













如何在Python中加入多個數據幀?
初學Python編程的人,面臨的是各種未知的挑戰。
下面是一個幾乎讓所有更有抱負的數據科學家都感到意外的場景:
你正在處理一個從多個源收集數據的項目。在進入探索和模型構建部分之前,你需要首先連接這些多個數據集(以表、數據幀等形式)。怎么能做到這一點而不丟失任何信息?
這聽起來可能是一個簡單的場景,但對于許多新來的人來說,這可能是一個威脅,特別是那些不熟悉Python編程的人。
進一步深入研究,我可以大致將其分為兩種情況:
- 首先,具有相似屬性的數據可以分布到多個文件中。例如,假設向你提供了多個文件,每個文件都存儲一年中某一周內發生的銷售信息。因此,全年將有52個文件。每個文件的列數和名稱都相同。
- 其次,你可能需要合并來自多個來源的信息。例如,假設你想獲得購買產品的人的聯系信息。這里有兩個文件,第一個有銷售信息,第二個有客戶信息。
理解手頭的問題
本文列舉一個通俗易懂的例子。
想一下在一個特定的學校里考試。每個科目都有不同的老師授課。他們更新關于學生成績和整體表現的檔案。這些檔案就是多個文件!
本文使用創建的兩個這樣的文件來演示Python中函數的工作。第一個文件包含關于12班學生的數據,另一個文件包含10班的數據。還將使用第三個文件來存儲學生的姓名和學生ID。
注意:雖然這些數據集是從零開始創建的,但鼓勵將所學應用于選擇的數據集。
在Python中逐步合并數據幀的過程
下面是解決這個問題的方法:
- 用Python加載數據集
- 合并兩個相似的數據幀(append)
- 合并來自兩個數據幀的信息(merge)
步驟1:用Python加載數據集
本文將使用三個獨立的數據集。首先,將這些文件加載到單獨的數據幀中。
- import pandas as pd
- marks10th=pd.read_csv('10thClassMarks.csv')
- marks12th=pd.read_csv('12thClassMarks.csv')
- IDandName=pd.read_csv('StudentIDandName.csv')
前兩個數據框包含學生的百分比及其學生ID。在第一個數據框中,有10班學生的分數,而第二個數據框包含第12個標準中學生的分數。第三個數據框包含學生的姓名以及各自的學生ID。
來源:btime
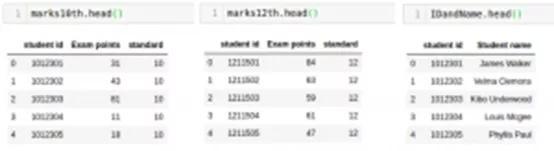
使用“head”函數檢查每個數據幀的前幾行:
- marks10th.head()
- marks12th.head()
- IDandName.head()
步驟2:合并兩個相似的數據幀(Append)
把10、12班的檔案合并起來,找出學生的平均分。這里使用Pandas庫中的“append”函數:
- allMarks=marks10th.append(marks12th)
- marks10th.shape, marks12th.shape, allMarks.shape
輸出((50,3),(50,3),(100,3))
從輸出中可以看到,在append函數中垂直添加兩個數據幀。
結果數據幀是allMarks。上面比較了所有三個數據幀的形狀。
接下來看看“allMarks”的內容并計算平均值:
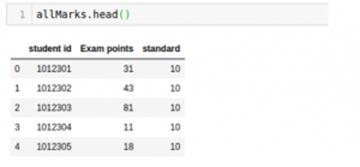
- allMarks['Exam Points'].mean() #Average Marks
輸出:49.74
步驟3:合并來自兩個數據幀的信息(Merge)
現在,假設想找出在這兩個批次中排名第一的學生的名字。這里不需要垂直添加數據幀。為了給學生的名字再加一列,我們將不得不水平縮放。
要做到這一點,我們會發現最高得分:
- allMarks['Exam Points'].max() # Maximum Marks
輸出:100
學生的最高成績是100分。現在,使用“merge”函數查找此學生的姓名:
- mergedData=allMarks.merge(IDandName, on='student id')
- mergedData.head()
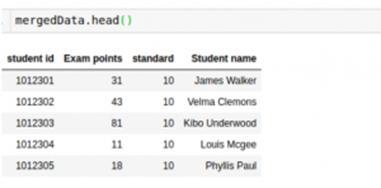
最后,生成的數據框有學生的名字和他們的標記。
merge函數需要一個必要的屬性,兩個數據幀將在該屬性上合并。需要傳遞此列的名稱在“on”參數中。
merge函數的另一個重要論點是“如何”。這指定要在數據幀上執行的聯接類型。以下是可以執行的不同連接類型(SQL用戶將非常熟悉這一點):
- 內部連接(如果不提供任何參數,則默認執行)
- 外部連接
- 右連接
- 左連接
還可以使用“sort”參數對數據幀進行排序。這些是合并兩個數據幀時最常用的參數。
來源:Pexels
現在,我們將看到數據框包含100個“檢查點”的行:
- mergedData.loc[mergedData['Exam Points']==100]
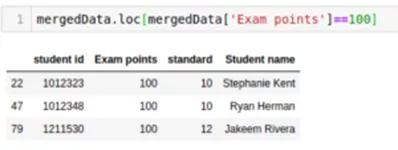
三個學生得了100分,其中兩個在10班。做得好!
接下來,我的建議是接受包含3個不同文件的食物預測挑戰。
很直截了當,對吧?
你再也不必為此而自責了!你可以繼續并將其應用于選擇的任何數據集。















