













谷歌新模型刷新ImageNet紀錄,第一作者是上海交大畢業生
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
谷歌的EfficientNet進化之后,又刷新了ImageNet紀錄。
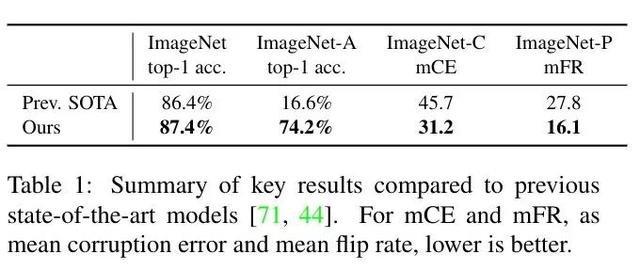
這個叫Noisy Student的新模型,將ImageNet圖像分類的top-1準確率提高到了87.4%,比此前最好的FixResNetXt-101 32×48d高出了1個百分點。
更令人驚嘆的是,在ResNeXt-101 32×48d只達到了16.6%top-1準確率的ImageNet-A測試集上,Noisy Student一舉將準確率提高到了74.2%。
新模型來自谷歌大腦首席科學家Quoc V. Le的團隊,而論文第一作者,則是畢業于上海交大ACM班的謝其哲,目前正在CMU攻讀博士,是谷歌大腦的學生研究員。
實現方法
提升如此明顯,但方法卻并不復雜。Noisy Student是站在了EfficientNet這位“名師”的肩膀上。
第一步,是用ImageNet中帶標簽的圖像訓練EfficientNet。
EfficientNet是谷歌開源的縮放模型,基于AutoML開發, 初登場就刷新了ImageNet的紀錄,準確度為84.4%(top-1)和97.1%(top-5),并且模型更小更快,效率提升達10倍之多。
對于這一模型,量子位做過詳細的解讀:https://mp.weixin.qq.com/s/DCRpBUJE98ckZnrouuVo6Q
第二步,在一個更大規模的數據集上,用EfficientNet給無標簽圖片打上偽標簽。
這一步中,研究人員選擇的是谷歌的JFT數據集。這一數據集擁有300M圖片,是ImageNet的300倍。
然后,將有標簽的圖像和被打上偽標簽的圖像組合起來,訓練一個更大的學生模型。
新的學生模型又會成為新的老師,迭代這一過程。
在生成偽標簽的過程中,教師模型不會被噪聲干擾,以便提高偽標簽的置信度。
但學生模型在訓練的過程中,會面臨來自隨機深度、dropout和RandAugment帶來的噪聲干擾。這就迫使學生模型不得不從偽標簽中進行學習。
在訓練的過程中,EfficientNet也會不斷更新。其中,最大的模型EfficientNet-L2需要在2048核的Cloud TPU v3 Pod上訓練3.5天。
性能表現
開頭已經提到,這個新的Noisy Student模型再一次刷新了ImageNet的紀錄,現在來看看它的具體戰績:
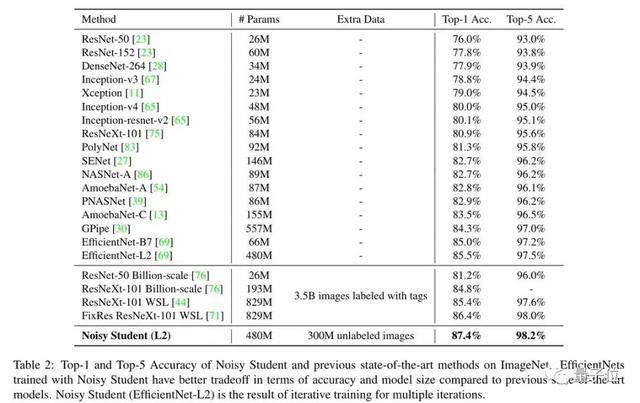
在top-1準確率上,EfficientNet和Noisy Student的組合將最佳成績提高了1個百分點,并且模型的參數規模遠小于Facebook的FixResNetXt-101 32×48d。
而在更加嚴格測試集上,Noisy Student的進步更為顯著。
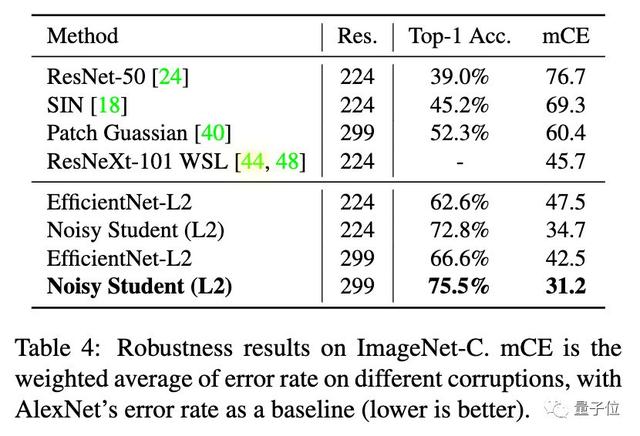
ImageNet-A測試集包含7500個自然對抗樣本,會導致SOTA模型的準確率大大下降。比如來自Facebook的知名選手ResNeXt-101 32×48d,就只能達到16.6%的top-1準確率。
在這個基準當中,Noisy Student一舉將top-1準確率從16.6%提高到了74.2%。
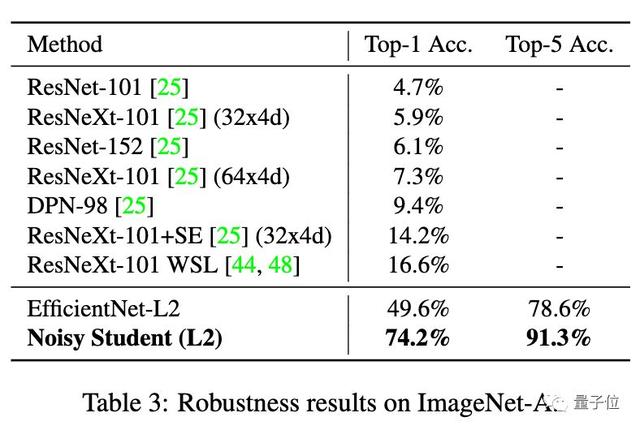
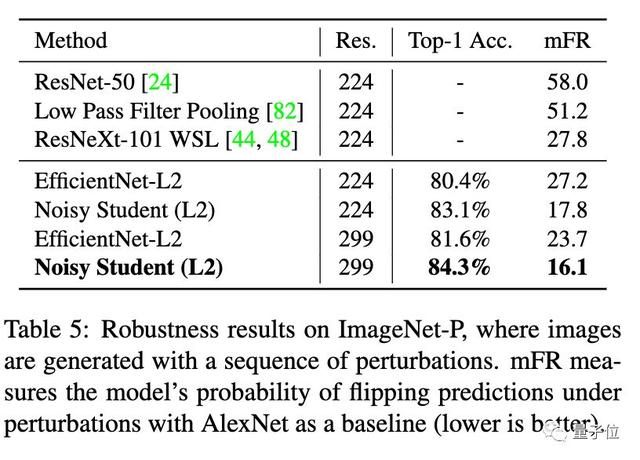
Image-C和Image-P測試集則包含了模糊、霧化、旋轉和縮放過的圖像。換句話說,測試圖像完全不同于模型的訓練數據。
在ImageNet-C上,Noisy Student將平均錯誤率從45.7降到了31.2。
在ImageNet-P上,Noisy Student將平均翻轉率從27.8降到了16.2。
也就是說,這個新模型不僅準確率又進一步,在魯棒性上,更是實現了驚人的進步。
根據論文作者介紹,模型代碼將盡快釋出,不妨先mark一下~
傳送門
論文地址:
https://arxiv.org/abs/1911.04252












