集,要識別大模型的作品,頗有些難度。
比如,用1.24億參數模型的文章訓練之后,再讓算法識別15億參數模型的作品,準確率只有79.3%。反過來,準確率有96.9%。
總體來看,15億參數模型的作品,依然是最難識別的。
得出這樣的結果,一方面看出15億參數模型比從前的模型更強大。另一方面,也表示檢測真偽的算法還有很長的路要走。
但也有人指出了這個模型存在的另外一些問題:
文本生成模型夠大了,但我們需要的是可控的文本生成。

使用建議
所以,這個版本的GPT-2應該怎么用?
首先,當然是到GPT-2的GitHub倉庫里下載15億參數版完整模型,自己動手調教出你想要的功能。
https://github.com/openai/gpt-2
不過,這比較適合AI專業人士操作。有人讀了源碼之后,直言頭大:
1、到處是單字母變量;2、代碼本身幾乎沒有文檔;3、到處都是魔術常數;4、函數名過于簡潔。

如果你想立刻上手嘗試,已經有人把代碼移植到了Colab上。
https://colab.research.google.com/drive/1BXry0kcm869-RVHHiY6NZmY9uBzbkf1Q
并且還推出了配套的GPT-2調教教程《GPT-2神經網絡詩歌》。
https://www.gwern.net/GPT-2
此外,Hugging Face(抱抱臉)也已經第一時間將這一模型添加到了萬星項目Transformers中,一個API就能調用GPT-2 15億參數版本。在線上Demo中也已經可以直接試用。
https://transformer.huggingface.co/doc/gpt2-xl
如果你只是想體驗一下效果,還有人在網站上集成了GPT-2 15億參數模型的功能,輸入開頭,即可一鍵生成文本。
https://talktotransformer.com/
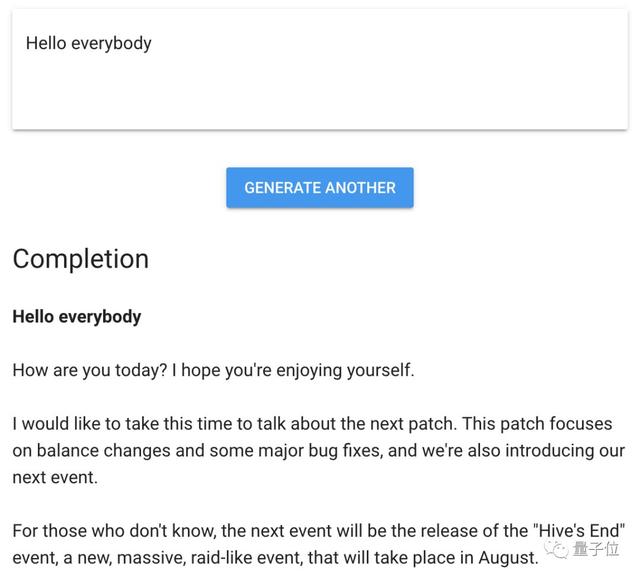
按照OpenAI的預期,這一完整模型將主要服務于AI研究人員和從業人員,幫助人們更好地理解生成語言模型的行為、功能、偏見和約束。
下一步往哪里去?
不難看出,OpenAI發布的15億最大參數模型在輸出等方面還是取得了一定的進步。但同時,OpenAI也提出了在檢測方面所面臨的挑戰。
那么接下來,他們又會對這個模型做出怎樣的改進呢?
OpenAI表示:
在過去9個月的體驗時間里,我們深刻的了解到了在AI領域發布一個規范模型所帶來的挑戰與機遇。我們將繼續在模型規范方面進行進一步的研究與討論。
隨著進一步的研究,我們期望語言模型能夠在性能上有更大的提升,以此提供更高的輸出質量和準確性。
因此,為了有效的塑造語言模型的社會影響,OpenAI還確定了四個需要監控的趨勢。

趨勢一:語言模型正在向設備轉移
考慮到計算能力成本的歷史趨勢,以及當前在設備上執行機器學習訓練或推斷的速度,OpenAI預言:預言模型將更廣泛地部署在一系列的設備上,而不是服務器集群。
趨勢二:文本生成將變得更加可控
語言模型的潛在用途將得益于可靠性/可控性的發展,例如新的采樣方法、數據集、目標函數以及人機界面。
趨勢三:更多風險分析
目前,如何比較具有不同性能配置文件的兩種大型語言模型的可用性還有待商榷,尤其是在考慮微調的情況下。
一些主要的考慮因素包括:在沒有模型的情況下,借助于模型來產生給定數量的一定質量的文本所需的時間和專業知識。
除了在生成不同樣式的惡意內容時的性能差異之外,不同的模型或多或少將更容易適應不同的語言和主題。
而在不犧牲某些靈活性的情況下,將誤用的可能性降低到零似乎是困難的或不可能的。
還需要進一步的研究以及發展倫理規范來權衡這些問題。
趨勢四:提高工具的可用性
現如今,模型的訓練和部署需要機器學習技術的知識,工具技能以及訪問測試平臺進行評估的知識。
與語言模型交互的工具(例如與Transformer的對話和使用Transformer接口的編寫),將擴大能夠以各種不同方式使用語言模型的參與者的數量。
這些對工具可用性的改進將會對模型性能和抽樣方法起到改進的作用,使得更廣泛的創造性語言模型應用成為可能。
One more thing:GPT-2宇宙
從今天2月份,GPT-2橫空出世之后,強悍的效果讓不少人的震驚,無需針對性訓練就能橫掃各種特定領域的語言建模任務,還具備閱讀理解、問答、生成文章摘要、翻譯等等能力。
于是也引起了大家研究GPT-2的熱潮,將GPT-2帶到了各種各樣的場景下。
比如,有人給GPT-2加上“人類偏好”補丁,它說的話就越來越有人情味了。也有人用它做出了程序員沸騰的項目:殺手級AI補代碼工具,支持23種語言及5種主流編輯器。
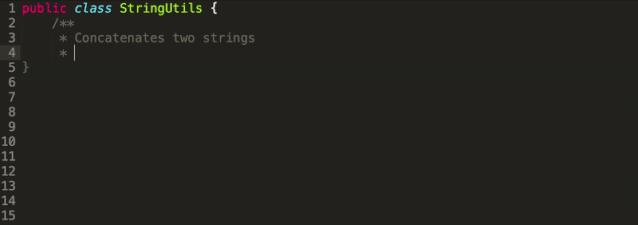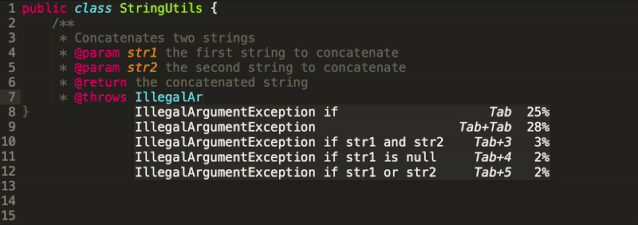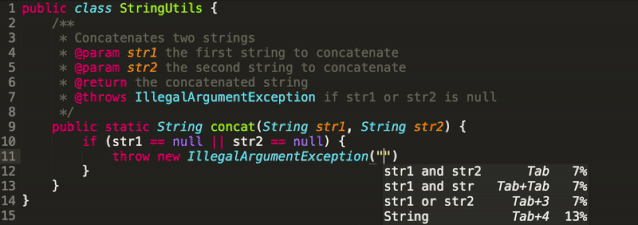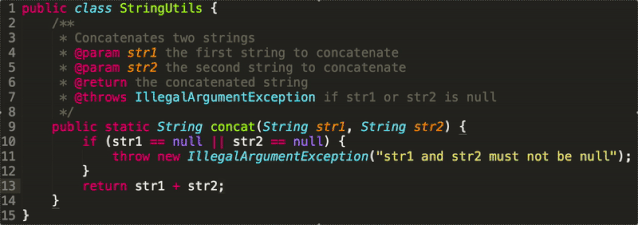
還有中文版GPT-2,可以寫詩,新聞,小說、劇本,或是訓練通用語言模型。
GPT-2 Chinese項目傳送門:
https://github.com/Morizeyao/GPT2-Chinese
正如OpenAI所說的,以及GPT-2所展現出來的能力,它的潛力遠遠不僅于此。
它還能夠用到更多的場景中。
不知道你有沒有大膽的想法?