













谷歌大腦新算法,不折騰TPU就能加快AI訓(xùn)練速度
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
訓(xùn)練神經(jīng)網(wǎng)絡(luò),硬件要過硬?現(xiàn)在谷歌提出強有力反駁。
GPU和像谷歌TPU這樣的硬件加速器大大加快了神經(jīng)網(wǎng)絡(luò)的訓(xùn)練速度,推助AI迅速成長,在各個領(lǐng)域發(fā)揮超能力。
然而,硬件發(fā)展再迅速,也總有力有不逮的時候。
比如,由于芯片的架構(gòu)方式,像數(shù)據(jù)預(yù)處理這樣的訓(xùn)練pipeline早期階段并不會受益于硬件加速器的提升。

谷歌大腦的科學(xué)家們可不希望看到算法掣肘硬件,于是他們研究出了一種名為“數(shù)據(jù)回放(Data Echoing)”的新技術(shù)。
加速神經(jīng)網(wǎng)絡(luò)訓(xùn)練速度,這回不靠折騰半導(dǎo)體。
Data Echoing的黑科技
新的加速方法的核心在于減少訓(xùn)練pipeline早期階段消耗的時間。
按照經(jīng)典的訓(xùn)練pipeline,AI系統(tǒng)先讀取并解碼輸入數(shù)據(jù),然后對數(shù)據(jù)進行混洗,應(yīng)用轉(zhuǎn)換擴充數(shù)據(jù),然后再將樣本收集到批處理中,迭代更新參數(shù)以減少誤差。
而Data Echoing是在pipeline中插入了一個階段,在參數(shù)更新之前重復(fù)前一階段的輸出數(shù)據(jù),理論回收空閑算力。
如果重復(fù)數(shù)據(jù)的開銷可以忽略不計,并且echoing任意側(cè)的階段都是并行執(zhí)行的,那么數(shù)據(jù)回放完成一個上游步驟和e個下游步驟的平均時間就是:
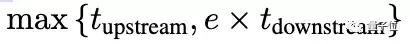
假設(shè)上游步驟花費的時間大于等于下游步驟花費的時間,你會發(fā)現(xiàn)附加的下游步驟是“免費”的,因為它們利用了空閑的下游容量。

data echoing縮短訓(xùn)練時間的關(guān)鍵在于上游步驟和下游步驟之間的權(quán)衡。
一方面,重復(fù)數(shù)據(jù)的價值可能會比新數(shù)據(jù)的價值低,那么data echoing就需要更多的下游SGD(隨機梯度下降)更新來達到預(yù)期性能。
另一方面,data echoing中每個下游步驟僅需要1/e個上游步驟。
如果下游步驟因回放因子而增加的數(shù)量比e小,那么上游步驟的總數(shù)就會減少,總的訓(xùn)練時間也就減少了。
需要注意的是,有兩個因素會影響在不同插入點處data echoing的表現(xiàn):
在批處理前回放(echoing)
在批處理之前回放意味著數(shù)據(jù)是在樣本級別而不是批處理級別重復(fù)和混洗的,這增加了臨近批次不同的可能性,代價是批次內(nèi)可能會有重復(fù)的樣本。
在數(shù)據(jù)擴增前回放
在數(shù)據(jù)增強之前進行回放,重復(fù)數(shù)據(jù)就可能以不同的方式轉(zhuǎn)換,這樣一來重復(fù)數(shù)據(jù)就會更像新數(shù)據(jù)。
效果如何
研究團隊對這一方法進行了實驗,他們選擇了兩個語言模型任務(wù),兩個圖像識別任務(wù)和一個對象檢測任務(wù),AI模型都是用開源數(shù)據(jù)集訓(xùn)練的。
實驗中,“新”訓(xùn)練樣本(訓(xùn)練樣本從磁盤中被讀取出來,就算做一個新的樣本)的數(shù)目達到指定目標(biāo)的時間就算作訓(xùn)練的時長。同時,研究人員也會調(diào)查data echoing是否減少了所需的樣本數(shù)量。
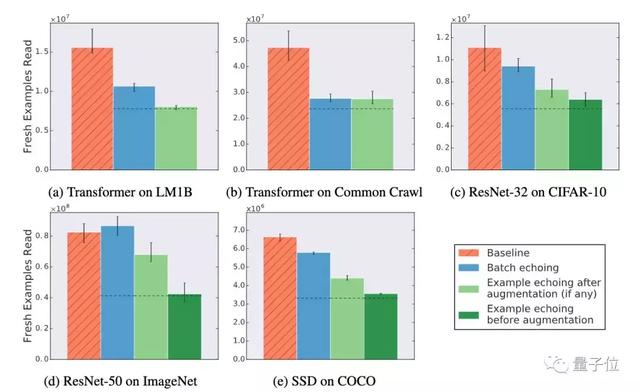
除了用ImageNet訓(xùn)練的ResNet-50,data echoing的效率都比基線方法效率高。并且更早地在pipeline中插入echoing,訓(xùn)練所需的新樣本會更少。
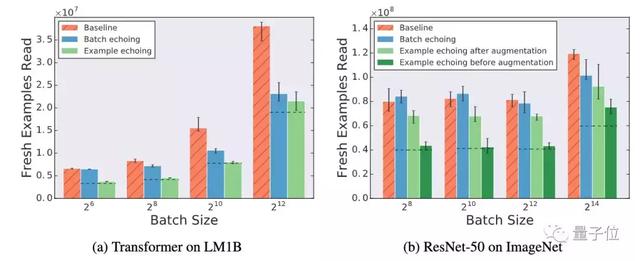
而隨著批量大小的增加,data echoing相對于基線方法的改進會更加明顯。
摩爾定律的黃昏
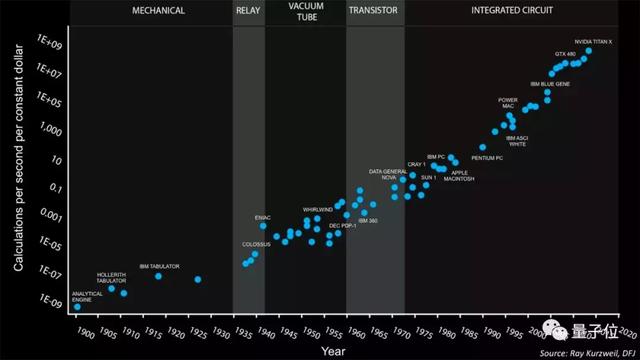
隨著摩爾定律走向終結(jié),要依靠芯片制造工藝的突破來實現(xiàn)人工智能算力的提升越來越困難,雖然有硬件加速器加持,但CPU這樣的通用處理器依然成為了神經(jīng)網(wǎng)絡(luò)訓(xùn)練速度進一步提升的攔路虎。
另辟蹊徑,以算法性能來突破重圍,正在成為New sexy。
論文地址:https://arxiv.org/abs/1907.05550
























