全球頂尖AI做物理,被人類按地摩擦?不懂推理大翻車,本科生碾壓
大模型,真的懂物理推理嗎?
就在剛剛,港大、密歇根大學、多倫多大學等機構的研究者用3000道物理題,給全球頂尖大模型來了一場大拷問。
結果,這些頂尖AI,毫無例外全部翻車了!

論文地址:https://arxiv.org/pdf/2505.15929
比如,GPT-4o、Claude3.7-Sonnet和GPT-o4-mini的準確率分別僅為32.5%、42.2%和 45.8%。這個準確率,直接被人類專家吊打,性能差距超過了29%。
最終,研究者們得出結論:當前的AI模型過度依賴記憶的學科知識、過度依賴數學公式、過度依賴膚淺的視覺模式匹配,絕非做到了真正的物理理解。
能做奧數的AI模型,做物理題有多強?
物理學是所有科學中最基礎、最全面的學科。
——理查德·費曼
當前最先進的模型在奧數問題上已經達到了與人類相當的水平。
尤其是最新的多模態模型,如GPT-4o、Claude-3.7-Sonnet等,通過結合視覺理解和推理能力,展現了很強的潛力。
然而,現有的基準測試未能捕捉到智能的一個關鍵維度:物理推理,即學科知識、符號推理與對現實世界約束的理解綜合起來的能力。
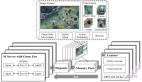
為了解決這些問題,來自港大、密歇根大學等機構的研究者推出了PHYX:首個評估模型在視覺場景中物理推理能力的大規模基準測試。
PHYX具有三大創新:
- 收集了3000個全新的問題,涉及真實的物理場景,需要結合視覺分析和因果推理來解答;
- 經過專家驗證的數據設計,涵蓋六個核心物理領域:熱力學、電磁學、力學、現代物理學、光學以及波動與聲學;并包含六種不同的物理推理類型:物理模型推理、空間關系推理、多公式推理、隱含條件推理、數值推理和預測推理;
- 采用嚴格統一的三步評估協議,考慮不同模型的指令遵循能力,確保推理能力的精確評估。每個場景都由物理學博士生進行嚴格驗證,以保證科學準確性,同時消除數據集偏差。

PhyX數據集的數據示例。該數據集包含3000個人工標注的物理問題,附帶視覺上下文
團隊對16個基礎模型的評估揭示了一個前所未有的能力差距:物理學本科生和研究生的最差表現組準確率為75.6%,而表現最好的大模型GPT-o4-mini僅為45.8%。
這一30個百分點的差距存在于所有的物理領域,尤其是現代物理學(人類86.7% vs. 模型40.6%)和波動與聲學(人類86.7% vs. 模型52.7%)最為明顯(圖 1)。

即便是最先進的模型在物理推理方面也表現得相當吃力。GPT-4o、Claude3.7-Sonnet和GPT-o4-mini 的準確率分別僅為 32.5%、42.2% 和 45.8%。
這暴露了當前多模態推理模型的三大關鍵局限:
- 過于依賴記憶性學科知識;
- 過度依賴數學公式;
- 停留在表層視覺模式匹配而非真正的物理理解。

不同模型在 MMMU 排行榜上的總體表現。每個類別中表現最佳的模型以粗體顯示,次優者以下劃線標注
物理題實測:全部翻車
來自六大核心物理領域的考題,AI模型們完成得怎么樣?
接下來,我們來看看具體實測。
為了對模型的考驗更加公平,研究者給它們提供的圖像具有高度的真實感,通常描繪的是具體的物理場景,而非風格化、抽象化的插圖。
這些圖都根植于合理的物理設定之中,為物理推理提供了關鍵背景,非常有助于讓AI模型將抽象的物理原理與現實世界的表現聯系起來。
以下這些圖片,分別是力學、電磁學、熱力學、波動/聲學、光學和現代物理六大類題目的圖像。






而這六大類,還包含不同的子領域。

力學
首先我們來看看,現在什么樣的力學物理題,大模型能做對。
一名消防員站在距離燃燒建筑物d的位置,將水龍帶噴出的水柱以與地面成θ_i角的方向噴向建筑,如圖所示。
問題:若水柱噴出的初速度為v_i,那么水柱擊中建筑物時的高度h是多少?

可以看到,GPT-4o將初始速度分解為水平分量和垂直分量,計算出來水流到達建筑物所需時間,然后計算出水珠在時間t時的垂直位移y,最終得出了水柱擊中建筑物的高度h。
結果正確。
但接下來這兩道經典的高中力學題,GPT-4o就翻車了。
將一根輕質、不可伸長的繩纏繞在一個實心圓柱體上。該圓柱質量為50千克,直徑為0.120米,通過無摩擦軸承繞一條固定的水平軸旋轉,如圖所示。用恒定的9.0牛的力拉動繩子的自由端,使其在拉出 2.0米的距離后帶動圓柱旋轉,且在過程中繩子不會打滑。圓柱最初處于靜止狀態。
問題:繩子的最終速度是多少?

在這道題中,GPT-4o分別計算了力F所做的功、圓柱的轉動動能、繩子線速度和圓柱角速度的關系,前四步都是對的。
然而,就在第五步計算系統的總動能時,它出現了錯誤,最終導致整個答案都錯了。
下面這道斜坡難題,GPT-4o依然沒做對。
將一個質量為12千克的箱子沿一條長2.5米、傾角為30°的斜坡向上滑動。一名工人(忽略摩擦)計算認為,他只需在坡底給予箱子一個初速度5.0 m/s,然后放手即可讓其滑上坡。但實際上,摩擦不能忽略:箱子只滑上了1.6米就停止,然后又滑回坡底。
問題:當箱子滑回到坡底時,它的速度是多少?

在解題過程中,GPT-4o正確寫出了能量守恒方程,然后計算摩擦力做的功這一步時除了錯,導致接下來的最終速度也解錯了。
電磁學
接著看一下電磁學。
第一道題目需要計算電路中因電阻產生的能量耗散速率。
GPT-4o表現不錯,它先確定了滑線運動產生的電動勢,再計算出電路中的電流,最后得出能量耗散速率,整個回答邏輯嚴密,步驟分明,成功得出正確結果。

第二道題目是關于電磁學中RL電路的時間常數計算。需要根據給定的電流變化情況,計算電路的時間常數并確定電感值。
看起來要更復雜一些。
不過,GPT-4o同樣表現得很出色,它一步步分析了電流變化的描述,提取出關鍵信息,通過已知條件計算出時間常數,并進一步推導出電感值,最終選出正確答案,過程清晰且準確。

不過接下來,GPT-4o就開始翻車了。
第一道題目是關于一個電路中電壓讀取的問題。需要計算開關閉合后0.115毫秒時電壓表讀取的電壓;第二道題目是關于電偶極子在電場中的力矩,需要找出力矩的大小;第三道題目涉及電場計算,需要計算在某個點c處電場的總和。
GPT-4o在第一道題目上的表現有些失誤。它嘗試一步步分析電路的組成和電感的作用,計算了電流隨時間的變化以及電壓,但由于對電路元件行為理解不夠準確,最終給出的電壓值偏離了正確答案,顯示出視覺推理上的問題。
第二道題目中,GPT-4o按部就班地分析了電偶極子的性質和電場角度,計算了力矩的大小,但由于對文本描述的誤解,導致結果與標準答案不符,暴露了文本推理的弱點。
第三道題,GPT-4o展示了不錯的分析能力,它詳細考慮了兩個電荷對點的貢獻,試圖將它們結合起來計算總電場,但由于知識上的不足,計算結果與實際答案有較大偏差。



熱力學
熱力學問題上,GPT-4o的表現也不穩定。
不過,第一題表現還不錯。
第一道題目是關于熱力學中氣體分子速度的計算。題目描述了一個被隔板分隔的絕熱箱子,里面裝有氣體,初始時氣體在一半的空間,溫度已知。隔板被打破后,氣體充滿整個箱子,計算這個自由膨脹過程中的熵變是多少。
GPT-4o先從圖中提取了每個分子的速度信息,逐步計算了每個分子的速度大小,然后求出所有分子的平均速度,最后通過比較初始和最終狀態,準確得出氣體分子平均速度的變化,答案完全正確。

下一題GPT-4o暴露了在文本推理上的缺陷。
題目涉及水箱出水高度的判斷,描述了一個頂部密封的水箱,里面有壓縮空氣和水,水通過軟管流出,需要確定水流停止時水面的高度。
GPT-4o的分析過程有誤。它分析了水箱內的壓力和水的高度關系,試圖通過平衡條件推導出水流停止時的水面高度,但由于對文本描述的理解出現偏差,計算結果偏離了標準答案。

波動/聲學
你們的團隊正在為飛行員在雨天或濃霧中設計一種著陸輔助裝置。具體方法是在跑道兩側分別放置兩個相距 50 米的無線電發射器。這兩個發射器發出相同頻率但存在相位差的無線電波,從而在跑道中心線上形成一個波節線(干涉最小線)。 當飛機正好對準中心線時,飛行員聽不到聲音;若偏離中心線,則會聽到「嗶」的提示音。為了實現精確導航,希望第一個干涉極大點(聲音最強)出現在離中心線60米、距發射器3.0公里的位置。
問題:應為無線電發射器設定多少頻率?
在解題過程中,GPT-4o錯誤計算了兩個干涉極大線對應的路徑差,從而導致后續的波長計算、頻率都出現了錯誤。

如圖所示,兩個揚聲器相距3.00 米,并且同時發出頻率為474Hz、同相位的聲音。一個麥克風被放置在兩個揚聲器中點正前方3.20米處,在該位置記錄到一個強度最大值(干涉極大)。
問題:麥克風需要向右移動多遠,才能找到第一個強度最小值(干涉極小)的位置?
在解題過程中,GPT-4o正確找到了解題關鍵——理解聲波的相消干涉條件。
在計算相關條件、聲波波長、幾何關系時都給出了正確答案,然而在第四步對小x進行近似展開時,出現了計算錯誤。

光學
下面這道題,看起來很簡單。
如圖所示,一束光線穿過一塊折射率為n=1.50的玻璃塊時,會發生橫向偏移(偏移距離為d)。
問題:求光線通過該玻璃塊所需的時間間隔是多少?
這道題運用了斯涅爾定律和棱鏡幾何知識。GPT-4o雖然正確理解了棱鏡內外折射角的關系,卻在第二步計算θ角時出錯了。

現代物理
Owen和Dina在參考系S中保持靜止,而該參考系S相對于另一個參考系S′(可能是觀察者Ed所在的)在運動。他們正在玩傳球游戲,Ed在S′系中觀看整個過程,如圖所示。Owen把球拋向Dina。
問題:球到達Dina所需的時間間隔是多少?
GPT-4o正確判斷出,此題需要運用狹義相對論的原理。
第二步,就需要將球在S′中的速度轉換為在S中的速度,在運用相對論的速度疊加公式時,它出現了錯誤。

ThePhyX基準測試
PHYX中的每個問題都以真實的物理場景為中心,全面檢驗模型理解和推理物理世界的能力。
詳細的數據統計見表1。

PHYX憑借其精心設計的結構和對多種推理維度的全面覆蓋,為系統測試和提升基礎模型在真實物理推理任務中的能力提供了一個強大的工具。
數據整理過程
為了確保數據的高質量,研究團隊設計了一個四階段的數據收集流程。
- 調研與設計:深入研究核心物理學科,確定基準測試覆蓋范圍,選取多樣化物理領域與子領域,并定義推理類型。
- 專家標注:招募STEM研究生標注團隊,遵守版權規則,避免使用不可復制內容,挑選答案不直接附于問題的題目以減少數據污染。
- 問題轉換與版本:將開放式問題轉為多選題,反之亦然;為每題構建三種版本:原始版、簡潔版(去除冗余文本)、核心問題版。
- 多模態支持:使用GPT-4o為每張圖像生成描述性標題,總結視覺內容,支持大語言模型評估與多模態理解。
這一數據整理過程最終形成了來自各種來源的3300個多樣化問題。
主要結果
PHYX對當前模型來說是個不小的挑戰。
值得注意的是,即便是表現最差的人類專家也能達到75.6%的準確率,遠超團隊分析中包含的所有模型。這表明人類專家與當前模型能力之間存在明顯差距,凸顯了PHYX的高標準和難度。
結果顯示,多選題形式會縮小不同模型之間的性能差距,較弱的模型能通過表面線索「蒙」對答案。
相比之下,開放式問題要求真正的推理能力和精確的答案生成,因此能更好地區分模型能力。這說明開放式問題在評估多模態推理能力時具有更高的區分度。
如表3所示,在波動/聲學和力學等領域,問題通常涉及自然圖像且推理要求較低,模型表現普遍較好。而在熱力學和現代物理等領域,任務往往需要復雜的視覺感知和多步驟推理,模型的表現通常較差。

不同物理領域中,模型在開放式去冗余文本問題上的平均得分。各領域模型的最高得分用藍色高亮顯示,整體最高得分用紅色高亮顯示
討論分析
以推理為核心的模型,如GPT-4o-mini和DeepSeek-R1,分別取得了45.8%和51.2%的準確率,明顯優于通用模型如GPT-4o和Claude3.7-Sonnet。
結果凸顯出專門為推理任務優化的模型所具備的優勢,并表明在彌合多模態推理差距時,模型架構和訓練方式的差異發揮了關鍵作用。
盡管沒有直接的視覺輸入,像DeepSeek-R1和GPT-3o-mini這樣的LLMs在性能上與大多數多模態模型不相上下。
LLMs的出色表現表明,在許多情況下,圖像的文本描述已足以提供推理所需的視覺上下文。
這不僅展現了LLMs強大的泛化能力,也暴露了當前多模態模型(MLLMs)在利用原始視覺信號進行物理推理時的局限性。
研究團隊的實驗顯示,多模態模型在很大程度上依賴詳細的文本描述,其純粹基于視覺上下文的推理能力有限。
相比GPT-4o在MathVista(63.8%)和MATH-V(63.8%)數據集上的表現,其在物理推理任務中的準確率明顯較低。
這一發現表明,物理推理需要更深入地整合抽象概念和現實世界的知識,相比純粹的數學推理,對當前模型來說是更大的挑戰。
為了深入了解模型的推理能力和局限性,團隊仔細檢查了96個隨機抽樣的錯誤,并基于GPT-4o進行了詳細分析。
這次分析有兩個目標:一是找出模型當前的弱點,二是為未來的模型設計和訓練提供改進方向。錯誤分布情況如圖7所示。
- 視覺推理錯誤(39.6%):模型在處理真實物理問題時,誤讀視覺信息或空間關系,比如,誤讀電壓值導致計算錯誤。真實圖片增加挑戰,需提升多模態推理能力。
- 文本推理錯誤(13.6%):模型處理文本時誤解隱含條件或邏輯關系,如忽略「無摩擦」指令,需改進文本推理和語境理解。
- 知識缺失(38.5%):模型缺乏特定領域知識,如忽略波速差異導致幾何推理錯誤,需加強領域知識儲備。
- 計算錯誤(8.3%):模型理解物理背景但在算術、公式應用或單位轉換中出錯,需優化數值計算能力。

基于GPT-4o分析的90個標注錯誤的分布顯示,其中一個典型的視覺推理錯誤對人類來說很簡單,但對GPT-4o卻頗具挑戰