MacBook顯卡不跑AI模型太浪費:這個深度學習工具支持所有品牌GPU
通過這款名為 PlaidML 的工具,不論英偉達、AMD 還是英特爾顯卡都可以輕松搞定深度學習訓練了。
眾所周知,深度學習是因為 2010 年代英偉達 GPU 算力提升而快速發展起來的,不過如今市面上還有多種品牌的顯卡,它們同樣擁有不錯的性能,后者能不能成為 AI 模型算力的基礎呢?
如果答案是肯定的,那我們的筆記本電腦豈不就可以用來跑深度學習模型了,尤其是讓我們下了血本的 MacBookPro。
MacBookPro 在科技圈覆蓋面頗廣,質量也不錯,不能拿來做深度學習實在可惜。在選購 MacBook 的過程中,有些人會為了獨立顯卡而多花點錢,但到了做深度學習的時候卻發現這錢花得很冤枉,因為長期以來,多數機器學習模型只能通過通用 GPU 庫 CUDA 使用英偉達的 GPU。
但我們真的別無選擇嗎?medium 的一位博主表示,事實并非如此。一款名為 PlaidML 的深度學習框架可以破解這個困境。

為什么要用 GPU 做并行計算?
以建房子為例:如果單獨完成,你需要花費 400 個小時,但如果你雇一個建筑工人,工期就可能減半。雇傭的工人越多,你的房子建得也越快。這就是阿姆達爾定律所揭示的內容。它是一個計算機科學界的經驗法則,代表了處理器并行運算之后效率提升的能力。
那么為什么要用 GPU 呢?最初 GPU 并不是為深度學習專門設計的,但并行計算的本質似乎與圖形處理類似。單個 GPU 的核心雖然在性能上弱一些,但在處理大數據塊的算法上比 CPU 更高效,因為它們具有高度并行的結構,而且核的數量也非常多。由于圖形處理和深度學習在本質上的相似性,GPU 就成為了深度學習和并行計算的首選。
除了 CUDA 就沒得選了嗎?
不過要想用上 GPU 的并行能力,英偉達的 CUDA 就不可回避,這種通用并行計算庫是做深度學習所必須的。目前,之所以高性能云計算、DL 服務器都采用英偉達 GPU,主要原因還是在 CUDA。
如果想要充分利用筆記本的并行能力,且 N 卡又配不起,那么這篇文章介紹的 PlaidML 就非常合適了。
項目地址:https://github.com/plaidml/plaidml
PlaidML 是 Vertex.AI 2017 年開源的一款深度學習工具包。2018 年,英特爾收購了 Vertex.AI。之后 PlaidML 0.3.3 發布,開發者可以借助 Keras 在自己的 AMD 和英特爾 GPU 上完成并行深度學習任務。上個月,Vertex.AI 又發布了 PlaidML 的 0.7.0 版本。

PlaidML 是一種可移植的張量編譯器,可以在筆記本電腦、嵌入式設備或其他設備上進行深度學習。重要的是,它并不依賴于 CUDA,而是 OpenCL 這種開放標準。
OpenCL 通用并行計算開放標準并不是為 N 卡專門設計的,因此不論你的筆記本 GPU 是 AMD、 Intel,還是 NVIDIA,它都能支持。
很多讀者可能認為,OpenCL 的生態沒有 CUDA 成熟,可能在穩定性與開發速度上都沒那么快。但是,我們可以把復雜的底層機制都交給 PlaidML,我們只需要用就行了。
甚至 PlaidML 我們都不需要接觸,它已經集成到了常見的深度學習框架中,并允許用戶在任何硬件中調用它。目前 PlaidML 已經支持 Keras、ONNX 和 nGraph 等工具,直接用 Keras 建個模,MacBook 輕輕松松調用 GPU。
下面我們開始進入正題:如何用自己筆記本電腦的 GPU 運行一個簡單的 CNN。
用筆記本 GPU 運行一個神經網絡
安裝和設置 PlaidML 和相關組件
首先,我們要確保自己的筆記本電腦安裝了 Python 3 工作環境。作者建議在虛擬環境下運行以下代碼:
- # install python3 virtualenv if you haven’t done so:
- pip3 install virtualenv
- # Now create and activate a virtual environment for the case
- python3 -m venv plaidml-venv
- source plaidml-venv/bin/activate
- # Install PlaidML with Keras
- pip install -U plaidml-keras
記住一點,標準 TensorFlow 框架下的 Keras 無法使用 PlaidML,需要安裝 PlaidML 定制的 Keras。
- # Now setup PlaidML to use the right device
- plaidml-setup

設置 PlaidML 第二步。
現在得到了自己選擇的設備列表。以作者的電腦 Macbook Pro 15’2018 為例,設備列表如下:
- CPU
- 英特爾 UHD Graphics 630 顯卡
- AMD Radeon pro 560x 顯卡
最后,鍵入「y」或「nothing」,返回保存設置。這樣以來,我們就已安裝所有設備,并且可以使用 GPU 來運行深度學習項目了。
在 fashion mnist 上創建 CNN 分類器
首先,啟動 Jupyter Notebook。
- Jupyter Notebook
然后按順序運行以下代碼,將 PlaidML 用作 Keras 后端,否則會默認使用 TensorFlow。
- # Importing PlaidML. Make sure you follow this order
- import plaidml.keras
- plaidml.keras.install_backend()
- import os
- os.environ["KERAS_BACKEND"] = "plaidml.keras.backend"
現在就可以導入包,并下載 fashion 數據集。
- import keras
- from keras.models import Sequential
- from keras.layers import Dense, Dropout, Flatten
- from keras.layers import Conv2D, MaxPooling2D
- from keras import backend as K
- # Download fashion dataset from Keras
- fashion_mnist = keras.datasets.fashion_mnist
- (x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
- # Reshape and normalize the data
- x_train = x_train.astype('float32').reshape(60000,28,28,1) / 255
- x_test = x_test.astype('float32').reshape(10000,28,28,1) / 255
接下來使用 Keras 的序貫模塊來創建一個簡單的 CNN,并編譯它。
- # Build a CNN model. You should see "INFO:plaidml:Opening device xxx" after you run this chunk
- model = keras.Sequential()
- model.add(keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)))
- model.add(keras.layers.MaxPooling2D(pool_size=2))
- model.add(keras.layers.Dropout(0.3))
- model.add(keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'))
- model.add(keras.layers.MaxPooling2D(pool_size=2))
- model.add(keras.layers.Dropout(0.3))
- model.add(keras.layers.Flatten())
- model.add(keras.layers.Dense(256, activation='relu'))
- model.add(keras.layers.Dropout(0.5))
- model.add(keras.layers.Dense(10, activation='softmax'))
- # Compile the model
- model.compile(optimizer='adam',
- loss=keras.losses.sparse_categorical_crossentropy,
- metrics=['accuracy'])
現在我們擬合模型,測試一下它的準確率。
- # Fit the model on training set
- model.fit(x_train, y_train,
- batch_size=64,
- epochs=10)
- # Evaluate the model on test set
- score = model.evaluate(x_test, y_test, verbose=0)
- # Print test accuracy
- print('\n', 'Test accuracy:', score[1])

更多結果。
我們訓練的卷積神經網絡模型在時尚分類任務上達到了 91% 的準確率,訓練只用了 2 分鐘!這個數字可能看起來并不驚艷,但想想 CPU 訓練要多久吧:

用 CPU 完成相同的任務要用 2219 秒(約 37 分鐘),MAC 風扇期間還會瘋狂輸出。
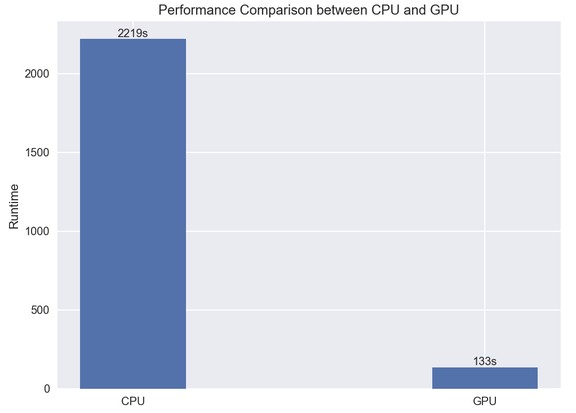
從以上結論中我們可以看到,借助 Macbook Pro 搭載的 GPU 進行深度學習計算要比簡單地用 CPU 快 15 倍。通過 PlaidML,使用自己的筆記本電腦訓練深度學習模型將變得更加簡單。
截至目前(2020 年 2 月),PlaidML 可以和各種品牌的 GPU 兼容,在使用英偉達顯卡時也無需 CUDA/cuDNN,也能達到類似的性能。
在 PlaidML 的 GitHub 頁面上你能看到更多的 demo 和相關項目,相信隨著這一工具的不斷發展,它可以支持的算法也會越來越多。我們在自己的筆記本上,也能快速試驗個小模型。