數據分析實戰:使用Python分析新型冠狀病毒的發展趨勢
這次疫情的情況大家也都了解了,各地也都延遲開學或者延遲開工,對于我們來說,正好是一次深入學習的機會。今天,我就帶領大家分析一下新型冠狀病毒的爆發趨勢,也借此作為一次數據分析課程的實戰案例,從 數據獲取、數據清洗、數據可視化再到產出數據結論,完整的走一遍數據分析流程。
這次使用的數據是霍普金斯大學收集的世界范圍內的病毒爆發數據。
導入所需的包和數據
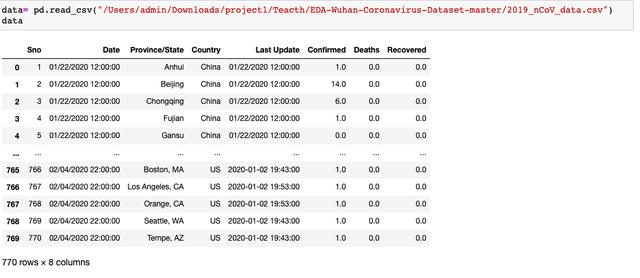
數據清洗
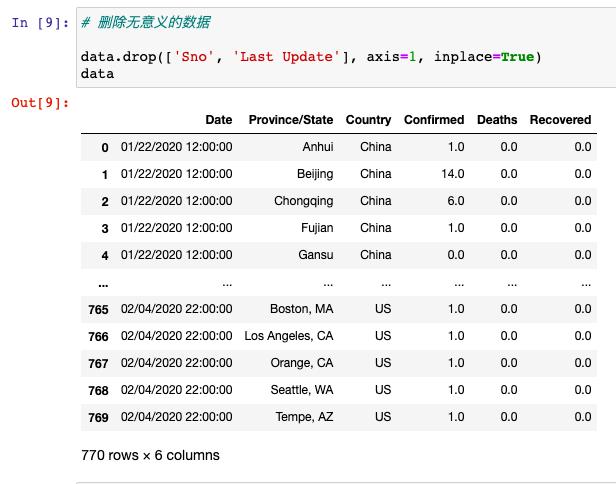
第一:刪除不需要的數據列
從數據中我們可以看出,第一列相當于編號,第五列是數據更新的最后時間,這兩列對我們的分析來說沒有實際意義,所以先把這兩列進行刪除操作:
第二:對數據集中的空值進行處理
先來看一下數據的整體情況:
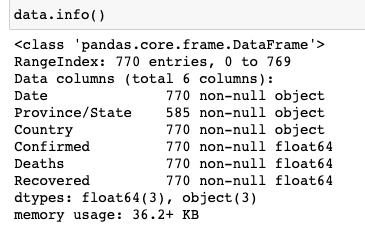
我們發現,只有省份這一個字段是有空值的,那我們再來看一下具體的空值有哪些:
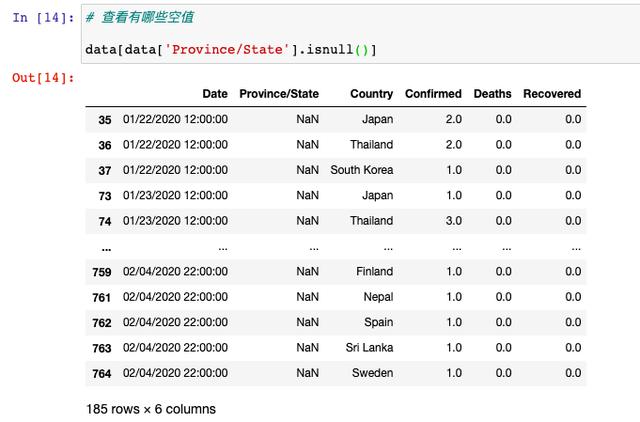
經過篩選發現,空缺的都是一些國外的省份,這是由于數據收集過程中產生的,并且我們無從推斷到底是什么,所以,這里的空值我們選擇不處理。
第三:刪除重復數據
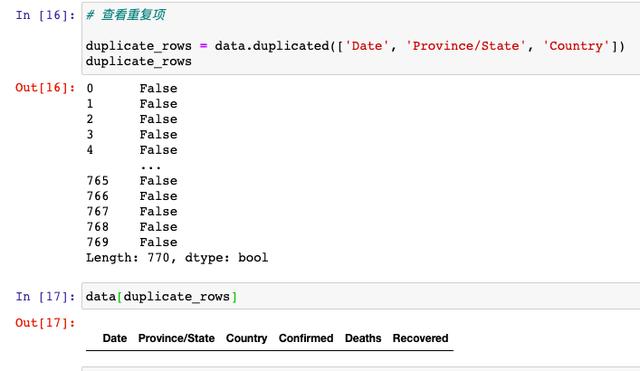
通過使用dumplicate方法,我們發現這個人工整理的數據集不存在重復情況,所以也不需要進行去重操作。
數據洞察
我們首先來看一下,截止到數據完成時間,世界上總共有多少國家已經「淪陷」了:

通過統計發現,總共只有32個國家已經有了確診患者,但是,細心的同學可能會發現,國家列表當中有「China」和「Mainland China」,第二個表示的是「中國大陸」,其實也是中國,所以我們應該把「Mainland China」也改為「China」統一口徑,在實際工作過程中,跨部門的數據經常會出現這種情況,所以,處理這種數據噪音也是數據分析師的日常工作之一。
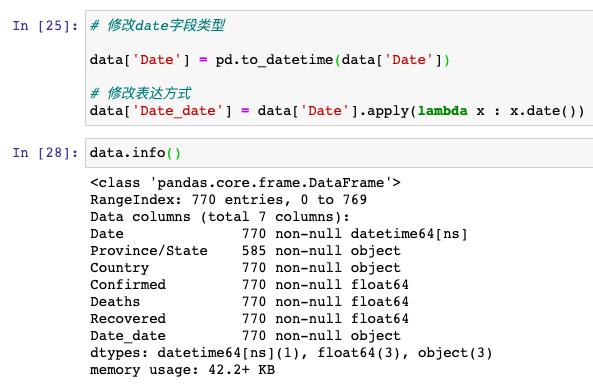
接著,我們看一下時間字段,時間字段的處理也是數據分析過程中不可或缺的一個步驟:

這里的時間,都是精確到「小時」的,為了便于統計,我們把它改成精確到「日」:
接下來,我們以國家作為維度,來統計一下每個國家的確診人數:
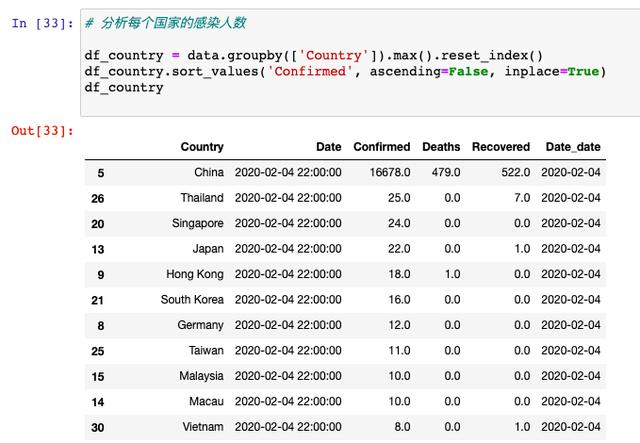
排名第一的肯定是中國,排名靠前的基本都是中國臨近的亞洲國家,歐美國家當中,排名第一的是德國,如果是真正工作過程中,德國這一點就是「異常點」,肯定要深入挖掘,在這里我們只是做一個示例。
之后我們以時間作為維度,分析一下每天的感染人群數量的變化:
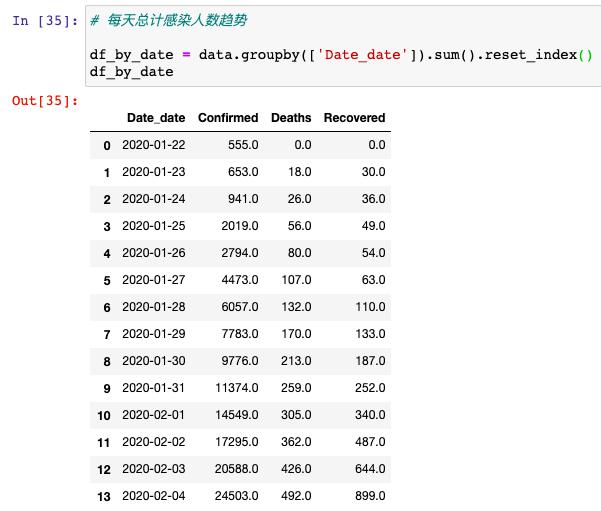
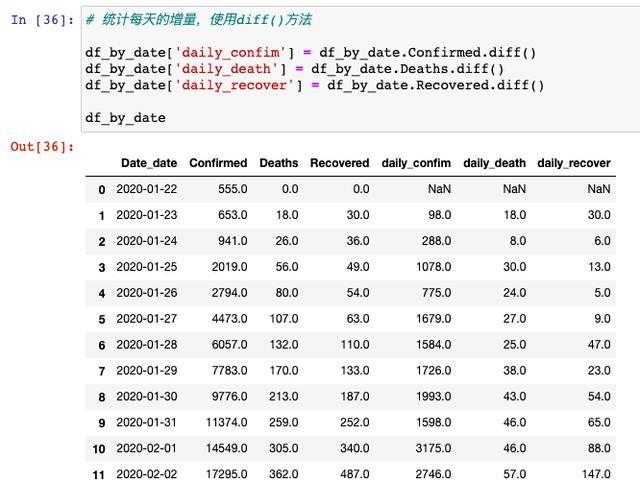
從這里可以看到,14天之內感染人數就從555人增長到24503個人,增長速度還是很快的,那我們接著也要具體分析一下,每天新增的確診人數有多少人,這里我們需要用到diff( )方法:
數據可視化
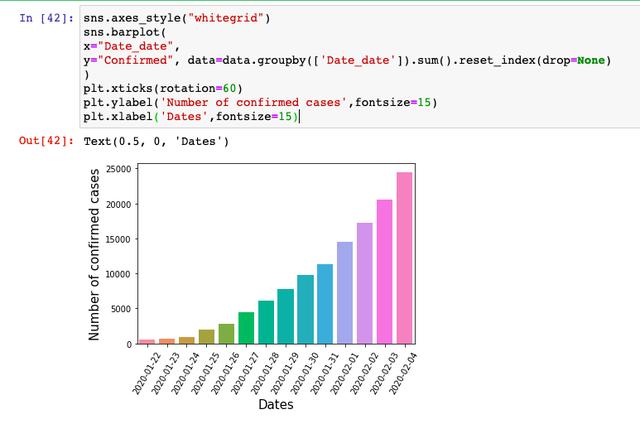
首先來看每天的確診人數,基本上是指數增長的一個走勢,符合傳染病的爆發規律,我們要做的就是根據之后的數據,洞察拐點的到來。
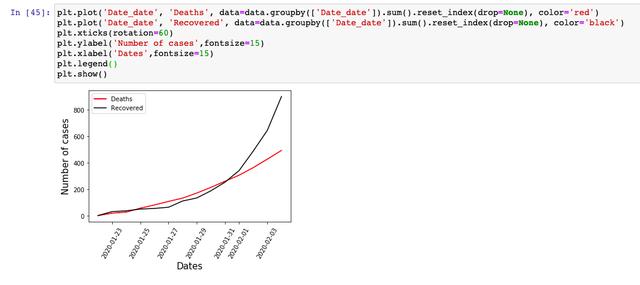
接著,我們看一下,每天的「死亡人數」和「治愈人數」的走勢,從這個數據上來看,治愈人數的增長趨勢已經超過的死亡人數,所以,從「最好」和「最壞」兩個方面來說的話,總體趨勢還是向好發展,大家也不必過于擔心。
總結
以上分析只是拋磚引玉,使用一部分數據來引導大家參與到數據分析的實戰流程當中,歡迎大家在留言區一起討論學習。