遷移學(xué)習(xí):數(shù)據(jù)不足時如何深度學(xué)習(xí)
使用深度學(xué)習(xí)技術(shù)解決問題的過程中,最常見的障礙在于訓(xùn)練模型過程中所需的海量數(shù)據(jù)。需要如此多的數(shù)據(jù),原因在于機(jī)器在學(xué)習(xí)的過程中會在模型中遇到大量參數(shù)。在面對某一領(lǐng)域的具體問題時,通常可能無法得到構(gòu)建模型所需規(guī)模的數(shù)據(jù)。然而在一個模型訓(xùn)練任務(wù)中針對某種類型數(shù)據(jù)獲得的關(guān)系也可以輕松地應(yīng)用于同一領(lǐng)域的不同問題,這就是所謂的遷移學(xué)習(xí)。
我認(rèn)為實(shí)現(xiàn)人工智能的難度無異于建造火箭。需要有一個強(qiáng)大的引擎,還有大量的燃料。如果空有強(qiáng)大的引擎但缺乏燃料,火箭肯定是無法上天的。如果只有一個單薄的引擎,有再多燃料也無法起飛。如果要造火箭,強(qiáng)大的引擎和大量燃料是必不可少的。以此來類比深度學(xué)習(xí)的話,深度學(xué)習(xí)引擎可以看作火箭引擎,而我們?yōu)樗惴ㄌ峁┑暮A繑?shù)據(jù)可以看作是燃料。 — Andrew Ng
最近深度學(xué)習(xí)技術(shù)突然開始大肆流行,并在語言翻譯、玩策略游戲,以及無人駕駛汽車等涉及到數(shù)百萬數(shù)據(jù)量的領(lǐng)域取得了醒目的成果。使用深度學(xué)習(xí)技術(shù)解決問題的過程中,最常見的障礙在于訓(xùn)練模型過程中所需的海量數(shù)據(jù)。需要如此多的數(shù)據(jù),原因在于機(jī)器在學(xué)習(xí)的過程中會在模型中遇到大量參數(shù)。
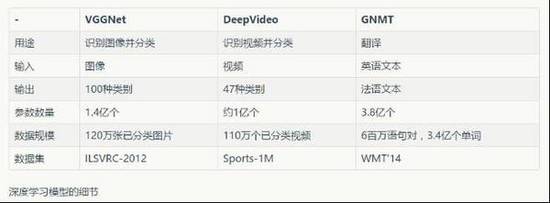
例如這些模型中常見的參數(shù)數(shù)量范圍包括:
深度學(xué)習(xí)
神經(jīng)網(wǎng)絡(luò)(即深度學(xué)習(xí))是一種分層式結(jié)構(gòu),但又能堆疊在一起(就像樂高積木)。
深度學(xué)習(xí)技術(shù)其實(shí)就是一種大規(guī)模神經(jīng)網(wǎng)絡(luò),我們可以將這種網(wǎng)絡(luò)看作一種流程圖,數(shù)據(jù)從一端進(jìn)入,相互引用/了解后從另一端輸出。我們還可以將神經(jīng)網(wǎng)絡(luò)拆分成多個部分,從任何一部分中得到自己需要的推理結(jié)果。也許無法得到有意義的結(jié)果,但依然可以這樣做,例如Google DeepDream就是這樣做的。
規(guī)模(模型) ∝ 規(guī)模(數(shù)據(jù)) ∝ 復(fù)雜度(問題)
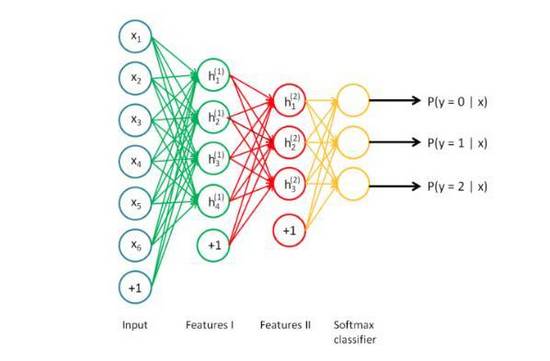
在模型的規(guī)模和所需數(shù)據(jù)量的規(guī)模之間存在一種有趣的近似于線性的關(guān)系。基本推論在于,對于特定的問題(例如類別的數(shù)量),模型必須足夠大,以便得到數(shù)據(jù)之間的關(guān)系(例如圖片中的材質(zhì)和形狀,文本中的語法,以及語音中的音素)。模型中的前序?qū)涌梢宰R別所輸入內(nèi)容中不同組成之間的高級別關(guān)系(例如邊緣和模式),后續(xù)層可以識別有助于最終做決策所需的信息,這些信息通常有助于區(qū)分不同的結(jié)果。因此如果問題的復(fù)雜度較高(例如圖像分類),所需的參數(shù)數(shù)量和數(shù)據(jù)量就會非常大。
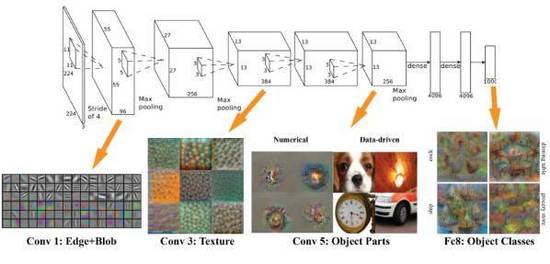
AlexNet在每個環(huán)節(jié)“看到”的內(nèi)容
遷移學(xué)習(xí)來了!
在面對某一領(lǐng)域的具體問題時,通常可能無法得到構(gòu)建模型所需規(guī)模的數(shù)據(jù)。然而在一個模型訓(xùn)練任務(wù)中針對某種類型數(shù)據(jù)獲得的關(guān)系也可以輕松地應(yīng)用于同一領(lǐng)域的不同問題。這種技術(shù)也叫做遷移學(xué)習(xí)(Transfer Learning)。
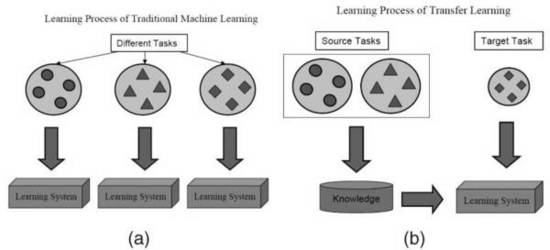
Qiang Yang、Sinno Jialin Pan,“A Survey on Transfer Learning”,IEEE Transactions on Knowledge & Data Engineering,vol. 22, no. , pp. 1345–1359, October 2010, doi:10.1109/TKDE.2009.191
遷移學(xué)習(xí)就像是一個沒人愿意保守的***機(jī)密。盡管業(yè)內(nèi)人人皆知,但外界毫不知情。
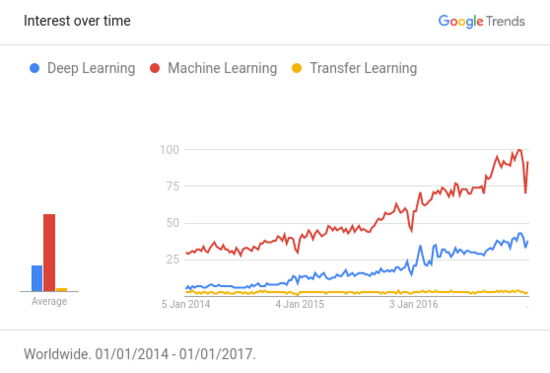
谷歌搜索中,機(jī)器學(xué)習(xí)、深度學(xué)習(xí),以及遷移學(xué)習(xí)三個關(guān)鍵字的搜索趨勢變化
根據(jù)Awesome — Most Cited Deep Learning Papers所公布的深度學(xué)習(xí)領(lǐng)域最主要的論文統(tǒng)計,超過50%的論文使用了某種形式的遷移學(xué)習(xí)或預(yù)訓(xùn)練。對于資源(數(shù)據(jù)和計算能力)有限的人,遷移學(xué)習(xí)技術(shù)的重要性與日俱增,然而這一概念尚未得到應(yīng)有程度的社會影響。最需要這種技術(shù)的人甚至至今都不知道這種技術(shù)的存在。
如果深度學(xué)習(xí)是圣杯,數(shù)據(jù)是守門人,那么遷移學(xué)習(xí)就是大門鑰匙。
借助遷移學(xué)習(xí)技術(shù),我們可以直接使用預(yù)訓(xùn)練過的模型,這種模型已經(jīng)通過大量容易獲得的數(shù)據(jù)集進(jìn)行過訓(xùn)練(雖然是針對完全不同的任務(wù)進(jìn)行訓(xùn)練的,但輸入的內(nèi)容完全相同,只不過輸出的結(jié)果不同)。隨后從中找出輸出結(jié)果可重用的層。我們可以使用這些層的輸出結(jié)果充當(dāng)輸入,進(jìn)而訓(xùn)練出一個所需參數(shù)的數(shù)量更少,規(guī)模也更小的網(wǎng)絡(luò)。這個小規(guī)模網(wǎng)絡(luò)只需要了解特定問題的內(nèi)部關(guān)系,同時已經(jīng)通過預(yù)培訓(xùn)模型學(xué)習(xí)過數(shù)據(jù)中蘊(yùn)含的模式。通過這種方式,即可將經(jīng)過訓(xùn)練檢測貓咪的模型重新用于再現(xiàn)梵高的畫作。
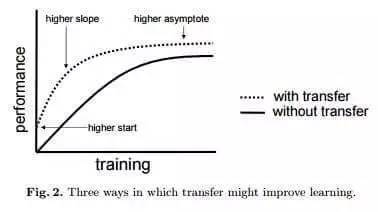
遷移學(xué)習(xí)技術(shù)的另一個重大收益在于可以對模型進(jìn)行完善的“通用化”。大型模型往往會與數(shù)據(jù)過度擬合(Overfit),例如建模所用數(shù)據(jù)量遠(yuǎn)遠(yuǎn)超過隱含的現(xiàn)象數(shù)量,在處理未曾見過的數(shù)據(jù)時效果可能不如測試時那么好。由于遷移學(xué)習(xí)可以讓模型看到不同類型的數(shù)據(jù),因此可以習(xí)得更出色的底層規(guī)則。
過度擬合,更像是學(xué)習(xí)過程中的死記硬背。 — James Faghmous
遷移學(xué)習(xí)可減小數(shù)據(jù)量
假設(shè)想要終結(jié)裙子到底是藍(lán)黑色還是白金色的爭議,首先需要收集大量已獲證實(shí)是藍(lán)黑色和白金色的裙子圖片。如果要使用類似上文提到的方式(包含1.4億個參數(shù)!)自行構(gòu)建一個準(zhǔn)確的模型并對其進(jìn)行訓(xùn)練,至少需要準(zhǔn)備120萬張圖片,這基本上是無法實(shí)現(xiàn)的。這時候可以試試遷移學(xué)習(xí)。
如果使用遷移學(xué)習(xí)技術(shù),訓(xùn)練所需的參數(shù)數(shù)量計算方式如下:
參數(shù)的數(shù)量 = [規(guī)模(輸入) + 1] * [規(guī)模(輸出) + 1]= [2048+1]*[1+1]~ 4098 個參數(shù)
所需參數(shù)數(shù)量由1.4*10⁸個減少至4*10⊃3;個,降低了五個數(shù)量級!只要收集不到100個圖片就夠了。松了口氣!
如果實(shí)在沒耐心繼續(xù)閱讀,希望立刻知道裙子的顏色,可以直接跳至本文末尾看看如何自行構(gòu)建一個這樣的模型。
遷移學(xué)習(xí)循序漸進(jìn)指南 — 使用示例進(jìn)行情緒分析
在這個示例中共有72篇影評。
62篇不包含明確的情緒,將用于對模型進(jìn)行預(yù)訓(xùn)練
8篇包含明確的情緒,將用于對模型進(jìn)行訓(xùn)練
2篇包含明確的情緒,將用于對模型進(jìn)行測試
由于只有8個包含標(biāo)簽的句子(包含明確情緒的句子),因此首先可以預(yù)訓(xùn)練模型進(jìn)行上下文預(yù)測。如果只使用這8個句子訓(xùn)練模型,準(zhǔn)確度可達(dá)50%(這樣的準(zhǔn)確度和拋硬幣差不多)。
我們將使用遷移學(xué)習(xí)技術(shù)解決這個問題,首先使用62個句子訓(xùn)練模型,隨后使用***個模型的部分內(nèi)容,以此為基礎(chǔ)訓(xùn)練出一個情緒分類器。使用隨后8個句子進(jìn)行訓(xùn)練后,用***2個句子測試得到了100%的精確度。
第1步

我們將訓(xùn)練一個對詞語之間的關(guān)系進(jìn)行建模的網(wǎng)絡(luò)。將句子中包含的一個詞語傳遞進(jìn)去,并嘗試預(yù)測該詞語出現(xiàn)在同一個句子中。在下列代碼中嵌入的矩陣其大小為vocabulary x embedding_size,其中存儲了代表每個詞語的向量(這里的大小為“4”)。
graph = tf.Graph()with graph.as_default(): train_inputs = tf.placeholder(tf.int32, shape=[batch_size]) train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1]) valid_dataset = tf.constant(valid_examples, dtype=tf.int32) with tf.device(‘/cpu:0’): embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0)) embed = tf.nn.embedding_lookup(embeddings, train_inputs) nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size))) nce_biases = tf.Variable(tf.zeros([vocabulary_size])) loss = tf.reduce_mean(tf.nn.nce_loss(nce_weights, nce_biases, embed, train_labels, num_sampled, vocabulary_size)) optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss) norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True)) normalized_embeddings = embeddings / norm valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset) similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True) init = tf.global_variables_initializer()
pretraining_model.py托管于GitHub,可查看源文件
第2步
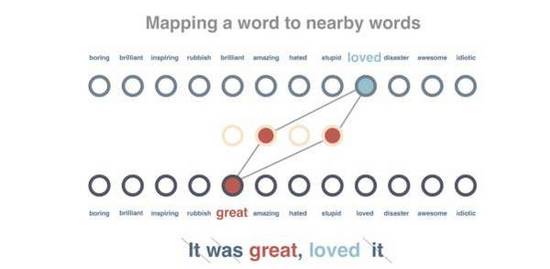
我們繼續(xù)對這個圖表進(jìn)行訓(xùn)練,讓相同上下文中出現(xiàn)的詞語可以獲得類似的向量表征。我們會對這些句子進(jìn)行預(yù)處理,移除所有停用詞(Stop word)并實(shí)現(xiàn)標(biāo)記化(Tokenizing)。隨后一次傳遞一個詞語,盡量縮短該詞語向量與周邊詞語之間的距離,并擴(kuò)大與上下文不包含的隨機(jī)詞語之間的距離。
with tf.Session(graph=graph) as session: init.run() average_loss = 0 for step in range(10001): batch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window) feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels} _, loss_val, normalized_embeddings_np = session.run([optimizer, loss, normalized_embeddings], feed_dict=feed_dict) average_loss += loss_val final_embeddings = normalized_embeddings.eval()
training_the_pretrained_model.py托管于GitHub,可查看源文件
第3步
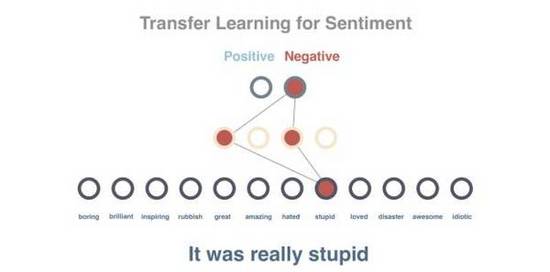
隨后我們會試著預(yù)測句子的情緒。目前已經(jīng)有10個(8個訓(xùn)練用,2個測試用)句子帶有正面和負(fù)面的標(biāo)簽。由于上一步得到的模型已經(jīng)包含從所有詞語中習(xí)得的向量,并且這些向量的數(shù)值屬性可以代表詞語的上下文,借此可進(jìn)一步簡化情緒的預(yù)測。
此時我們并不直接使用句子,而是將句子的向量設(shè)置為所含全部詞語的平均值(這一任務(wù)實(shí)際上是通過類似LSTM的技術(shù)實(shí)現(xiàn)的)。句子向量將作為輸入傳遞到網(wǎng)絡(luò)中,輸出結(jié)果為內(nèi)容為正面或負(fù)面的分?jǐn)?shù)。我們用到了一個隱藏的中間層,并通過帶有標(biāo)簽的句子對模型進(jìn)行訓(xùn)練。如你所見,雖然每次只是用了10個樣本,但這個模型實(shí)現(xiàn)了100%的準(zhǔn)確度。
input = tf.placeholder(<span class="hljs-string"><span class="hljs-string">"float"</span></span>, shape=[<span class="hljs-keyword">None</span>, x_size])
y = tf.placeholder(<span class="hljs-string"><span class="hljs-string">"float"</span></span>, shape=[<span class="hljs-keyword">None</span>, y_size])
w_1 = tf.Variable(tf.random_normal((x_size, h_size), stddev=<span class="hljs-number"><span class="hljs-number">0.1</span></span>))
w_2 = tf.Variable(tf.random_normal((h_size, y_size), stddev=<span class="hljs-number"><span class="hljs-number">0.1</span></span>))
h = tf.nn.sigmoid(tf.matmul(X, w_1))yhat = tf.matmul(h, w_2)predict = tf.argmax(yhat, dimension=<span class="hljs-number"><span class="hljs-number">1</span></span>)cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(yhat, y))updates = tf.train.GradientDescentOptimizer(<span class="hljs-number"><span class="hljs-number">0.01</span></span>).minimize(cost)sess = tf.InteractiveSession()init = tf.initialize_all_variables()sess.run(init)<span class="hljs-keyword"><span class="hljs-keyword">for</span></span> epoch <span class="hljs-keyword"><span class="hljs-keyword">in</span></span> range(<span class="hljs-number"><span class="hljs-number">1000</span></span>): <span class="hljs-keyword"><span class="hljs-keyword">for</span></span> i <span class="hljs-keyword"><span class="hljs-keyword">in</span></span> range(len(train_X)): sess.run(updates, feed_dict={<span class="hljs-string">X:</span> train_X[<span class="hljs-string">i:</span> i + <span class="hljs-number"><span class="hljs-number">1</span></span>], <span class="hljs-string">y:</span> train_y[<span class="hljs-string">i:</span> i + <span class="hljs-number"><span class="hljs-number">1</span></span>]}) train_accuracy = numpy.mean(numpy.argmax(train_y, axis=<span class="hljs-number"><span class="hljs-number">1</span></span>) == sess.run(predict, feed_dict={<span class="hljs-string">X:</span> train_X, <span class="hljs-string">y:</span> train_y})) test_accuracy = numpy.mean(numpy.argmax(test_y, axis=<span class="hljs-number"><span class="hljs-number">1</span></span>) == sess.run(predict, feed_dict={<span class="hljs-string">X:</span> test_X, <span class="hljs-string">y:</span> test_y})) print(<span class="hljs-string"><span class="hljs-string">"Epoch = %d, train accuracy=%.2f%%, test accuracy=%.2f%%"</span></span> % (epoch+<span class="hljs-number"><span class="hljs-number">1</span></span>,<span class="hljs-number"><span class="hljs-number">100.</span></span>*train_accuracy,<span class="hljs-number"><span class="hljs-number">100.</span></span>* test_accuracy))
training_the_sentiment_model.py托管于GitHub,查看源文件
雖然這只是個示例,但可以發(fā)現(xiàn)在遷移學(xué)習(xí)技術(shù)的幫助下,精確度從50%飛速提升至100%。若要查看完整范例和代碼請訪問下列地址:
https://gist.github.com/prats226/9fffe8ba08e378e3d027610921c51a78
遷移學(xué)習(xí)的一些真實(shí)案例
#### 圖像識別:
圖像增強(qiáng)
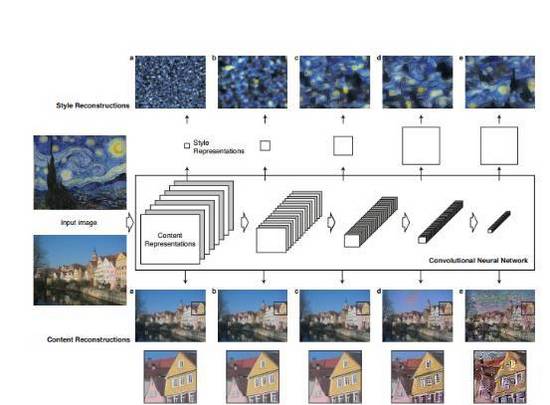
風(fēng)格轉(zhuǎn)移
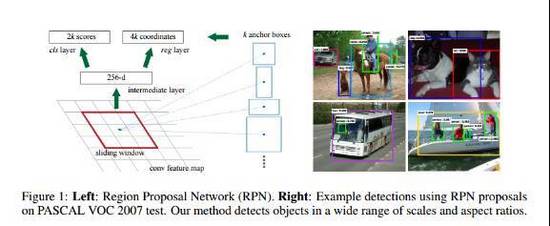
對象檢測
皮膚癌檢測
#### 文字識別:
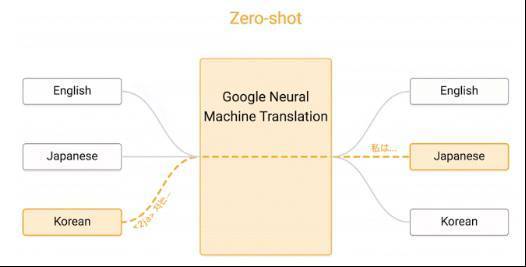
Zero Shot翻譯
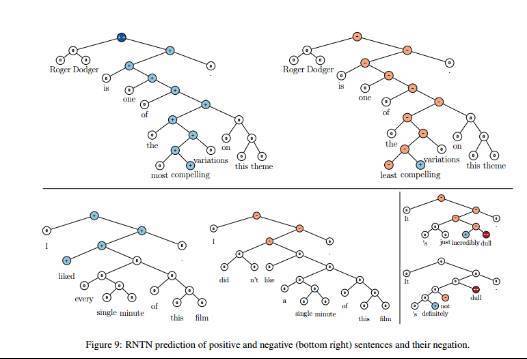
情緒分類
遷移學(xué)習(xí)實(shí)現(xiàn)過程中的難點(diǎn)
雖然可以用更少量的數(shù)據(jù)訓(xùn)練模型,但該技術(shù)的運(yùn)用有著更高的技能要求。只需要看看上述例子中硬編碼參數(shù)的數(shù)量,并設(shè)想一下要在模型訓(xùn)練完成前不斷調(diào)整這些參數(shù),遷移學(xué)習(xí)技術(shù)使用的難度之大可想而知。
遷移學(xué)習(xí)技術(shù)目前面臨的問題包括:
找到預(yù)訓(xùn)練所需的大規(guī)模數(shù)據(jù)集
決定用來預(yù)訓(xùn)練的模型
兩種模型中任何一種無法按照預(yù)期工作都將比較難以調(diào)試
不確定為了訓(xùn)練模型還需要額外準(zhǔn)備多少數(shù)據(jù)
使用預(yù)訓(xùn)練模型時難以決定在哪里停止
在預(yù)訓(xùn)練模型的基礎(chǔ)上,確定模型所需層和參數(shù)的數(shù)量
托管并提供組合后的模型
當(dāng)出現(xiàn)更多數(shù)據(jù)或更好的技術(shù)后,對預(yù)訓(xùn)練模型進(jìn)行更新
數(shù)據(jù)科學(xué)家難覓。找到能發(fā)現(xiàn)數(shù)據(jù)科學(xué)家的人其實(shí)一樣困難。 — Krzysztof Zawadzki
NanoNets讓遷移學(xué)習(xí)變得更簡單
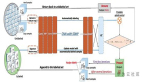
親身經(jīng)歷過這些問題后,我們開始著手通過構(gòu)建支持遷移學(xué)習(xí)技術(shù)的云端深度學(xué)習(xí)服務(wù),并嘗試通過這種簡單易用的服務(wù)解決這些問題。該服務(wù)中包含一系列預(yù)訓(xùn)練的模型,我們已針對數(shù)百萬個參數(shù)進(jìn)行過訓(xùn)練。你只需要上傳自己的數(shù)據(jù)(或在網(wǎng)絡(luò)上搜索數(shù)據(jù)),該服務(wù)即可針對你的具體任務(wù)選擇最適合的模型,在現(xiàn)有預(yù)訓(xùn)練模型的基礎(chǔ)上建立新的NanoNet,將你的數(shù)據(jù)輸入到NanoNet中進(jìn)行處理。
Nanonet對程序員是免費(fèi)的,可以用來學(xué)習(xí)和看看效果。
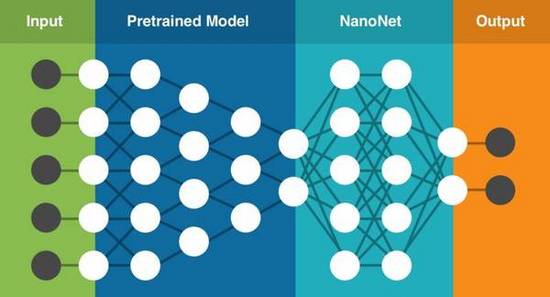
NanoNets的遷移學(xué)習(xí)技術(shù)(該架構(gòu)僅為基本呈現(xiàn))
構(gòu)建NanoNet(圖像分類)
1.在這里選擇你要處理的分類。
2.一鍵點(diǎn)擊開始搜索網(wǎng)絡(luò)并構(gòu)建模型(你也可以上傳自己的圖片)。

3.解決藍(lán)金裙子的爭議(模型就緒后我們會通過簡單易用的Web界面讓你上傳測試圖片,同時還提供了不依賴特定語言的API)。

若要開始構(gòu)建你的***個NanoNet,可訪問:www.nanonets.ai。
原文作者:Sarthak Jain,點(diǎn)擊“閱讀原文”查看英文鏈接。