擊敗剩下的0.02%人類選手
今年10月30日
DeepMind在《自然》雜志上
發表的一篇論文
仿佛又一次把人們的視線
拉回了兩年前的那場
“世紀大戰”之中
不過,這回的主角不是
“阿爾法狗”(AlphaGo)
而是AlphaStar
這位《星際爭霸2》玩家
在歐洲服務器擊敗了
99.8%人類選手
有同學聽后不以為然
“也沒有掃遍天下無敵手嘛。”
然而事實是
一局典型《星際爭霸》游戲的
搜索空間大約是一盤典型
圍棋棋局的101799640倍
而要擊敗剩下的0.02%人類選手
也只是個時間問題
從深藍到AlphaGo
再到AlphaStar
過去10年,人工智能在機器視覺、
深度學習、自然語言處理
等領域取得了重大突破
而在這條道路上
計算力是重要的推動力
OpenAI在2018年一份研究報告顯示:2012年起,AI消耗的計算力平均每3.43個月增長一倍,過去6年時間內已經增長30萬倍。GPU計算是當下AI深度學習訓練和推理計算的首選架構,FPGA與ASIC亦在積蓄力量。
戴爾科技集團持續投入到AI計算解決方案研究,并將我們的研究成果、效能測試、技術白皮書,分享給用戶及TensorFlow、Caffe、MXNet等主流開源框架社區。戴爾易安信在DSS8440、C4140、R740、R740xd、R940xa、R840、R7425、T640、XR2等多款服務器上,提供超過50種AI GPU加速配置方案支持,總有一款可以滿足您的需求。
全方位的AI GPU加速配置方案
總有一款可以滿足您
DSS8440
DSS8440是戴爾易安信設計的一款動態機器學習加速平臺,4U機箱可以支持最多10張Nvidia當前性能最高的V100加速卡或者8張戴爾投資AI芯片企業GraphcoreIPU ASIC加速卡,適合于各種AI計算環境下深度學習模型訓練。DSS8440提供更強的環境適應能力,支持在35℃環境下205W CPU以及GPU加速器。

C4140是戴爾易安信為AI計算精心打造的另外一款智能計算神器。C4140機箱只有1U,卻可以在有限的空間內支持4張最高性能的雙寬GPU加速卡、本地NVMe SSD硬盤以及100Gb低延遲網卡,為用戶提供極佳的數據中心空間GPU計算密度。

R940xa
當前很多復雜的AI應用場景,往往使用多種算法的集成學習,以達到更好的模型精度,解決小數據樣本下的機器學習,比如工業產品外觀缺陷檢測。而不同算法可能會選擇不同的計算介質,比如深度學習選擇GPU,經典機器學習使用CPU。此時,戴爾易安信R940xa四路計算加速服務器,可以提供CPU與GPU 1:1的計算配比,幫助用戶應對復雜集成學習環境下模型訓練加速。

R740
同時,隨著AI產業化不斷深入,推理計算需求增速明顯。戴爾易安信R740服務器也在AI推理計算場景中廣泛采用,2U機箱可以支持8張T4或P4 GPU。R740提供多矢量散熱技術,可針對不同GPU卡運行工作負載智能調節風扇轉速。

此外,隨著AI計算朝向邊緣端進展,很多場景下如工業生產線、移動通信基站、變電站等,對散熱、防塵等環境參數要求更加苛刻。而戴爾易安信XR2服務器搭載NvidiaT4,采用工業加固型服務器設計,提供臟亂、多塵環境下的過濾擋板,機箱深度僅為20英寸,復合嚴格的海事和軍用標準,可以適應復雜嚴苛環境下AI邊緣計算需求。

戴爾易安信聯合驅動科技
為用戶構建數據中心級AI資源池
IT軟件及硬件,一文一武,相得益彰。好的硬件設施,也需要好的資源管理與調度軟件,以實現AI計算資源的按需分配和隨需擴展。戴爾易安信聯合AI計算平臺合作伙伴趨動科技,基于獵戶座AI軟件實現GPU虛擬化,為用戶構建數據中心級AI資源池,應用無需修改即可透明共享和使用數據中心內任何服務器上的AI加速器。
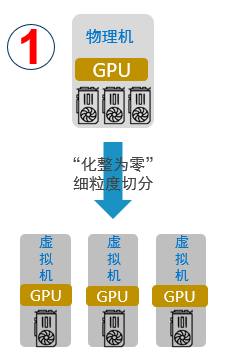
“化整為零”
支持將一塊物理GPU細粒度分割為多塊虛擬GPU,分配給多個虛擬機或容器同時使用,實現GPU資源的高效共享,提高AI計算資源利用率。有別于傳統GPU虛擬化只切割顯存,CUDA核心只能時分復用方式,獵戶座AI計算平臺可以實現虛擬GPU顯存和算力的獨立配置和限制。顯存和算力,既支持顯存和CUDA計算核心的等比例分配,也支持非等比例分配,從而提高資源利用率,降低成本。
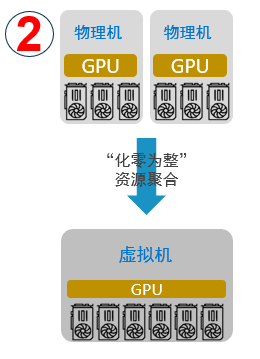
“化零為整”
支持將單臺以及多臺服務器的GPU資源提供給一個虛擬機或容器使用,AI應用無需修改代碼。用戶可以將多臺物理服務器計算資源聚合后提供給單一應用使用,為用戶的AI應用提供數據中心級超級算力,同時對應用透明。
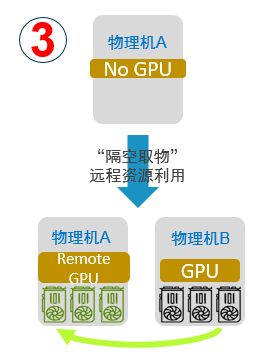
“隔空取物”
支持將虛擬機或容器運行在一臺沒有物理GPU的服務器上,透明地使用另外一臺服務器上的GPU資源,而無需修改AI應用代碼。借助這項功能,用戶可以構建數據中心級GPU資源池,應用可以無障礙地部署到數據中心內的任意服務器,并能夠透明地使用任意服務器之上的GPU資源。
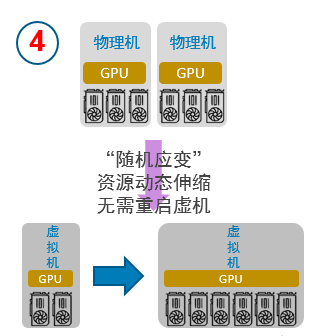
“隨需應變”
支持用戶在虛擬機或者容器的生命周期內,動態分配和釋放GPU計算資源,實現真正的GPU資源動態伸縮,極大提升了GPU資源調度的靈活度。
獵戶座AI計算平臺,可以在極少性能損耗下,實現GPU計算資源虛擬化,按需分配,靈活擴展和應用透明。
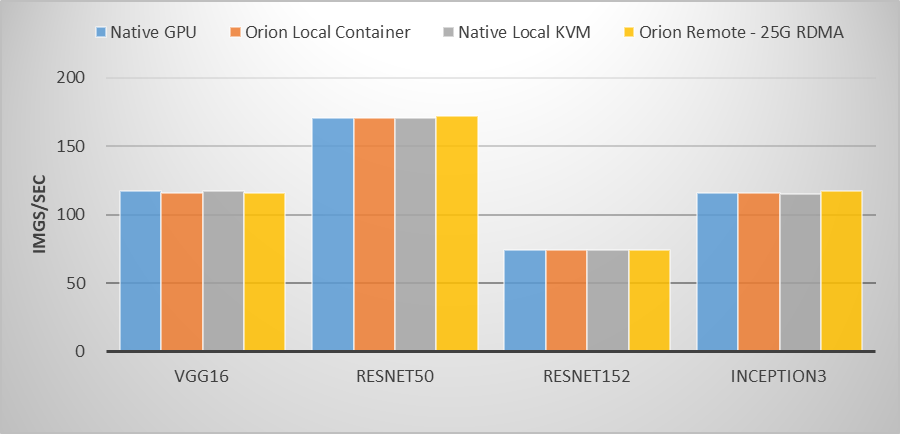
在之前進行的一項基于Nvidia Tesla P40的測試中,用例運行在物理GPU、虛擬GPU容器環境、虛擬GPUKVM虛擬機環境,以及通過25Gb ROCE網卡使用遠程虛擬GPU資源,運行VGG16、ResNet50、ResNet152、Inception3主流圖像分類模型訓練,虛擬GPU與物理GPU性能差距幾乎可以忽略不計。
通過適用于不同場景、不同AI應用負載的AI加速服務器硬件,以及提供創新AI虛擬化技術的獵戶座軟件平臺,我們為數據科學家提供一套高效經濟的AI計算平臺。未來的AI計算平臺,將如同我們兒時手中的魔方,隨著數據科學家的需要,快速變換出應用所需的AI計算資源,為拓展人工智能邊界提供有利的計算利器。