百億級流量的系統架構該怎么設計,今天就來教會你!

一、前情提示
上一篇文章??《第一次當架構師,我設計高并發架構發現了N個痛點。。。》??,給大家初步講述了一套大規模復雜系統中,兩個核心子系統之間一旦耦合,會發生哪些令人崩潰的場景。如果還沒看上篇文章的,建議先看一下。
這篇文章,咱們就給大家來說一說通過MQ消息中間件的使用,如何重構系統之間的耦合,讓系統具備高度的可擴展性。
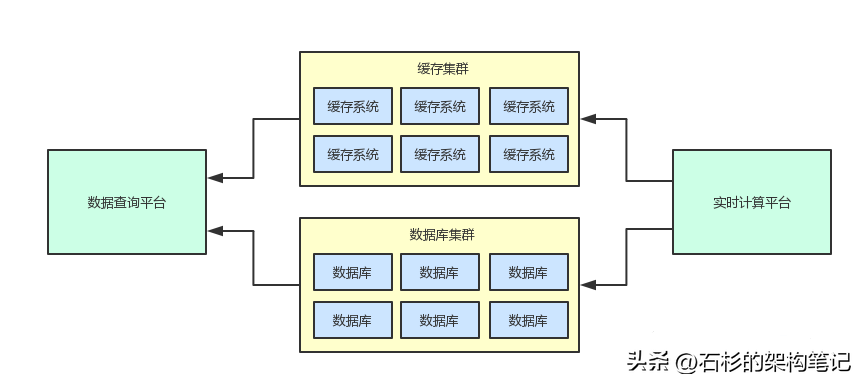
首先來回看一下之前畫的一張兩個系統之間進行耦合的一個大圖,從這個圖里我們可以看到兩個系統完全通過一套共享存儲(數據庫集群+緩存集群)進行了耦合。
二、清晰的劃分系統邊界
只要有耦合,一旦要解決耦合,那么第一個要干的事兒就是先劃分清楚系統之間的邊界。
比如上面那兩套系統都共享了一套存儲集群,那么大家可以先思考一下,兩個系統之間的邊界應該如何劃分?也就是說,中間那套緩存集群和數據庫集群,到底應該是屬于哪個系統?
首先我們看一下,緩存集群和數據庫集群主要是給誰用的?
很明顯就是給數據查詢平臺用的,說白了,那兩套集群都是數據查詢平臺賴以生存的核心底層數據存儲,這里存儲的數據也都是屬于數據查詢平臺的核心數據。
對于實時計算平臺來說,他只不過是將自己計算后的結果寫入到緩存集群和數據庫集群罷了。
實時計算平臺只要寫入過后,后續就不會再管那些數據了,所以這兩套集群明顯是不屬于實時計算平臺的。
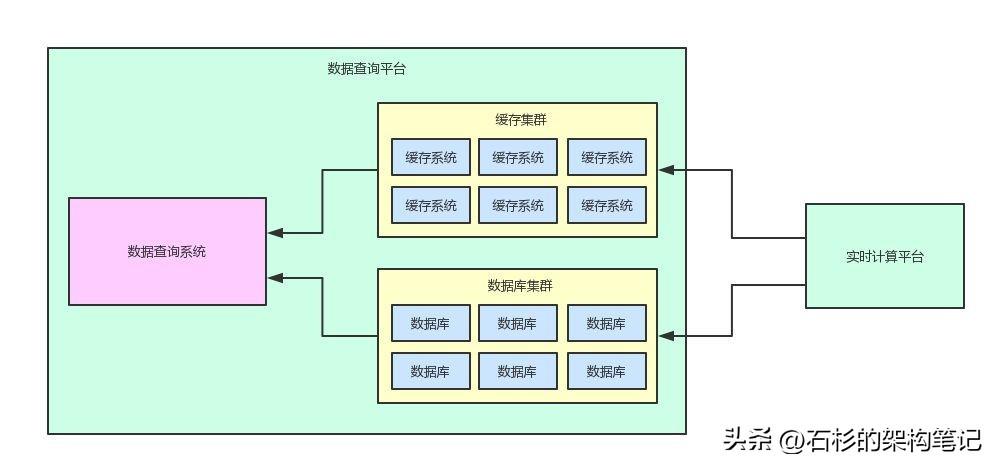
好,那么系統之間的邊界就很清晰的劃分清楚了,大家看一下如下的圖。首先從系統整體架構的架構而言,兩套系統之間的關系應該是下面這樣子的。
三、引入消息中間件解耦
只要劃分清楚了系統之間的邊界,接著下一步,就是引入消息中間件來進行解耦了。
我們只要引入一個消息中間件,然后讓實時計算平臺將計算好的數據按照預設的格式直接寫入到消息中間件即可。
同時,數據查詢平臺需要增加一個數據接入服務,這個數據接入服務就是負責將消息中間件里的數據消費出來,然后落地寫入到本地的緩存集群和數據庫集群。
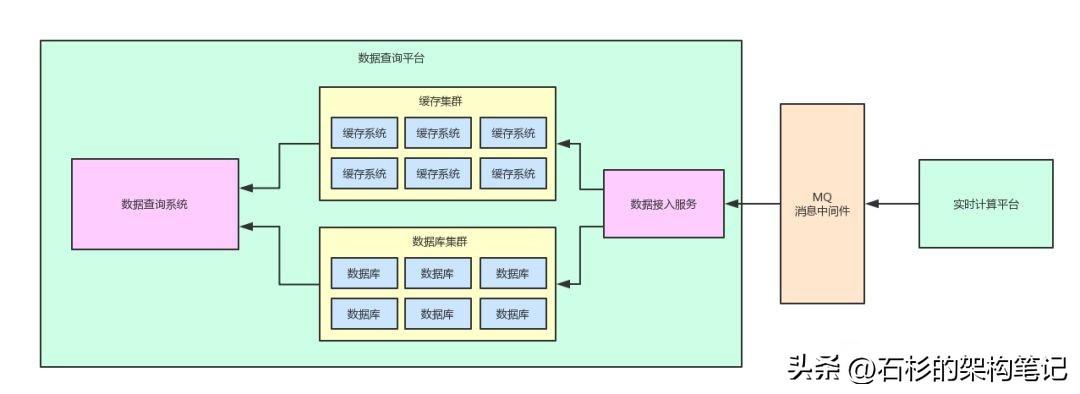
如上圖所示,此時兩個系統之間已經不再直接基于共享數據存儲進行耦合了,中間加入了MQ消息中間件。
這個消息中間件僅僅就是用于兩個系統之間的數據交互和傳輸,職責簡單,清晰明了。
這樣做最大的好處,就是數據查詢平臺自身可以對涌入自身平臺的數據按照自己的需求進行定制化的管控了,不會像之前那樣的被動。
實際上在上述架構之下,涌入數據查詢平臺的所有數據,都需要經過數據接入服務那一關。在數據接入服務那里就可以隨意根據自己的情況進行管理。
四、利用消息中間件削峰填谷
還記得上一篇文章我們提到,這兩個系統之間第一個大痛點,就是實時計算平臺會高并發寫入數據查詢平臺,之前不做任何管控的時候,導致各種意外發生。
舉個例子,比如快速增長的寫庫壓力導致數據查詢平臺必須優先cover住分庫分表那塊的架構,打破自己的架構演進節奏;
比如突然意外出現的熱數據因為不做任何寫入管控,一下子差點把數據庫服務器擊垮。
因此一旦用消息中間件在中間擋了一層之后,我們就可以進行削峰填谷了。
那什么叫做削峰填谷呢?其實很簡單,我們先來看看,如果不做任何管控,實時計算平臺寫入數據庫集群的寫并發曲線圖,大概如下面所示。
在高峰期,寫入會有一個陡然上升的尖峰。
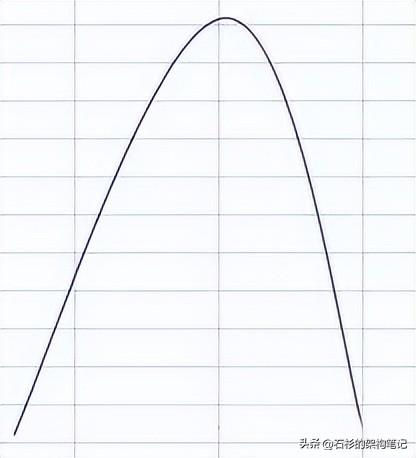
就好比說,平時每秒寫入并發就500,但是高峰期寫入并發請求有5000,那么大家就會看到上面的那張圖,在高峰期突然冒出來一個尖峰,一下子涌入并發5000請求,此時數據查詢平臺的數據庫集群可能就會受不了。
但是,如果我們在數據接入服務里做一個限流控制呢?
也就是說,在數據接入服務里,根據當前數據查詢平臺的數據庫集群能承載的并發上限,比如說就是最多承載每秒3000。
好!那么數據接入服務自己就控制好,每秒最多就往自己本地的數據庫集群里寫入最多每秒3000的請求壓力。
此時就會出現削峰填谷的效果,大家看下面的圖。

因為在高峰期瞬時寫入壓力最大有5000/s,但是數據接入服務做了流量控制,最多就往本地數據庫集群寫入3000/s,那么每秒就會有2000條數據在消息中間件里做一個積壓。
但是積壓一會兒不要緊,最起碼保證說在高峰期,這個向上的尖峰被削平了,這就是所謂的削峰。
然后在高峰期過了之后,本來每秒可能就100/s的寫入壓力,但是此時數據接入服務會持續不斷的從消息中間件里取出來數據然后持續以最大3000/s的寫入壓力往本地數據庫集群里寫入。
那么在低峰期,大家看到還會持續一段時間是3000/s的寫入速度往本地數據庫里寫。
原來的圖里在低峰期是谷底,現在谷底被填平了,這就是所謂的填谷。
通過這套削峰填谷的機制,就可以保證數據查詢平臺完全能夠以自己接受的了的速率,均勻的把MQ里的數據拿出來寫入自己本地數據庫集群中。
這樣子無論實時計算平臺多高的并發請求壓力過來,哪怕是那種異常的熱數據,瞬間上萬并發請求過來也無所謂了。
因為MQ中間件可以抗住瞬間高并發寫入,但是數據查詢平臺永遠都是穩定勻速的寫入自己本地數據庫。
這樣的話,數據查詢平臺就不需要去過多的care實時計算平臺帶給自己的壓力了,可以按照自己的節奏規劃好整體架構的演進策略,按照自己的腳本去迭代架構。
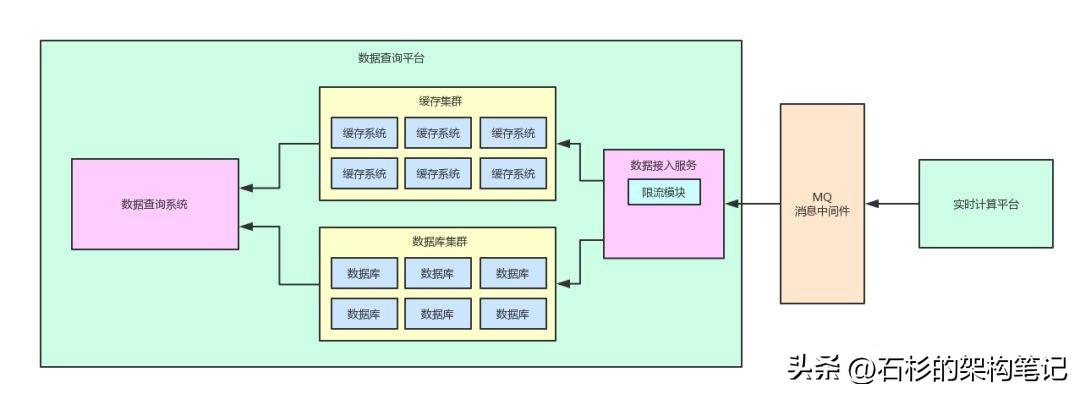
說了那么多,老規矩!給大家來一張圖,此時的架構圖如下所示。
大伙兒可以直觀的感受一下,在數據接入服務中多了一個限流的模塊。
五、手動流量開關配合數據庫運維操作
現在基于消息中間件將兩個系統隔離開來之后,另外一個大的好處就是:數據查詢平臺做任何數據運維的操作,比如說DDL、分庫分表擴容、數據遷移,等等諸如此類的操作,已經跟實時計算平臺徹底無關了。
實時計算平臺主要就是簡單的往消息中間件寫入,其他的就不用管了。
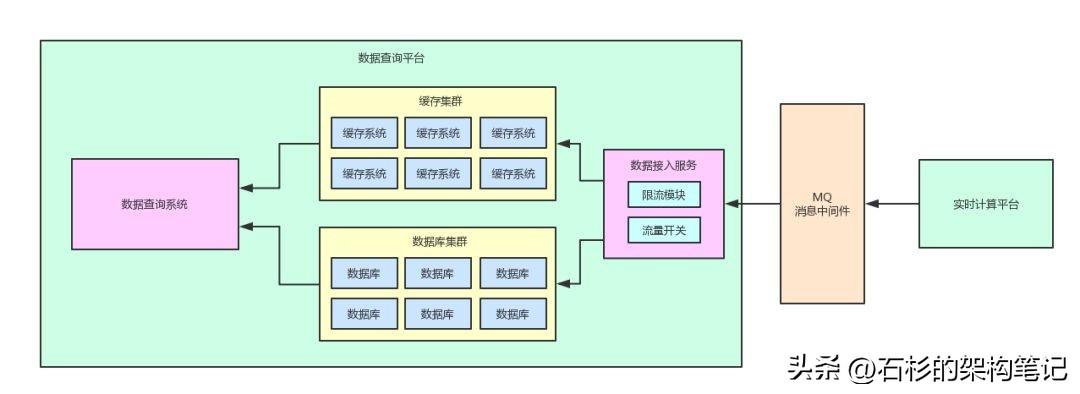
然后如果數據查詢平臺要做一些數據庫運維的操作,此時就可以通過在數據接入服務中加入一個手動流量開關,臨時將流量開關關閉一會兒。
比如選擇一個下午大家都在工作或者午睡的時候,相對低峰的時期,半小時內關閉流量開關。
然后此時數據接入服務就不會繼續往本地數據庫寫入數據了,此時寫入操作就會停止,然后就在半小時內迅速完成數據庫運維操作。
等相關操作完成之后,再次打開流量開關,繼續從MQ里消費數據再快速寫入到本地數據庫內即可。
這樣,就可以完全避免了同時寫入數據,還同時進行數據庫運維操作的窘境。否則在早期耦合的狀態下,每次進行數據庫運維操作,還得實時計算平臺團隊的同學配合一起進行各種復雜操作,才能避免線上出現故障,現在完全不需要人家的參與了,自己團隊就可以搞定。
整個過程,我們還是用一張圖,給大家呈現一下:
六、支持多系統同時訂閱數據
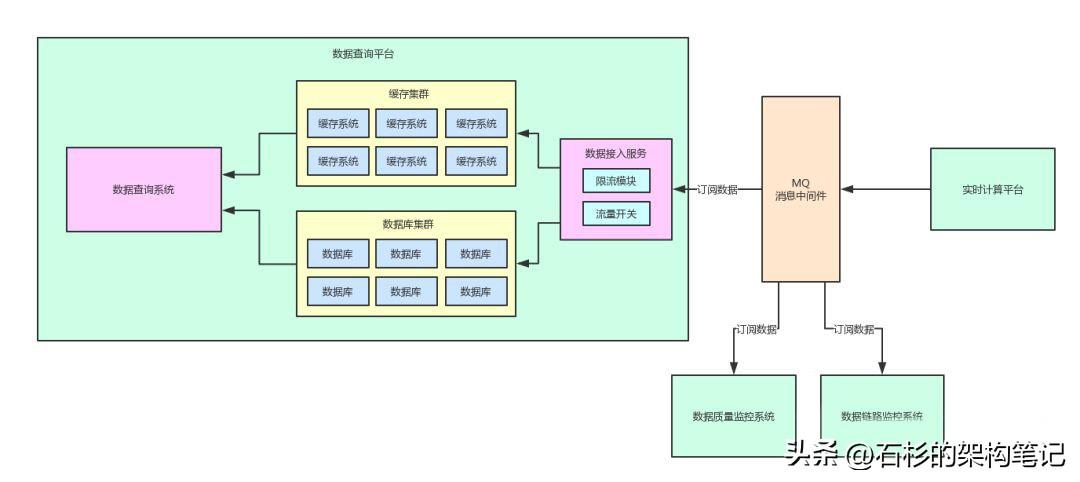
引入消息中間件之后,還有另外一個好處,就是其他的一些系統也可以按照自己的需要去MQ里訂閱實時計算平臺計算好的數據。
舉個例子,在這套平臺里,還有數據質量監控系統,需要獲取計算數據進行數據結果準確性和質量的監控。
另外,還有數據鏈路監控系統,同樣需要將MQ里的數據作為數據計算鏈路中的一個核心點數據采集過來,進行數據全鏈路的監控和自動追蹤。
如果沒有引入MQ消息中間件概念的話,那么是不是就會導致實時計算平臺除了將數據寫入一份到數據庫集群,還需要通過接口發送給數據質量監控系統?還需要發送給數據鏈路監控系統?這樣簡直是坑爹到不行,N個系統全部耦合在一起。
這樣每次要是有一點變動?,各個系統的負責人都在一起開會商討,修改代碼,修改接口,考慮各種調用細節,等等。
但是現在有了消息中間件,完全可以通過MQ支持的“Pub/Sub”消息訂閱模型,不同的系統都可以來訂閱同一份數據,大家自己按需消費,按需處理,各個系統之間完全解耦。
整個系統的可擴展性瞬間提升了很多,因為各個系統各自迭代和演進架構,都不需要強依賴其他的系統了。?
七、系統解耦后的感受
云開霧散!各個團隊的同學終于不用天天扯皮,今天說你的系統影響了我,明天是我的系統影響了你。
同時也壓根兒不用去關注其他的系統,只要有一個總架構師把控好整體架構,各個team都按照這個分工協作來做即可。
消息中間件的引入,消除了系統的耦合性,大幅度提升了系統的可擴展性,各個team都可以快速的獨立的迭代擴展自己的架構和系統。
PS:最重要的,不同team的同學,再也不用為了一些雞毛蒜皮的事兒加班到深更半夜,導致他們的女朋友覺得他們要在一起了。