GNMT-谷歌的神經網絡翻譯系統
一、前言
2016年9月份,谷歌發布了基于神經網絡的翻譯系統(GNMT),并宣稱GNMT在多個主要語言對的翻譯中將翻譯誤差降低了55%-85%以上,并將此翻譯系統的技術細節在論文(
)在展示,在閱讀之后收益匪淺。
二、概要
一般來說,NMT【神經網絡翻譯系統】通常會含用兩個RNN【遞歸神經網絡】,一個用來接受輸入文本,另一個用來產生目標語句,與此同時,還會引入當下流行的注意力機制【attention mechanism】使得系統處理長句子時更準確高效。但谷歌認為,通常這樣的神經網絡系統有三個弱點:
- 訓練速度很慢并且需要巨大的計算資源,由于數量眾多的參數,其翻譯速度也遠低于傳統的基于短語的翻譯系統【PBMT】。
- 對罕見詞的處理很無力,而直接復制原詞在很多情況下肯定不是一個好的解決方法。
- 在處理長句子的時候會有漏翻的現象。
而且GNMT致力于解決以上的三個問題,在GNMT中,RNN使用的是8層(實際上Encoder是9層,輸入層是雙向LSTM。)含有殘差連接的神經網絡,殘差連接可以幫助某些信息,比如梯度、位置信息等的傳遞。同時,attention層與decoder的底層以及encoder的頂層相連接,如圖:
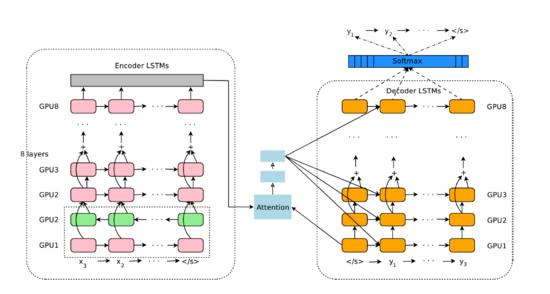
GNMT結構圖
- 為了解決翻譯速度問題,谷歌在翻譯過程中使用了低精度的算法(將模型中的部分參數限制為8bit)以及使用了TPU。
- 為了更好的處理低詞頻的詞,谷歌在輸入和輸出中使用了sub-word units也叫wordpieces,(比如把’higher‘拆分成‘high’和‘er’,分別進行處理)
*在beamsearch中,谷歌加入了長度規范化和獎勵懲罰(coverage penalty)使對翻譯過程中產生的長度不同的句子處理更高效并且減少模型的漏翻。
在進行了這么多改進之后,谷歌宣稱,在英-法,英-中,英-西等多個語對中,錯誤率跟之前的PBMT系統相比降低了60%,并且接近人類的平均翻譯水平。
接下來就詳細的看一下神奇的GNMT模型的細節。
三、模型結構
如上圖所示,GNMT和通常的模型一樣,擁有3個組成部分 -- 一個encoder,一個decoder,和一個attention network 。encoder將輸入語句變成一系列的向量,每個向量代表原語句的一個詞,decoder會使用這些向量以及其自身已經生成的詞,生成下一個詞。encoder和decoder通過attention network連接,這使得decoder可以在產生目標詞時關注原語句的不同部分。
此外,如我們所想,要使翻譯系統有一個好的準確率,encoder和decoder的RNN網絡都要足夠深,以獲取原句子和目標語句中不容易被注意的細節,在谷歌的實驗中,沒增加一層,會使PPL降低約10%。
關于模型中的attention機制,采用了如下的公式來計算:
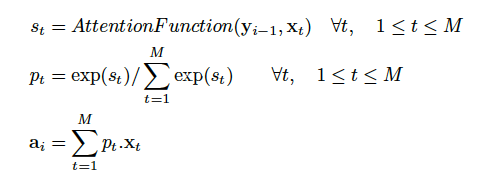
attention的公式
其實在此我有一個疑問,這里***的a i 是一個向量呢?還是一個標量(一個數值)。從式中看似乎是一個標量,但我在之前理解的是attention是一個跟輸入語句單詞數量等長的向量。
3.1殘差連接
如上面提到的,多層堆疊的LSTM網絡通常會比層數少的網絡有更好的性能,然而,簡單的錯層堆疊會造成訓練的緩慢以及容易受到剃度爆炸或梯度消失的影響,在實驗中,簡單堆疊在4層工作良好,6層簡單堆疊性能還好的網絡很少見,8層的就更罕見了,為了解決這個問題,在模型中引入了殘差連接,如圖,
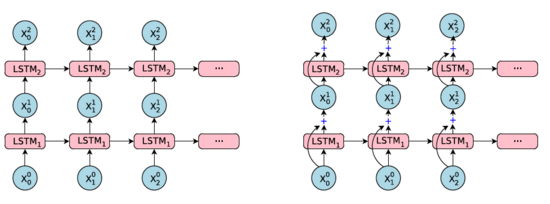
殘差連接示意圖
將第i層的輸入與第i層LSTM的隱狀態一起,作為第i+1層LSTM的輸入,
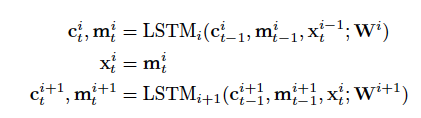
沒有引入殘差連接的LSTM示意圖
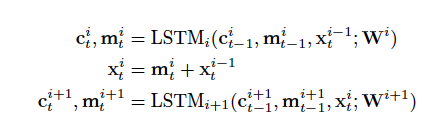
引入殘差連接的LSTM示意圖
3.2Encoder的***層雙向LSTM
一句話的譯文所需要的關鍵詞可能在出現在原文的任何位置,而且原文中的信息可能是從右往左的,也可能分散并且分離在原文的不同位置,因為為了獲得原文更多更全面的信息,雙向RNN可能是個很好的選擇,在本文的模型結構中,只在Encoder的***層使用了雙向RNN,其余的層仍然是單向RNN。
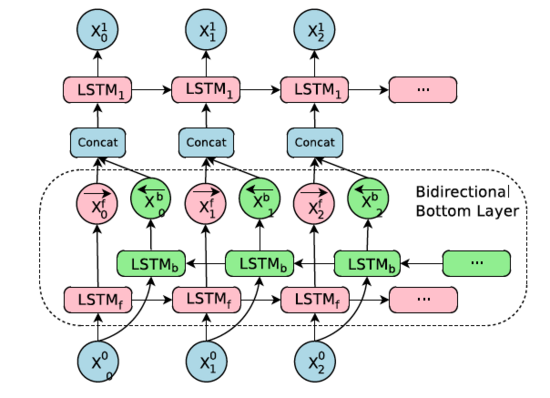
Bi-directions RNN示意圖
可以看到,粉色的LSTM從左往右的處理句子,綠色的LSTM從右往左,二者的輸出先是連接,然后再傳給下一層的LSTM。
3.3模型的平行訓練
這一部分主要是介紹模型在訓練過程中一些加速的方法。
谷歌同時采用了數據平行和模型平行兩種方式以加速訓練,數據平行很直接,就是把模型復制并部署n份,每份的參數是共享的,每份訓練時都以Batch的形式訓練,即同時訓練batch-size句話。在谷歌實驗中,n通常是10,而batch-size通常是128,然后用Adam和SGD的方法來更新參數。
除了數據平行,實驗中還采用了模型平行,即,將每一層網絡部署在一個GPU上,如最上方的圖所示,這樣在Encoder的***層雙向RNN計算完之后,下一時間步不需要等本時間步完全運行完就可以開始,并行計算加速了訓練速度。
而之所以不在每一層都是用雙向RNN是因為,如果這樣會大幅度降低訓練速度,因為其只能使用兩個GPU,一個作前向信息處理,一個作后向的信息處理,降低平行計算的效率。
在attention的部分,將encoder的輸出層與decoder的底層對齊(我的理解應該是輸出的tensor緯度一致)來***化平行計算的效率。(具體是什么原理我還沒理解太明白)。
四、數據預處理
神經網絡翻譯系統在運行過程中通常有一個字數有限的字典,而可能遇到的詞是無數的,這就可能造成OOV(out-of-vocabulary)問題,由于這些未知詞通常是日期,人名,地名等,所以一個簡單的方法就是直接復制這些詞,顯然在處理非人名等詞時著不是***的解決方案,在谷歌的模型中,采用更好的wordpiece model,也叫sub-word units,比如在“Turing’s major is NLP .”一句經過WPM模型處理之后應該是"Turing ‘s major is NLP ." 另外為了直接復制人名等詞,使source language和target language共享wordpiece model,WPM在單詞的靈活性和準確性上取得了一個很好的均衡,也在翻譯有更好的準確率(BLEU)和更快的翻譯速度。
五、訓練標準
通常來說,在N對語句對中,訓練的目標是使下式***化:
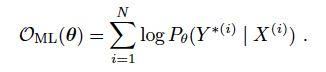
log probabilities of the groud-truth outputs given the corresponding inputs
但這里面有一個問題,翻譯中的BLEU值中不能反映對單句翻譯質量好壞的獎懲,進一步,因為模型在訓練過程中從來沒有見過錯誤的譯句,當模型有一個較高的BLEU值時,那些錯誤的句子仍然會獲得較高的概率,所以上式不能明確的對翻譯中的錯誤句子進行懲罰。(對原論文中此處不是完全理解,存疑。)
因此需要對模型有進一步的refinement,但BLEU值是針對兩個語料庫進行的評測標準,在對單句的評測上效果并不理想,所以谷歌提出了GLEU值,GLEU值的大體意思就是分別計算目標語句和譯句的n-grams,(n = 1,2,3,4)數量,然后計算兩個集合的交集的大小與原集大小的比值,取較小值。
我用python實現了一下GLEU值的計算,代碼如下:
- def get_ngrams(s,maxn):
- ngrams = {}
- size = 0
- for n in range(1,maxn+1):
- for i in range(0,len(s)):
- for j in range(i+1,min(i+n+1,len(s)+1)):
- ngram = ''
- for word in s[i:j]:
- ngram += word
- ngram += ' '
- ngram = ngram.strip()
- if ngram not in ngrams:
- ngrams[ngram] = 1
- size += 1
- return size,ngrams
- def get_gleu(orig,pred,n=4):
- orig_ = orig.split(' ')
- pred_ = pred.split(' ')
- n_orig,ngrams_orig = get_ngrams(orig_,n)
- n_pred,ngrams_pred = get_ngrams(pred_,n)
- count_match = 0
- for v in ngrams_orig:
- if v in ngrams_pred:
- count_match += 1
- return min(count_match/n_orig,count_match/n_pred)
所以,refinement之后模型的評測標準變成了下式:
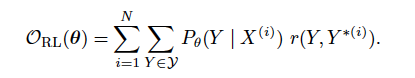
refinement maximum-likelihood
r(Y, Y (i))就是GLEU值的計算部分。GLEU克服了BLEU在單句評測上的缺點,在本實驗中,可以和BLEU值可以很好的共同工作。
為了進一步使訓練穩定,谷歌對訓練標準作了一個線性的結合,也就是下式:
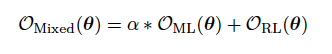
Mixed maximum-likelihood
α在訓練中去0.017.
在實際的訓練過程中,先使用O ml 的標準訓練使模型收斂,然后使用O mixd 的標準進一步提升模型的表現。
六、可量化的模型和翻譯過程中的量化
(坦白的說,我并不知道原文中 Quantizable Model and Quantized Inference 應該怎么翻譯更好。)
這一部分主要講的是,由于模型較深且計算量較大,在翻譯過程會產生一些問題,所以谷歌在不影響模型收斂和翻譯效果的前提下,采取了一系列的優化措施。
帶有殘差連接的LSTM網絡,有兩個值是會不斷傳遞計算的,在時間方向上傳遞的c i t 和在深度方向上傳遞的x i t ,在實驗中過程我們發現這些值都是非常小的,為了減少錯誤的累積,所以在翻譯的過程中,明確的這些值限制在[-δ,δ]之間,因此原LSTM的公式調整如下:
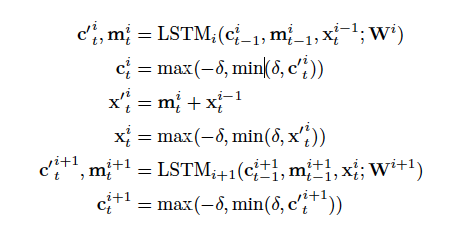
6.1 modified equation
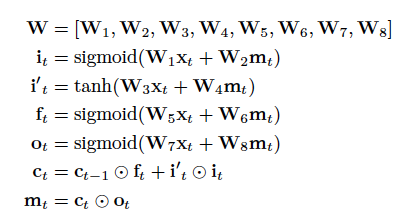
6.2 完整的LSTM計算邏輯
在翻譯的過程中,谷歌將6.1和6.2式中所有浮點數運算替代為8位或16位定點整數運算,其中的權重W像下式一樣改用8位整數表示:
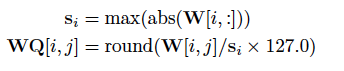
權重W的調整
所有的c i t 和x i t 限制在[-δ,δ]之間且改用16位整數表示。
在6.2中的矩陣乘法(比如W 1 x t )改用8位定點整數乘法,而其他的所有運算,比如sigmoid,tanh,點乘,加法等,改用16位整數運算。
假設decoder RNN的輸出是y t ,那在softmax層,概率向量p t 改為這樣計算:
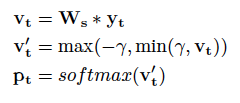
修改后的概率向量計算公式
將 logit v t ' 限制在[-γ,γ]之間且權重W s 和6.2式中的權重W同樣使用8位整數表示并在運算過程中使用8位矩陣乘法。
但在softmax層和attention層不采取量化措施。
值得一提的是,除了將c i t 和x i t 限制在[-δ,δ]和將logit v t ' 限制在[-γ,γ],在 訓練過程 中一直使用的是全精度的浮點數。其中γ取25.0,δ在訓練剛開始取8.0然后逐漸變為1.0 。( 在翻譯時,δ取1.0 。 )
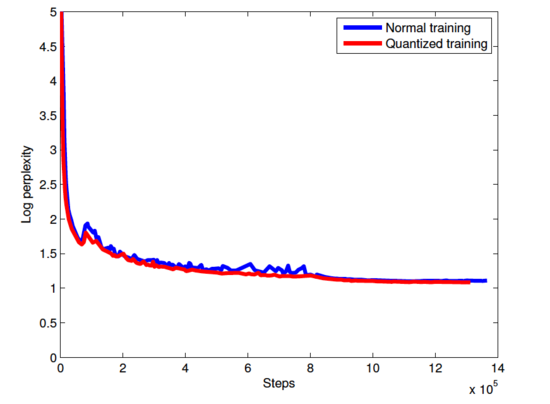
Log perplexity vs. steps
紅線代表采用了量化措施的訓練過程,藍線代表普通的訓練,可以看到將一些值限制在一定范圍內作為額外的規劃化措施可以改善模型的質量。
七、Decoder
在翻譯的過程中,使用了常規的beam search算法,但引入了兩個重要的優化方案,即GNMT中的α和β值。
- α值的作用是對譯句進行長度規范化,因為選取一個句子的可能性是由劇中每個詞的概率取log后相加得到的,這些個對數概率都是負值,因此某種程度上,長句會取得更小的對數概率,這顯然是不合理的,因此需要對譯句進行長度規劃化。
- β值的作用是促使模型更好的翻譯全句,不漏翻。
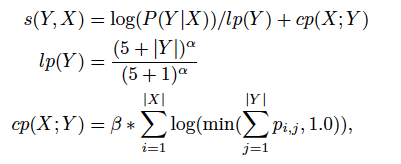
關于α和β值適用的公式
其中s(Y,X)代表譯文最終獲得的分數,p i j 表示在翻譯第j個詞時其對應第i個詞的attention值。
谷歌在文中還提到兩種優化方法:
Firstly, at each step, we only consider tokens that have local scores that are
not more than beamsize below the best token for this step. Secondly, after a normalized best score has
been found according to equation 14, we prune all hypotheses that are more than beamsize below the best
額,其實我沒看懂這跟常規的beam search算法有什么不同,望大神指點。。。
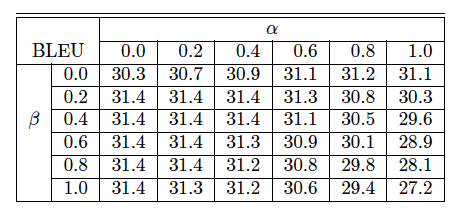
在En-Fr語料庫上,不同α和β值對BLEU值的影響
當α和β值取0時相當于不做長度規劃化和覆蓋范圍懲罰,算法退回到最原始的beam search算法,值得一提的是,得到上述BLEU的模型并沒有進行只使用了ML進行訓練,沒有使用RL優化。因為RL refinement已經促使模型不漏翻,不過翻。
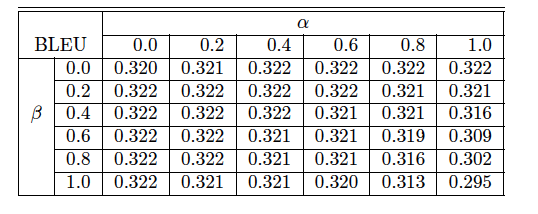
在En-Fr語料庫上先用ML優化在用RL優化的到的BLEU值與上圖的比較
在谷歌實驗中,α=0.2和β=0.2,但在我們的實驗中,在中英翻譯中,還是α=0.6~1和β=0.2~0.4會取得更好的效果
實驗過程以及實驗結果
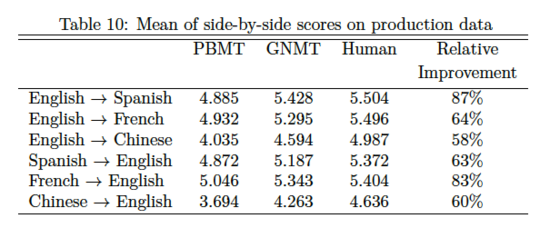
實驗結果對比
模型部分基本介紹完了,剩下的第八部分關于實驗以及實驗結果先貼張圖,會繼續不定時補充,下一篇文章應該會介紹一下Facebook發布并開源的宣稱比GNMT更好更快的FairSeq模型...
論文中提到但未使用的方法
另有一種方法處理OOV問題是將罕見詞標記出來,比如,假設 Miki 這個詞沒有出現在詞典中,經過標記后,變成<B> M <M> i <M> k <E> i ,這樣在翻譯過程中,將罕見詞替換為特殊符號。