超越谷歌MobileNet!華為提出端側(cè)神經(jīng)網(wǎng)絡(luò)架構(gòu)GhostNet|已開源
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
同樣精度,速度和計(jì)算量均少于此前SOTA算法。這就是華為諾亞方舟實(shí)驗(yàn)室提出的新型端側(cè)神經(jīng)網(wǎng)絡(luò)架構(gòu)GhostNet。
GhostNet的核心是Ghost模塊,與普通卷積神經(jīng)網(wǎng)絡(luò)相比,在不更改輸出特征圖大小的情況下,其所需的參數(shù)總數(shù)和計(jì)算復(fù)雜度均已降低,而且即插即用。
在ImageNet分類任務(wù)中,GhostNet在各種計(jì)算復(fù)雜度級(jí)別上始終優(yōu)于其他競(jìng)爭(zhēng)對(duì)手,比如谷歌的MobileNet系列、曠視的ShuffleNet系列、IGCV3、ProxylessNAS、FBNet、MnasNet等等。
關(guān)于GhostNet的論文已經(jīng)被CVPR 2020收錄,模型與代碼也已經(jīng)在GitHub上開源。華為諾亞方舟實(shí)驗(yàn)室是如何做到的?我們根據(jù)作者團(tuán)隊(duì)的解讀,一一看來。
核心理念:用更少的參數(shù)來生成更多特征圖
通常情況下,為了保證模型對(duì)輸入數(shù)據(jù)有全面的理解,訓(xùn)練好的深度神經(jīng)網(wǎng)絡(luò)中,會(huì)包含豐富甚至冗余的特征圖。
如下圖所示,ResNet-50中,將經(jīng)過第一個(gè)殘差塊處理后的特征圖,會(huì)有出現(xiàn)很多相似的“特征圖對(duì)”——它們用相同顏色的框注釋。
這樣操作,雖然能實(shí)現(xiàn)較好的性能,但要更多的計(jì)算資源驅(qū)動(dòng)大量的卷積層,來處理這些特征圖。

在將深度神經(jīng)網(wǎng)絡(luò)應(yīng)用到移動(dòng)設(shè)備的浪潮中,怎么保證性能不減,且計(jì)算量變得更少,成為研究的重點(diǎn)之一。
谷歌的MobileNet團(tuán)隊(duì),以及曠視的ShuffleNet團(tuán)隊(duì),最近想了不少辦法來構(gòu)建低計(jì)算量的深度神經(jīng)網(wǎng)絡(luò)。但他們采取的深度卷積或混洗操作,依舊是在卷積上下功夫——用較小的卷積核(浮點(diǎn)運(yùn)算)。
華為諾亞實(shí)驗(yàn)室的團(tuán)隊(duì)沒有沿著這條路前進(jìn),而是另辟蹊徑:
“特征圖對(duì)”中的一個(gè)特征圖,可以通過廉價(jià)操作(上圖中的扳手)將另一特征圖變換而獲得,則可以認(rèn)為其中一個(gè)特征圖是另一個(gè)的“幻影”。
這是不是意味著,并非所有特征圖都要用卷積操作來得到?“幻影”特征圖,也可以用更廉價(jià)的操作來生成?
于是就有GhostNet的基礎(chǔ)——Ghost模塊,用更少的參數(shù),生成與普通卷積層相同數(shù)量的特征圖,其需要的算力資源,要比普通卷積層要低,集成到現(xiàn)有設(shè)計(jì)好的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)中,則能夠降低計(jì)算成本。
具體的操作在這里就不詳細(xì)敘述了,如果你有興趣,可以去看下論文(地址在文末)。
構(gòu)建新型端側(cè)神經(jīng)網(wǎng)絡(luò)架構(gòu)GhostNet
利用Ghost模塊的優(yōu)勢(shì),研究團(tuán)隊(duì)提出了一個(gè)專門為小型CNN設(shè)計(jì)的Ghost bottleneck(G-bneck)。其架構(gòu)如下圖所示,與ResNet中的基本殘差塊(Basic Residual Block)類似,集成了多個(gè)卷積層和shortcut。
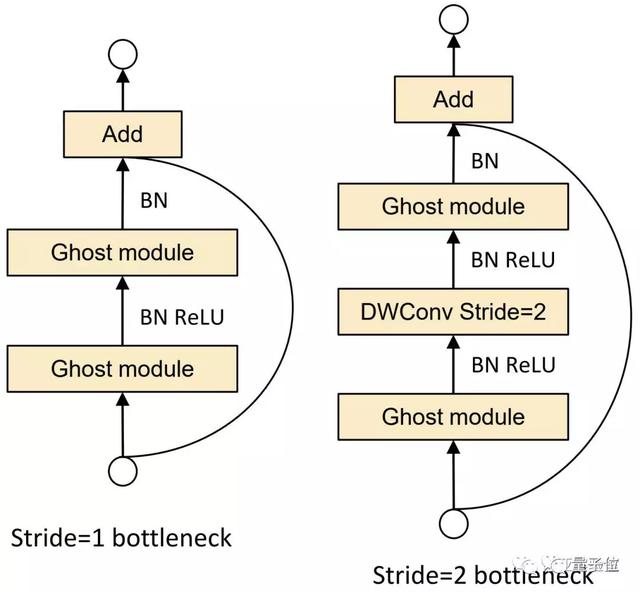
Ghost bottleneck主要由兩個(gè)堆疊的Ghost模塊組成。第一個(gè)用作擴(kuò)展層,增加了通道數(shù)。第二個(gè)用于減少通道數(shù),以與shortcut路徑匹配。然后,使用shortcut連接這兩個(gè)Ghost模塊的輸入和輸出。
研究團(tuán)隊(duì)表示,這里借鑒了MobileNetV2中的思路:第二個(gè)Ghost模塊之后不使用ReLU,其他層在每層之后都應(yīng)用了批量歸一化(BN)和ReLU非線性激活。
這里說的Ghost bottleneck,適用于上圖Stride= 1情況。對(duì)于Stride = 2的情況,shortcut路徑由下采樣層和Stride = 2的深度卷積(Depthwise Convolution)來實(shí)現(xiàn)。
此外,而且出于效率考慮,Ghost模塊中的初始卷積是點(diǎn)卷積(Pointwise Convolution)。
在Ghost bottleneck的基礎(chǔ)上,研究團(tuán)隊(duì)提出了GhostNet——遵循MobileNetV3的基本體系結(jié)構(gòu)的優(yōu)勢(shì),用Ghost bottleneck替換MobileNetV3中的bottleneck。
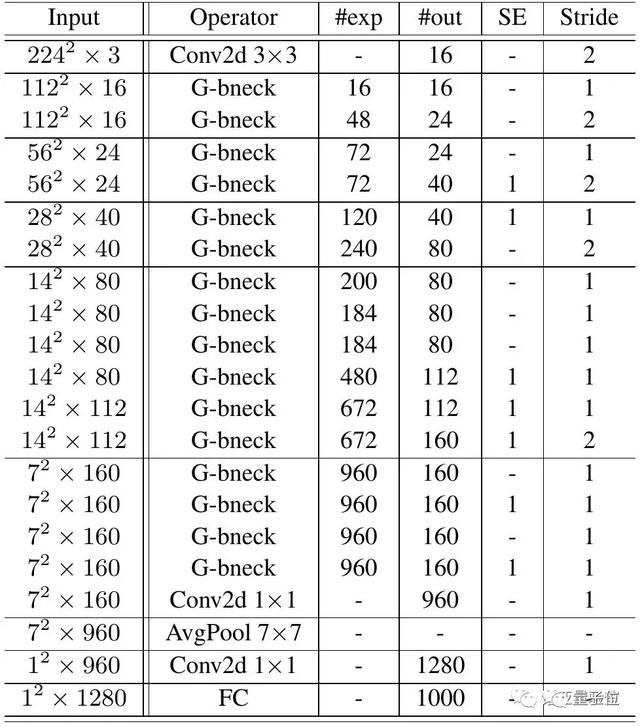
第一層是具有16個(gè)卷積核的標(biāo)準(zhǔn)卷積層,然后是一系列Ghost bottleneck,通道逐漸增加。
Ghost bottleneck根據(jù)輸入特征圖的大小分為不同的階段,除了每個(gè)階段的最后一個(gè)Ghost bottleneck是Stride = 2,其他所有Ghost bottleneck都以Stride = 1進(jìn)行應(yīng)用。
最后,會(huì)利用全局平均池和卷積層將特征圖轉(zhuǎn)換為1280維特征向量以進(jìn)行最終分類。SE模塊也用在了某些Ghost bottleneck中的殘留層。與MobileNetV3相比,這里用ReLU換掉了Hard-swish激活函數(shù)。
研究團(tuán)隊(duì)表示,這里的架構(gòu)只是一個(gè)基本的設(shè)計(jì)參考,進(jìn)一步的超參數(shù)調(diào)整或基于自動(dòng)架構(gòu)搜索的Ghost模塊將進(jìn)一步提高性能。
ImageNet分類任務(wù)超過谷歌MobileNet
如此思路設(shè)計(jì)出來的神經(jīng)網(wǎng)絡(luò)架構(gòu),性能到底如何?研究團(tuán)隊(duì)從各個(gè)方面驗(yàn)證。
首先,在CIFAR-10數(shù)據(jù)集上,他們將Ghost模塊用在VGG-16和ResNet-56架構(gòu)中,與幾個(gè)代表性的最新模型進(jìn)行了比較。
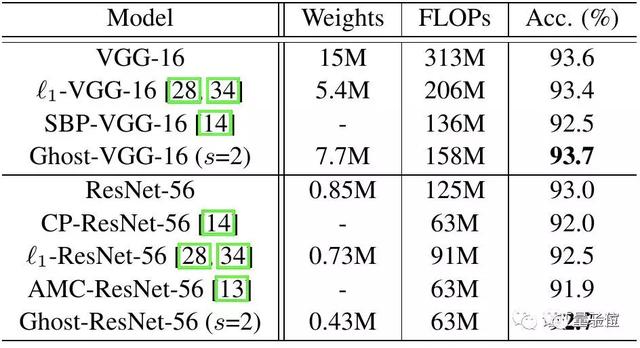
Ghost-VGG-16 ( s=2)以最高的性能(93.7%)勝過競(jìng)爭(zhēng)對(duì)手,但算力消耗(FLOPs)明顯減少。在比VGG-16小得多的ResNet-56上,基于Ghost模塊的模型,將計(jì)算量降低一半,還能獲得可比的精度。
在論文中,他們提供了Ghost模塊生成的特征圖。下圖展示了Ghost-VGG-16的第二層特征,左上方的圖像是輸入,左紅色框中的特征圖來自初始卷積,而右綠色框中的特征圖是經(jīng)過廉價(jià)深度變換后的幻影特征圖。

研究團(tuán)隊(duì)表示,盡管生成的特征圖來自原始特征圖,但它們之間確實(shí)存在顯著差異,這意味著生成的特征足夠靈活,可以滿足特定任務(wù)的需求。
其次,在ImageNet數(shù)據(jù)集的分類任務(wù)上,他們測(cè)試了整個(gè)神經(jīng)網(wǎng)絡(luò)架構(gòu)的性能,衡量的指標(biāo),是ImageNet驗(yàn)證集上single crop的top-1的性能。
下圖展示了GhostNet與現(xiàn)有最優(yōu)秀的幾種小型網(wǎng)絡(luò)結(jié)構(gòu)的對(duì)比,參賽選手包括MobileNet系列、ShuffleNet系列、ProxylessNAS、FBNet、MnasNet等。
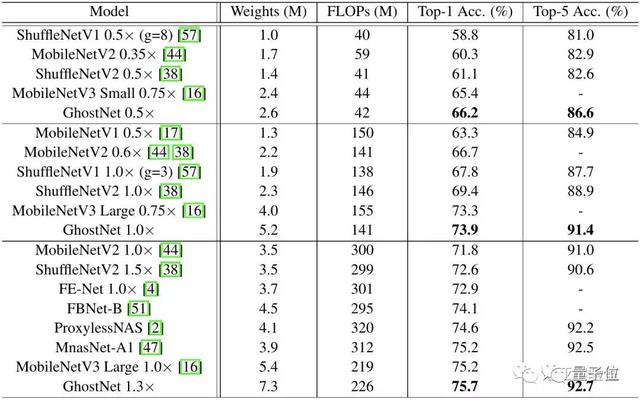
模型分為3個(gè)級(jí)別的計(jì)算復(fù)雜性,即~50,~150和200-300MFLOPs。通常FLOPs較大,這些小型網(wǎng)絡(luò)的準(zhǔn)確性會(huì)更高——表明了它們的有效性。
GhostNet在各種計(jì)算復(fù)雜度級(jí)別上始終優(yōu)于其他競(jìng)爭(zhēng)對(duì)手。研究團(tuán)隊(duì)解釋稱,這主要是因?yàn)镚hostNet在利用計(jì)算資源生成特征圖方面效率更高。
由于GhostNet是為移動(dòng)設(shè)備設(shè)計(jì),他們還使用TFLite工具,遵循MobileNet中的常用設(shè)置,使用Batch size為1的單線程模式,在基于ARM的手機(jī)(華為P30 Pro)上進(jìn)一步測(cè)量GhostNet的實(shí)際推理速度,并與其他模型進(jìn)行比較。
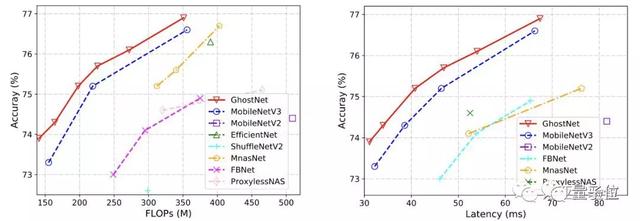
如上圖所示,與具有相同延遲的MobileNetV3相比,GhostNet大約提高了0.5%的top-1的準(zhǔn)確性,另一方面GhostNet需要更少的運(yùn)行時(shí)間來達(dá)到相同的精度。
例如,精度為75.0%的GhostNet僅具有40毫秒的延遲,而精度類似的MobileNetV3大約需要46毫秒來處理一張圖像。
因此,研究團(tuán)隊(duì)表示,GhostNet總體上勝過其他最新模型,例如谷歌MobileNet系列,ProxylessNAS,F(xiàn)BNet和MnasNet等等。
華為諾亞方舟實(shí)驗(yàn)室研究成果
這一研究的核心作者,主要來自于華為諾亞實(shí)驗(yàn)室。
第一作者是韓凱,此前研究機(jī)構(gòu)為北京大學(xué)。第二作者是王云鶴,同樣畢業(yè)于北京大學(xué)。第三位作者是田奇,諾亞方舟實(shí)驗(yàn)室首席計(jì)算機(jī)視覺科學(xué)家,也是這篇稿件的通訊作者。
這篇論文,是華為計(jì)算機(jī)視覺方向的最新研究成果之一。
此前在CVPR 2020年放榜時(shí),王云鶴就曾在知乎上透露,其團(tuán)隊(duì)一共有7篇論文被收錄。
他說,這些是他們小組辛辛苦苦攢了大半年的工作。emmm…
如果你對(duì)這一研究感興趣,可以收好下面的傳送門:
論文地址:
https://arxiv.org/abs/1911.11907
項(xiàng)目開源地址:
https://github.com/huawei-noah/ghostnet