













在數據科學領域第一年學到的經驗和教訓
在Cortex Building Intelligence中從學習到將機器學習投入生產的五個要點
在過去的一年中,我從編寫Jupyter Notebook的簡單世界,轉到了開發機器學習管道,該管道向全天候的建筑工程師提供實時建議。 盡管我有改進的余地(我仍然犯了很多編碼和數據科學錯誤),但是我設法學到了一些關于數據科學的知識,我們將在本文中介紹這些知識。 希望通過下面的內容,您可以避免我在日常數據科學前沿學習到的許多錯誤。
- 數據科學主要是計算機科學
- 數據科學仍然是高度主觀的
- 人際關系和溝通技巧至關重要
- 使用標準工具,并且采用新技術的速度較慢
- 通過外部簡單性隱藏數據科學的內部復雜性
作者的注釋:這是從單一角度寫的,并不代表數據科學的整個領域。 請記住,這是來自從事建筑能源行業的端到端(已部署的機器學習系統的概念)數據科學家的工作,可為高效運營建筑物提供實時建議。 如果您有不同的經歷或想與我討論,請在"評論"部分等待您的回復。
數據科學主要是計算機科學
當被問到工作中最困難的部分時,考慮到我們所有的機器學習都像這樣,我堅決回答這不是機器學習:
- from sklearn import Model
- Model.fit(features, target)
- predictions = model.predict(testing_features)
取而代之的是,數據科學中最困難的部分是開發建模前后所發生的一切。 在具備以下條件之前:從數據庫加載數據,特征工程,數據驗證和數據處理管道(假設我們的工作在數據被攝取后開始)。 在我們需要驗證結果之后,將任務設置為按計劃自動運行,將結果寫回到我們的數據庫中,并發送webhooks來觸發其他服務。
這些外圍動作構成了機器學習的大部分工作,都需要扎實的計算機科學實踐。 這些與開發代碼有關的實踐中,有一些編寫短函數,每個短函數都做得很好,開發實現相關功能的類,正確的命名約定,對代碼和數據編寫單元測試,編寫易于閱讀,而不重復的代碼。 另外,還有其他計算機科學實踐可應用于代碼本身,例如版本控制,代碼審查,持續集成,代碼覆蓋和部署,這些實踐現在催生了一個完全獨立的機器學習操作(MLOps)領域。
盡管我設法完成了機械工程->數據科學家的過渡,但回想起來,進行工程->計算機科學->數據科學本來會更具有生產力。 第二種方法本來意味著我不必學習在數據科學課程中學習到的不良編碼實踐。 換句話說,我認為在扎實的計算機科學背景之上添加數據科學,要比先學習數據科學然后學習計算機科學要容易得多(但兩種方法都是可行的)。
計算機科學涉及一種完全不同的系統思維方式,即在編碼之前進行有計劃的規劃,緩慢地編寫代碼以及在編寫代碼后進行測試。 干凈的代碼與數十個半寫筆記本(我們所有人都擁有名為Untitled12.ipynb的筆記本)的數據科學通常隨心所欲的本質形成鮮明對比,并且強調獲得即時結果,而不是編寫相當無錯誤的代碼, 可以重復使用。
所有數據科學家都可以從計算機科學最佳編碼實踐課程中受益。 結構化腳本和程序包,編寫簡潔的代碼,測試和記錄代碼的能力,使從探索性數據科學到機器學習的過渡更加易于管理。 此外,他們灌輸了一種思維模式,從而導致易于理解的可重用代碼。 即使是通常會編寫數據科學腳本以分析論文數據的學術數據科學家也將受益于更好的實踐。 如果科學家編寫更簡潔的代碼并包含用于驗證輸入,輸出和功能行為的單元測試,則科學中的可再現性問題可能會得到改善。
數據科學中有很多主題需要學習,有時可能會感到不知所措。 但是,計算機科學不應被視為附加組件。 相反,對于希望看到其代碼可操作的數據科學家來說,它應該被視為基礎。 幸運的是,有很多資源,任何人都可以用來學習和應用這些實踐。
由于數據科學取決于人類的判斷力,所以我們需要意識到
數據科學仍然是高度主觀的
數據科學承諾使用數據而不是人類的判斷來做出最佳決策。 這是一個崇高的原因,但與當前現實相去甚遠,因為我們用來分析數據的數據和方法在很大程度上受到人類的影響。 甚至數據科學的所謂客觀領域也取決于人類行為。 正如Vicki Boykis在其電子報Normcore Tech中所說的那樣,神經網絡Neural Nets一直都是人。
典型的機器學習系統的每個步驟都會受到個人選擇的影響。 以下是其中一些決定:
- 收集數據:我們收集什么數據? 我們使用什么傳感器? 我們調查誰? 我們如何表達我們的問題?
- 特征工程:我們制作什么特征? 我們使用領域知識還是自動化特征工程? 我們如何填寫缺失的值? 什么意見應刪除?
- 建模:我們應該使用哪些超參數? 我們應該建立多復雜的模型?
- 驗證:什么是評估指標? 驗證程序是什么? 我們需要什么水平的性能?
- 部署:我們是否相信這些數字足以向客戶展示? 我們是否需要人工評估預測以進行健全性檢查?
不可避免地,通過這個過程,不同的人將得出不同的結論。 《許多分析師,一個數據集》一書中記錄了一個這樣的例子,該文章描述了數據科學家如何使用相同的數據集來得出相互矛盾的決策,因為他們采用了多種方法。 毫不夸張地說,您可以使用一個數據集來通過改變分析來證明一個論點及其對立面。 這說明您不應該對一項研究得出的任何結論抱有過多的信念,而應該(懷著懷疑的態度)著眼于薈萃分析(并閱讀《如何利用統計學撒謊》)。
此外,人為的偏見(無論是有意還是無意的)都會進入數據,從而影響機器學習模型。 如《數學毀滅性武器》一書中所示,將決策移交給機器并不能消除歧視,而是編譯了出現在現實世界數據中的現有偏見。 最終目標是用數據科學來誤導決策,這是崇高的,但是只要涉及人類,我們就不能盲目地依靠機器學習預測。
人際關系和溝通技巧至關重要
盡管看上去很明顯(在任何領域,溝通技能會是負面的嗎?),但我每天都在提醒我,需要與各個技術領域的人們進行有效的機器學習交流。 僅僅了解您的ML行話是不夠的; 您需要能夠與他們知道內幕的人見面,并僅告訴他們他們需要了解的細節。
(作為一個幽默的例子,我的工作對某些人來說是"計算機的東西",而對其他人則是半小時的關于機器學習細節的討論。)
至少在我們的情況下,機器學習決策不能代替人工選擇(即使更準確),因為建筑工程師可以使用我們的建議。 (自主建筑的運行可能比自動駕駛車輛更遠)。 僅建立模型,顯示模型的準確性,并將結果提供給希望立即實施預測的客戶是不夠的。 數據科學家仍然必須掌握復雜的社交互動藝術。 您可以產生最佳的機器學習模型,但是如果您不能說服人們使用它,那么它將不會有任何影響。
我工作中最普通的方面是通過內部和外部小組的寫作和演示來解釋方法,了解我們的客戶當前如何做出決策,并與領域專家交談以將其知識轉化為數據科學系統。 大學里沒有提到這些,我被告知數據科學家可以躲在完美的客觀數字后面。
使用標準工具,并且采用新技術的速度較慢
確保您的算法不包含任何錯誤的最佳方法是什么? 從sklearn導入模型,而不是自己編寫模型。 除非您進行前沿研究,否則幾乎沒有理由編寫自己的機器學習模型版本。 取而代之的是,使用來自廣泛使用且經過測試的庫中的函數(我稱之為標準工具)來完成任務。
在最近的一條推文中,我說過,最差的數據科學家編寫了自己的算法,而最優秀的科學家則從標準庫中導入了算法。 我當時是在開玩笑,但我堅持以下原則:使用經過測試的開源庫代碼幾乎總是比開發自己的代碼更有效。
使用標準工具的邏輯不僅適用于機器學習模型。 您可能要對數據集執行的所有操作均已在pandas中實現(假設您使用Python),因此請先在此處查找解決方案。 同樣,也有用于統計,繪圖,測試,調度,部署任務以及機器學習管道的大部分內容的標準庫。
我從擁有2個博士學位到接任我的職位, 曾渴望發明自己的數據結構,度量標準,算法,文件加載等的強烈要求(可能證明自己的學位合適)的數據科學家,這導致了一大堆沒人知道的混亂代碼。 我在工作的前六個月主要是用三個import語句替換了100行腳本,直到今天,我很自豪成為我們機器學習庫的一個貢獻者。
Via Negativa: addition by subtraction
此外,不要僅僅因為新的庫/技術/框架/數據庫,而切換到新庫/技術/框架/數據庫。 標準工具(例如SQL數據庫,用于機器學習的sklearn和用于數據操作的pandas)可以正常工作。 它們可能是無聊的,因為它們(相對)古老,但是它們也經過了測試和可靠。 剛開始時,作為早期采用者似乎很有趣,但是當您與錯誤和有限的文檔進行斗爭時,它很快就會變得筋疲力盡。
盡管新技術驅動了媒體周期,但它們通常對實際工作的人員和公司幾乎沒有影響,甚至沒有立即影響(當心工程媒體)。 我的年輕一代不敢相信我在說這話,但與那些尚未取得成果的令人興奮的新穎技術相比,我現在更喜歡乏味,成熟的技術。 在內部,我們的工程團隊對升級庫版本進行了長時間的辯論,并且,如果沒有明顯的好處或需求,那么我們就不會升級,因為有新版本發布。 向我們的機器學習代碼庫添加一個庫需要明確的需求,因為另一個庫意味著要管理的另一個依賴項。
壽命最長的公司是那些做事平凡而行動緩慢的公司(例如Caterpillar),而行動迅速而又做"酷"事情的初創公司往往會在幾年內消散。 最強大的機器學習系統將不會是使用尖端技術的系統,而是那些將使用久經考驗的數據科學標準工具。
通過外部簡單性隱藏數據科學的內部復雜性
計算機非常擅長處理大量數字。 人類幾乎無法處理幾個數字。 為了最有效地結合計算機和人類的能力,我們應該使用計算機來分析大型數據集,并僅將最關鍵的數據呈現給人類進行決策。 數百萬個數字輸入,盡可能少的數字輸出。 內部有復雜的模型,外部有可行的建議。
在過去的一年中,我發展了一種理論,即圖表中的數據點越多,數字越少(也許是7?),它的作用就越小。 人類只是沒有能力準確地分析復雜的定量圖。 熱圖很酷,但是有沒有人從具有1000個數據點的熱圖(與具有五個數字的條形圖相比)做出關鍵決定?
Cool, but what am I supposed to do with this information? (Source)
作為一個通常喜歡細讀數字并聽取機器學習模型細節的人,我很難適應大多數人不想要更多信息的想法。 客戶和做出決定的人們都渴望外賣,僅此而已。 更少的墨水意味著更好的圖表。 (如果需要制作圖表的幫助,請查閱定量信息的可視化顯示或數據可視化基礎知識)。
Dull? Probably. Informative? Absolutely.
外部簡單性的論點并不意味著僅使用線性模型。 數據科學可能涉及復雜的算法和高度技術性的操作。 對于非技術人員來說,只有數據科學的外部部分必須足夠簡單。 不過,請注意使模型如此復雜,以至于您甚至都不理解它。 為了降低精度而以無法解釋您的模型為代價,值得使用混合模型嗎? 可能不會。
為了用外部簡單性掩蓋內部復雜性,請使用有助于描述模型決策的工具。 SHAP值是一種有用的技術,您可以使用其他方法。 為了說明建筑物的最佳開始時間建議,我們對所有特征(包括工程特征)采用SHAP值,并將其組合為人類可理解的特征組,例如天氣和建筑物內部條件。 我們采用復雜的機器學習算法,使用SHAP值對其進行簡化以供我們理解,然后在向客戶展示產品之前進一步利用我們的知識對其進行精簡。
簡化定量信息的一種方法是準備僅以一個數字開頭的報告,然后根據需要添加其他數字(這也適用于圖形)。 這種累加方法無需從大量圖形開始并刪除它們,而是確保沒有無關緊要的統計數據進入演示和報告。 請記住,人不是計算機,您不應像他們那樣呈現結果。
+1 每個人都會感到冒名頂替綜合癥并犯錯; 這不會讓你退縮
最后,由于這是數據科學(及其他專業)中的重要問題,因此,這里值得鼓勵的一課是:不要讓冒名頂替綜合癥或錯誤使您失望。
每個人都會感覺到他們不屬于該職位,或者最終會因為無法勝任而最終被"發現",所以請不要為此煩惱。 取而代之的是,改變對形勢的看法:您不是唯一擁有這些想法的人,學習新事物與產生結果一樣重要,而且,如果您是相對較新的人,那么成為新手會有所裨益(例如尋找新方法) 解決問題)。 此外,很容易環顧四周并看到人們取得了巨大的成功,但是您看不到的是他們一路上遇到的所有失敗(一種生存偏見)。
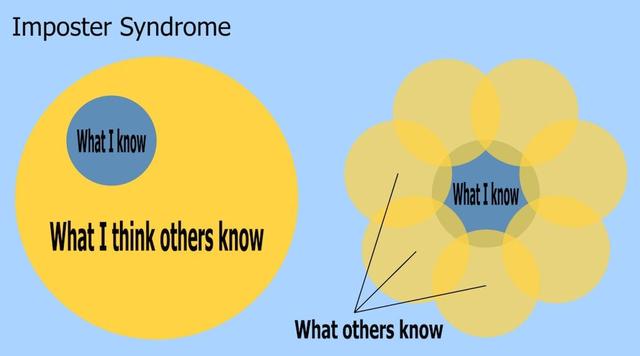
People have different areas of knowledge (Source)
即使是表現最好的人,也從初學者開始就犯了(并且繼續犯)自己的錯誤。 錯誤并不意味著您不應該是數據科學家或計算機程序員。 他們意味著您有機會學習如何做得更好。 在數據科學領域,我們需要更多的人,而且我擔心我們將數據科學家描繪成站在專業技能的巔峰,從而排除了技術人才。 這是一個神話,因為您只能通過在某個領域工作來獲得專業知識,而這并不是您進入職業生涯之前所擁有的東西。 事實是,數據科學是開放的,并且沒有進入該領域的"典型"途徑。 如果您由于背景或缺乏專業知識而不屬于自己,那么好消息就是那是一種扭曲; 數據科學不是只為少數精英保留的專業。
數據科學的主觀性是否意味著我們應該放棄所有關于真理的觀念? 我認為我們應該重新構想這個問題:我們不使用一個有缺陷的數據科學,而是尋找一個正確的答案,而是朝著更好的解決方案的方向發展。 畢竟,數據科學是科學的一個子領域,其目標是隨著時間的流逝減少錯誤。 同樣,研究問題的人員越多,并比較他們的工作,我們就越接近獲得更好的結果。 那20位科學家可能進行了20次不同的分析,但是如果他們隨后比較了他們的方法并共同努力,那么最終的成果將優于任何單個項目。
在實踐數據科學時,我們必須記住,就像任何領域一樣,不容置疑,數據科學也不是沒有缺陷。 實踐負責任的數據科學意味著以不確定的時間間隔呈現結果,尋找理由來反駁您的結論,將您的結果與其他類似工作進行比較,并且在呈現發現結果時要切合實際。
結論
在該領域工作了一年之后,我最初對數據科學的無限樂觀已被謹慎的熱情所取代。 機器學習可以很好地解決一小部分問題(比人類更好),但不能解決所有人為錯誤。 必須認識到該領域的局限性,以避免過度銷售數據科學,從而導致未兌現的承諾。 盡管如此,以一種現實的態度并牢記這些教訓,機器學習仍可以帶來令人印象深刻的結果。 最后,最好的機器學習系統應旨在通過允許我們更有效地完成工作來幫助人類,而不是取代人類。
即使在您解釋了計算機如何做出決定之后,該建議也可能會被忽略,因為人們并不完全理性。 當出現客觀上更好的選擇時,人們可能出于各種原因選擇另一種選擇:習慣,不信任,熟悉,錯誤信息。
考慮一下風景優美的路線選擇:有時候,人們似乎出于邏輯上的原因會沿著兩個地方走更長的路線。 為什么? 因為沿途風景更美。 天真的數據科學家可能只顯示模型建議的最短路線,但是,了解她的客戶的數據科學家會知道,他們希望在旅途中看到更多的州際公路。
同樣,可能不會使用最佳的機器學習預測,因為準確性不是唯一的考慮因素。 例如,我們預測了建筑工程師開始為其建筑物供暖的理想時間,但是許多工程師仍會更早地打開設備,因為他們不希望租戶感到不適。 這是不合理的(我們按時提出建議,以確保在租戶到達時建筑物將處于正確的溫度),但是,直到我們從決策過程中驅除人員之前,我們將不得不調整計算機系統而不是其他方式。
也許除了您的計算機科學課程外,還可以參加一些社會學課程來了解您的人類同胞(或閱讀行為經濟學書籍,例如兩位諾貝爾經濟學獎得主理查德·泰勒(Richard Thaler)的《行為不端》或丹尼爾·卡尼曼(Daniel Kahnemann)的《思考,快與慢》。













