單挑碾壓頂尖職業選手,騰訊公開王者榮耀AI最新細節
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
最新消息,騰訊又圍繞王者榮耀AI“絕悟”發表了新論文,已經被AI頂會AAAI 2020收錄。
這是繼今年8月份絕悟在5v5比賽中擊敗職業戰隊后,騰訊首次披露AI背后的技術細節。
騰訊研究人員表示,將AI執行動作時間限制在業余高手玩家相同的水平上(間隔為133ms),絕悟已經能夠單挑頂級職業選手,并在其擅長的英雄上實現碾壓,15場比賽中職業選手只贏了1場,并且最多堅持不到8分鐘。
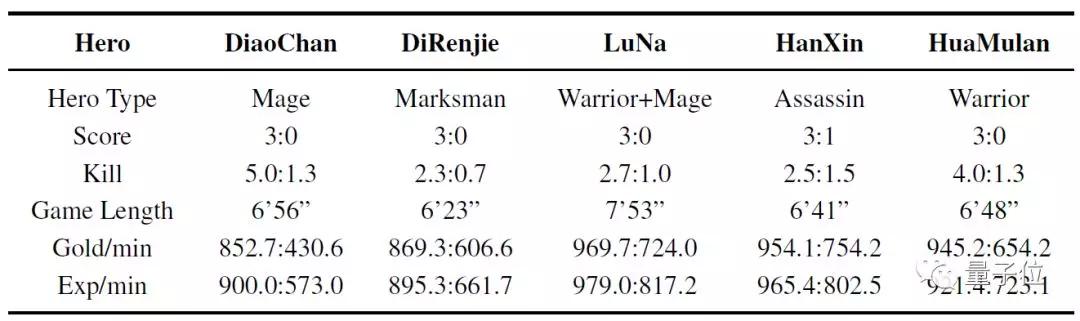
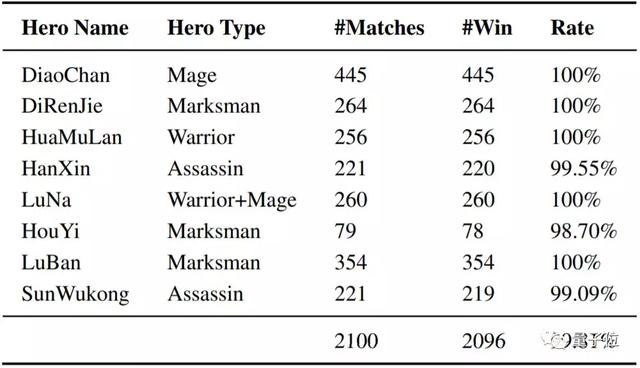
在今年8月份的公開測試中,這一王者榮耀1V1的AI與大量頂級業余玩家進行了2100場對戰。AI勝率達到99.81%。
在貂蟬(法師)、狄仁杰(射手)、花木蘭(上單/戰士)、露娜(打野/刺客)、魯班(射手)等英雄上,勝率都是100%。
如此AI是怎么訓練出來的?我們且看騰訊最新論文中披露的最新細節。
30小時達到王者水平,70小時比肩職業玩家
首先需要指明的是,騰訊的這篇新論文關注的是 1v1 游戲AI,并不是 5v5 游戲AI。
研究人員在論文中解釋稱,后者更注重所有智能體的團隊合作策略,而不是單個智能體的動作決策。
考慮到這一點,1v1游戲更適合用來研究游戲中的復雜動作決策問題,也能夠更加全面系統的研究游戲 AI 智能體的構建。
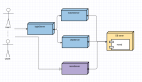
AI的整體架構一共分為4個模塊:強化學習學習器(RL Learner)、人工智能服務器(AI Server)、分發模塊(Dispatch Module)和記憶池(Memory Pool)。
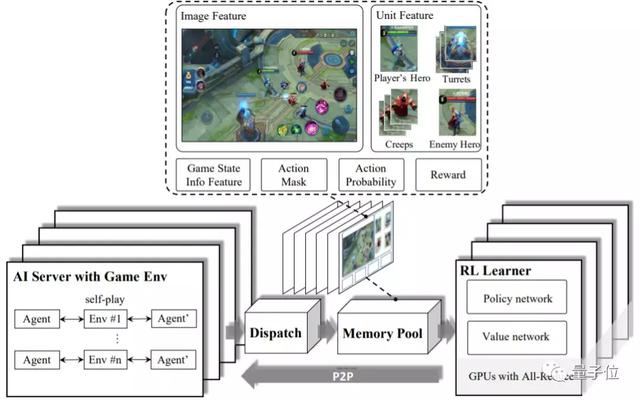
這是一種高可擴展低耦合的系統架構,可以用來構建數據并行化。主要考慮的是復雜智能體的動作決策問題可能引入高方差的隨機梯度,所以有必要采用較大的批大小以加快訓練速度。
其中,AI服務器實現的是 AI 模型與環境的交互方式。分發模塊是用于樣本收集、壓縮和傳輸的工作站。記憶池是數據存儲模塊,能為 RL 學習器提供訓練實例。
這些模塊是分離的,可靈活配置,從而讓研究者可將重心放在算法設計和環境邏輯上。這樣的系統設計也可用于其它的多智能體競爭問題。
在強化學習學習器中,他們還實現了一個 actor-critic 神經網絡,用于建模1v1 游戲中的動作依賴關系。
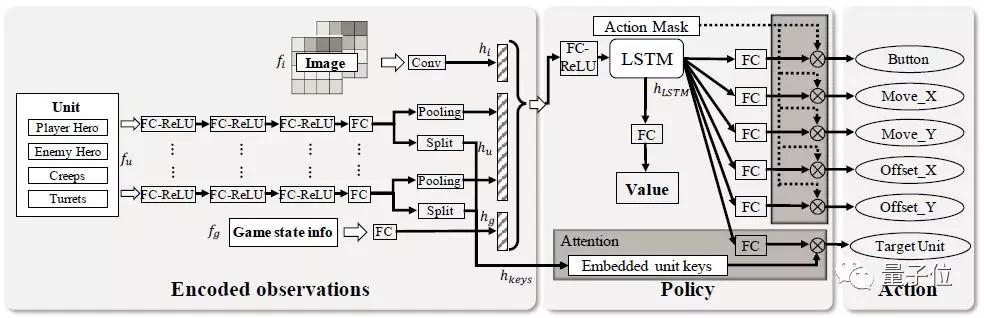
為了應對游戲中的多個場景決策,研究人員們還提出了一系列算法策略,來實現更高效率的訓練:
- 為了幫助AI在戰斗中選擇目標,引入目標注意力機制;
- 為了學習英雄的技能釋放組合,以便AI在序列決策中,快速輸出大量傷害,使用了LSTM;
- 用于構建多標簽近端策略優化(PPO)目標,采用動作依賴關系的解耦;
- 為了引導強化學習過程中的探索,開發了基于游戲知識的剪枝方法;
- 為了確保使用大和有偏差的數據批進行訓練時的收斂性,改進 PPO 算法提出dual-clip PPO,其示意圖如下所示:
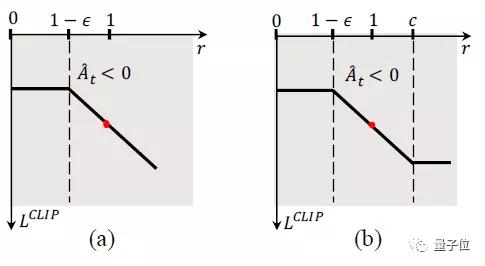
研究人員在論文中指出,基于這樣的方法訓練一個英雄,使用48個P40 GPU卡和18000個CPU 內核,訓練一天相當于人類打500年,訓練30個小時就能達到王者段位水平,70個小時比肩職業玩家,其表現要顯著優于多種baseline方法。
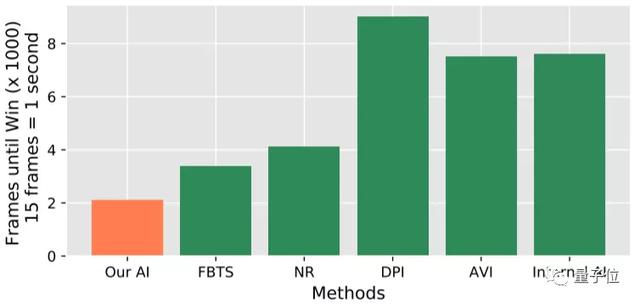
而且如前所述,在與人類選手交戰的測試中,獲得了非常亮眼的成績。
如果你想了解關于這一AI更多的細節,我們將論文鏈接放到了文末~
來自騰訊AI Lab和天美工作室,還在打造開放平臺

與2018年12月份發布的王者榮耀AI論文作者單位相比,這次多了“天美工作室”——王者榮耀的開發團隊。
除了研究,騰訊AI Lab與王者榮耀還將聯合推出“開悟”AI+游戲開放平臺。
王者榮耀會開放游戲數據、游戲核心集群(Game Core)和工具,騰訊AI Lab會開放強化學習、模仿學習的計算平臺和算力,邀請高校與研究機構共同推進相關AI研究,并通過平臺定期測評,來展示多智能體決策研究實力。
目前“開悟”平臺已啟動高校內測,預計在2020年5月全面開放高校測試,并且在測試環境上,支持1v1,5v5等多種模式。
騰訊透露,計劃在2020年12月舉辦首屆AI在王者榮耀應用的水平測試。