過(guò)半作者是華人!Google Research圖像表征模型ALIGN霸榜ImageNet
神經(jīng)網(wǎng)絡(luò)實(shí)際上就是在學(xué)習(xí)一種表示,在CV領(lǐng)域,良好的視覺(jué)和視覺(jué)語(yǔ)言(vision and vision-language)表征對(duì)于解決計(jì)算機(jī)視覺(jué)問(wèn)題(圖像檢索、圖像分類、視頻理解)至關(guān)重要,并且可以幫助人們解決日常生活中的難題。
例如,一個(gè)好的視覺(jué)語(yǔ)言匹配模型可以幫助用戶通過(guò)文本描述或圖像輸入找到最相關(guān)的圖像,還可以幫助像 Google Lens 這樣的設(shè)備找到更細(xì)粒度的圖像信息。
為了學(xué)習(xí)這樣的表示,當(dāng)前最先進(jìn)的視覺(jué)和視覺(jué)語(yǔ)言模型嚴(yán)重依賴于需要專家知識(shí)和廣泛標(biāo)簽的訓(xùn)練數(shù)據(jù)集。
對(duì)于視覺(jué)相關(guān)的應(yīng)用場(chǎng)景來(lái)說(shuō),視覺(jué)表示主要是在具有顯式類標(biāo)簽的大規(guī)模數(shù)據(jù)集上學(xué)習(xí)的,如 ImageNet、 OpenImages 和 JFT-300M等。
對(duì)于視覺(jué)語(yǔ)言的應(yīng)用來(lái)說(shuō),常用的預(yù)訓(xùn)練數(shù)據(jù)集,如Conceptual Captions和Visual Genome Dense Captions,都需要大量的數(shù)據(jù)收集和清理工作,這限制了數(shù)據(jù)集的大小,從而阻礙了訓(xùn)練模型的規(guī)模。
相比之下,自然語(yǔ)言處理的模型在 GLUE 和 SuperGLUE 基準(zhǔn)測(cè)試中,他們達(dá)到sota性能是通過(guò)對(duì)原始文本進(jìn)行大規(guī)模的預(yù)訓(xùn)練而不使用人工標(biāo)簽。
在 ICML 2021會(huì)議上,Google Research發(fā)表了Scaling up visual and vision-language representation learning with noisy text supervision一文,建議利用公開(kāi)的圖像替代文本數(shù)據(jù)(如果圖像未能在用戶屏幕上顯示,則在網(wǎng)頁(yè)上顯示替代圖像的書面文本)來(lái)彌補(bǔ)這一差距,以訓(xùn)練更大、最先進(jìn)的視覺(jué)和視覺(jué)-語(yǔ)言模型。

為了達(dá)到這個(gè)目的,我們利用了一個(gè)超過(guò)10億個(gè)圖像和文本對(duì)的噪聲數(shù)據(jù)集,在概念標(biāo)題數(shù)據(jù)集中沒(méi)有昂貴的過(guò)濾或后處理步驟就獲得了這個(gè)數(shù)據(jù)集。實(shí)驗(yàn)結(jié)果表明,我們的語(yǔ)料庫(kù)規(guī)模可以彌補(bǔ)噪聲數(shù)據(jù)的不足,從而實(shí)現(xiàn)了 SotA 表示,并且在轉(zhuǎn)換到 ImageNet 和 VTAB 等分類任務(wù)時(shí)表現(xiàn)出了很好的性能。對(duì)齊的視覺(jué)和語(yǔ)言表示還在 Flickr30K 和 MS-COCO 基準(zhǔn)上設(shè)置新的 SotA 結(jié)果,即使與更復(fù)雜的交叉關(guān)注模型相比也是如此,并支持零鏡頭圖像分類和復(fù)雜文本和文本 + 圖像查詢的交叉模式搜索。
圖文數(shù)據(jù)集中的 alt-text 通常是關(guān)于圖像的描述,但數(shù)據(jù)集可能包括噪音,例如一些描述文本可能部分或全部與其配對(duì)圖像無(wú)關(guān)。

例如第二張圖中就包括部分與圖像無(wú)關(guān)的描述,如日期、縮略圖等等。
Google的研究工作主要遵循構(gòu)建Conceptual Captions數(shù)據(jù)集的方法來(lái)獲得原始的英語(yǔ)描述文本數(shù)據(jù),即圖像和alt-text的pairs。
雖然Conceptual Captions數(shù)據(jù)集被大量的過(guò)濾和后處理清理過(guò)了,但是論文中的工作通過(guò)放寬數(shù)據(jù)清洗的措施來(lái)擴(kuò)大數(shù)據(jù)集,這種方法來(lái)擴(kuò)展視覺(jué)和視覺(jué)語(yǔ)言表征學(xué)習(xí)。
最后獲得了一個(gè)更大但噪音也更大的數(shù)據(jù)集,共包含 18億個(gè) 圖像-文本對(duì)。
ALIGN: A Large-scale ImaGe and Noisy-Text Embedding
為了便于建立更大的模型,模型框架采用了一個(gè)簡(jiǎn)單的雙編碼器結(jié)構(gòu)用來(lái)學(xué)習(xí)圖像和文本對(duì)的視覺(jué)和語(yǔ)言表示的align表示。
圖像和文本編碼器是通過(guò)對(duì)比學(xué)習(xí)來(lái)訓(xùn)練,即歸一化的softmax。
這種對(duì)比損失將匹配的圖像-文本對(duì)的embedding盡可能貼近,同時(shí)將那些不匹配的圖像-文本對(duì)(在同一batch中)盡可能分開(kāi)。
大規(guī)模數(shù)據(jù)集使我們能夠訓(xùn)練擁有更多參數(shù)的模型,甚至可以從零開(kāi)始訓(xùn)練和EffecientNet-L2和BERT-large那么大的模型。學(xué)到的視覺(jué)表征可以用于下游的視覺(jué)和視覺(jué)語(yǔ)言任務(wù)。
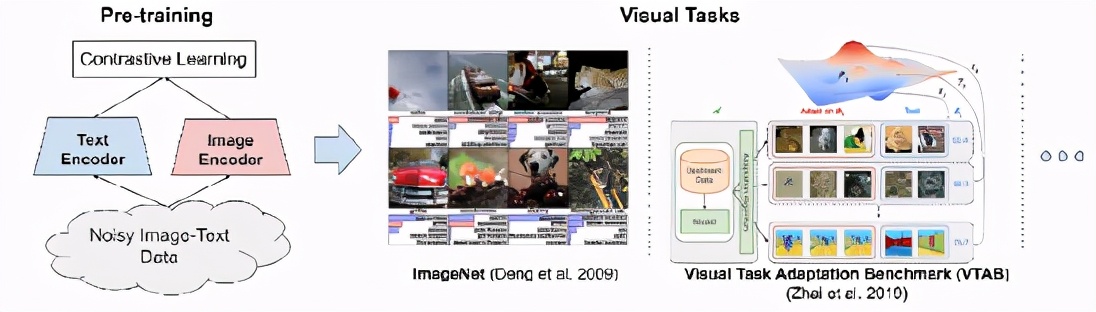
所得到的表示可以用于純視覺(jué)或視覺(jué)語(yǔ)言任務(wù)上的遷移學(xué)習(xí),無(wú)需任何微調(diào),ALIGN 就能夠跨模態(tài)搜索圖像到文本、文本到圖像,甚至聯(lián)合搜索圖像 + 文本的query。

上述例子就展示了ALIGN的這種能力。
Evaluating Retrieval and Representation
評(píng)估檢索和表示學(xué)習(xí)的時(shí)候, ALIGN 模型與 BERT-Large 和 EfficientNet-L2共同作為文本和圖像編碼器,能夠在多個(gè)圖像文本檢索任務(wù)(Flickr30K 和 MS-COCO) ZeroShot任務(wù)和微調(diào)中都取得了sota性能。
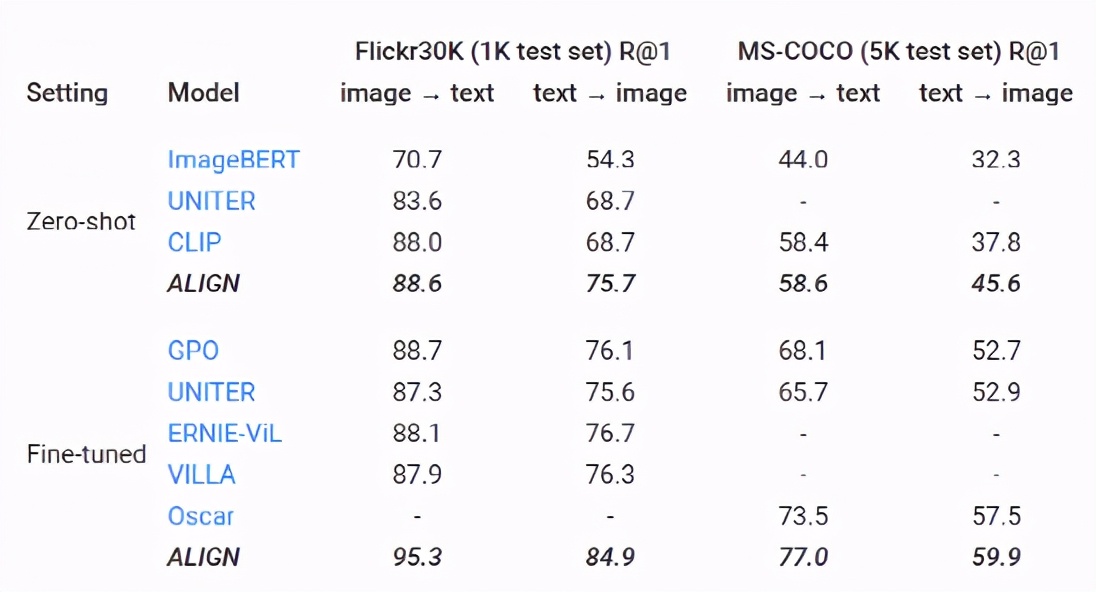
ALIGN 也是一個(gè)強(qiáng)大的圖像表示模型。在固定住特征以后,ALIGN 略優(yōu)于 CLIP,并在 ImageNet 上獲得85.5% 的 SotA 結(jié)果。通過(guò)微調(diào),ALIGN 比大多數(shù)通用模型(如 BiT 和 ViT)獲得了更高的準(zhǔn)確性,只比 Meta Pseudo Labels 差,但后者需要 ImageNet 訓(xùn)練和大規(guī)模未標(biāo)記數(shù)據(jù)之間進(jìn)行更深入的交互。

在Zero-Shot圖像分類上,圖像分類問(wèn)題將每個(gè)類別視為獨(dú)立的 id,人們必須通過(guò)每個(gè)類別至少拍攝幾張標(biāo)記數(shù)據(jù)來(lái)訓(xùn)練分類層次。但類名實(shí)際上也是自然語(yǔ)言短語(yǔ),因此可以很自然而然地?cái)U(kuò)展 ALIGN 圖像分類的圖文檢索能力,而不需要任何訓(xùn)練數(shù)據(jù)。
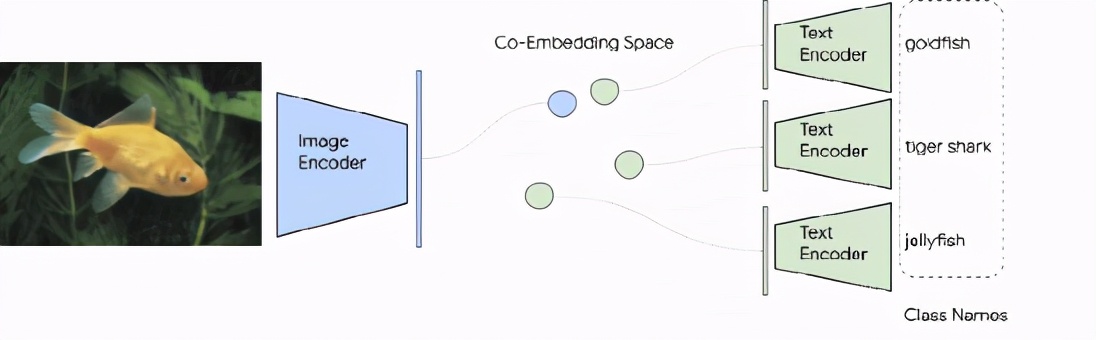
在 ImageNet 驗(yàn)證數(shù)據(jù)集上,ALIGN 實(shí)現(xiàn)了76.4% 的 top-1 Zero-shot 準(zhǔn)確率,并且在不同的 ImageNet 變體中表現(xiàn)出很強(qiáng)的魯棒性,這與同時(shí)期的工作 CLIP 很像,都使用了文本提示來(lái)訓(xùn)練。

為了能夠說(shuō)明圖像檢索的實(shí)際效果,論文中還構(gòu)建了一個(gè)簡(jiǎn)單的圖像檢索系統(tǒng),該系統(tǒng)使用 ALIGN 訓(xùn)練的embedding,并展示了一億6000萬(wàn)張圖像池中少數(shù)文本查詢的top1個(gè)文本到圖像的檢索結(jié)果。
ALIGN 可以檢索給出場(chǎng)景詳細(xì)描述的精確圖像,或者細(xì)粒度或?qū)嵗?jí)的概念,如地標(biāo)和藝術(shù)品。
這些示例表明,ALIGN 模型可以使圖像和文本具有相似的語(yǔ)義,并且 ALIGN 可以概括為新的復(fù)雜概念。

多模態(tài)(圖像 + 文本)圖像搜索查詢單詞向量的一個(gè)令人驚訝的特性是,單詞類比通常可以用向量算法解決。一個(gè)常見(jiàn)的例子,“ king-man + woman = queen”。圖像和文本嵌入之間的這種線性關(guān)系也出現(xiàn)在 ALIGN 中。
具體來(lái)說(shuō),給定一個(gè)查詢圖像和一個(gè)文本字符串,將它們的 ALIGN embedding相加到一起,并使用余弦距離檢索相關(guān)圖像。

這些例子不僅說(shuō)明了 ALIGN 嵌入跨視覺(jué)域和語(yǔ)言域的組合性,而且表明了使用多模態(tài)查詢進(jìn)行搜索的可行性。例如,人們現(xiàn)在可以尋找“澳大利亞”或“馬達(dá)加斯加”大熊貓的等價(jià)物,或者把一雙黑鞋變成看起來(lái)一模一樣的米色鞋子。此外,還可以通過(guò)在嵌入空間中執(zhí)行減法來(lái)刪除場(chǎng)景中的對(duì)象/屬性。
在社會(huì)影響方面,雖然這項(xiàng)工作從方法論的角度來(lái)看,以簡(jiǎn)單的數(shù)據(jù)收集方法顯示了令人滿意的結(jié)果,但在實(shí)踐中負(fù)責(zé)任地使用該模型之前,還需要對(duì)數(shù)據(jù)和由此產(chǎn)生的模型進(jìn)行進(jìn)一步分析。例如,應(yīng)當(dāng)考慮是否有可能利用備選案文中的有害文本數(shù)據(jù)來(lái)加強(qiáng)這種危害。關(guān)于公平性,可能需要努力平衡數(shù)據(jù),以防止從網(wǎng)絡(luò)數(shù)據(jù)加強(qiáng)定型觀念。應(yīng)該對(duì)敏感的宗教或文化物品進(jìn)行額外的測(cè)試和訓(xùn)練,以了解并減輕可能貼錯(cuò)標(biāo)簽的數(shù)據(jù)帶來(lái)的影響。
還應(yīng)該進(jìn)一步分析,以確保人類的人口分布和相關(guān)的文化物品,如衣服、食物和藝術(shù)品,不會(huì)造成曲解的模型性能。如果這些模型將在生產(chǎn)環(huán)境中使用,則需要進(jìn)行分析和平衡。
綜上所述,Google Research提出了一種利用大規(guī)模圖文數(shù)據(jù)進(jìn)行視覺(jué)和視覺(jué)語(yǔ)言表征學(xué)習(xí)的簡(jiǎn)單方法,模型 ALIGN 能夠進(jìn)行跨模態(tài)檢索,并且明顯優(yōu)于 SotA 模型。在純視覺(jué)的下游任務(wù)中,ALIGN 也可以與使用大規(guī)模標(biāo)記數(shù)據(jù)進(jìn)行訓(xùn)練的 SotA 模型相比,或者優(yōu)于 SotA 模型。
本文的一二作者分別是Chao Jia和Yinfei Yang兩位華人,而他們分別的研究方向分別為CV和NLP,可見(jiàn) 神經(jīng)網(wǎng)絡(luò)讓NLP和CV的界限也更加模糊了,萬(wàn)物皆可embedding。