大數據與傳統數據的區別,來認識下吧(干貨)
大數據與傳統的數據技術的差別:
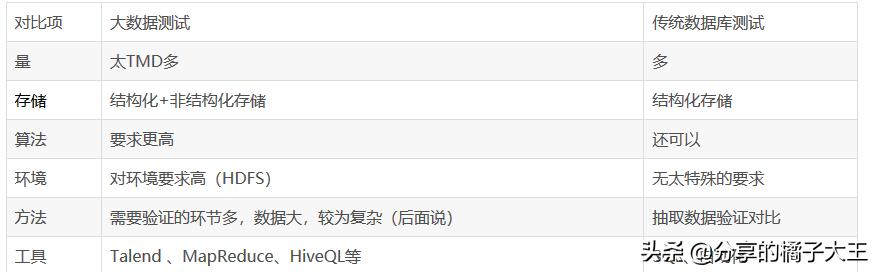
1、數據規模大:傳統數據技術主要是利用現有存在關系性數據庫中的數據,對這些數據進行分析、處理,找到一些關聯,并利用數據關聯性創造價值。這些數據的規模相對較小,可以利用數據庫的分析工具處理。而大數據的數據量非常大,不可能利用數據庫分析工具分析。
2、非結構化數據:傳統數據主要在關系性數據庫中分析,而大數據可以處理圖像、聲音、文件等非結構化數據。
3、處理方式不同:因為數據規模大、非結構化數據這兩方面因素,導致大數據在分析時不能取全部數據做分析。大數據分析時如何選取數據?這就需要根據一些標簽來抽取數據。所以大數據處理過程中,比傳統數據增加了一個過程Stream。就是在寫入數據的時候,在數據上打一個標簽,之后在利用大數據的時候,根據標簽抽取數據。這個過程就類似于尋找圖書:如果你在你個人書柜里,尋找一本書是很容易的,所以你買了書,可以直接放到書柜上,不用做任何處理;而如果圖書館買了書,如果不做任何處理的話,你是很難找到一本書的,所以圖書館在新書入庫的時候,首先會對每本書打上標簽,而這個打標簽的過程,就是類似于Stream的工作。
大數據與傳統數據相比的主要特點可以概括為:數據量“大”、數據類型“復雜”、數據價值“無限”。
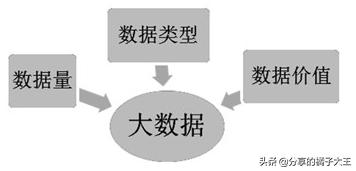
數據量大十分好理解,以前我們存儲數據使用的單位是 KB,一個Excel表格也就幾十到幾百KB,現在我們經常說到GB甚至是TB乃至PB的數據量級,它們的數量關系如下所示。
- 1:1MB=1024KB , 2:1GB=1024MB ,3:1TB=1024GB ,4:1PB=1024TB
更直觀一點,1KB相當于512個漢字,1MB就相當于六本紅樓夢的字數……而淘寶網在2015年3月每天大約能產生7TB的數據量,相當于4000萬本紅樓夢的數據量,而中國最大的圖書館中國國家圖書館的藏書量是3000萬冊。由此看來,我們的大數據著實是數據量巨大了。
大體上數據獲取的方式:
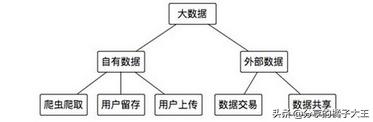
自有數據與外部數據是數據獲取的兩個主要渠道。在自有數據中,我們可以通過一些爬蟲軟件有目的的定向爬取,比如爬取一批用戶的微博關注數據,某汽車論壇的各型號汽車的報價等。用戶留存多是用戶使用了公司的產品或是業務,用戶在使用產品或是業務中會留下一系列行為數據,這個構成了我們的數據庫主體,通常的數據分析多基于用戶留存的數據。用戶上傳數據諸如持證自拍照、通訊錄、歷史通話詳單等需要用戶主動授權提供的數據,這類數據往往是業務運作中的關鍵數據。相較于自有數據獲取,外部數據的獲取方式簡單許多,絕大多數都是基于API接口的傳輸,也有少量的數據采用線下交易以表格或文件的形式線下傳輸。此類數據要么采用明碼標價一條數據多少錢,或是進行數據共享,交易雙方承諾數據共享,謀求共同發展。
大數據與傳統數據傳輸方式:
同樣的大數據與傳統數據的傳輸方式也截然不同。傳統數據要么以線下傳統文件的方式,要么以郵件或是第三方軟件進行傳輸,而隨著API接口的成熟和普及,API接口也隨著時代的發展逐漸標準化、統一化,一個程序員只用兩天的時間就能完成一個API接口開發,而API接口傳輸數據的效率更是能夠達到毫秒級。
在數據存儲方面,大數據的存儲環境相較于傳統數據的存儲已經躍升了好幾個數量級。
大數據與傳統數據顯著特點:
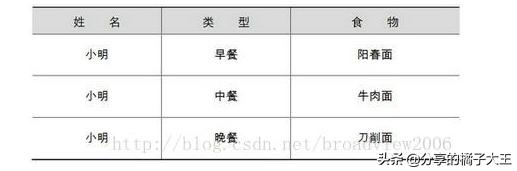
傳統數據的記錄方式:
大數據的記錄方式:
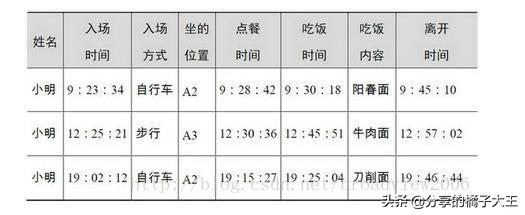
很明顯地看到,傳統數據和大數據記錄數據的最大區別是大數據不僅對對象進行了描述,
大數據與傳統數據的核心差異在于其價值的不可估量。傳統數據的價值體現在信息傳遞與表征,是對現象的描述與反饋,讓人通過數據去了解數據。而大數據是對現象發生過程的全記錄,通過數據不僅能夠了解對象,還能分析對象,掌握對象運作的規律,挖掘對象內部的結構與特點,甚至能了解對象自己都不知道的信息。
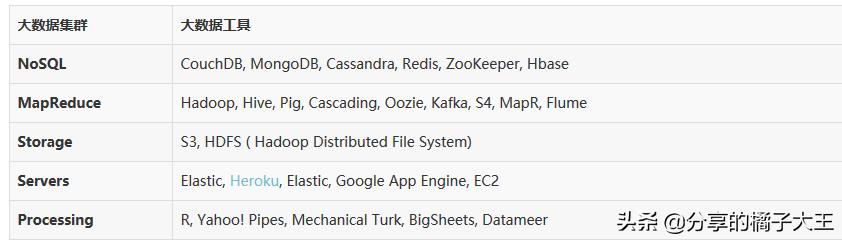
大數據場景使用的工具:
以上就是大數據與傳統數據的區別小知識介紹。