如何為從1到10萬(wàn)用戶的應(yīng)用程序,設(shè)計(jì)不同的擴(kuò)展方案?
對(duì)于創(chuàng)業(yè)公司來(lái)說(shuō),有用戶注冊(cè)是好事情,但是當(dāng)用戶從零擴(kuò)展到成千上萬(wàn)之后,Web 應(yīng)用程序又該如何支持呢?
通常來(lái)說(shuō),這種情況的解決方案要么是來(lái)自突然爆發(fā)的緊急事件,要么是系統(tǒng)出現(xiàn)瓶頸進(jìn)行升級(jí)改造。雖然方式不同,但是我們也發(fā)現(xiàn)了,一個(gè)邊緣項(xiàng)目發(fā)展成高度可擴(kuò)展項(xiàng)目,其升級(jí)方案是有一些普適的“公式”可以套用,本文以 Graminsta 為例,為大家介紹當(dāng)用戶從 1 位發(fā)展到 10 萬(wàn),應(yīng)用程序如何擴(kuò)展?
1. 1 位用戶:1 臺(tái)機(jī)器
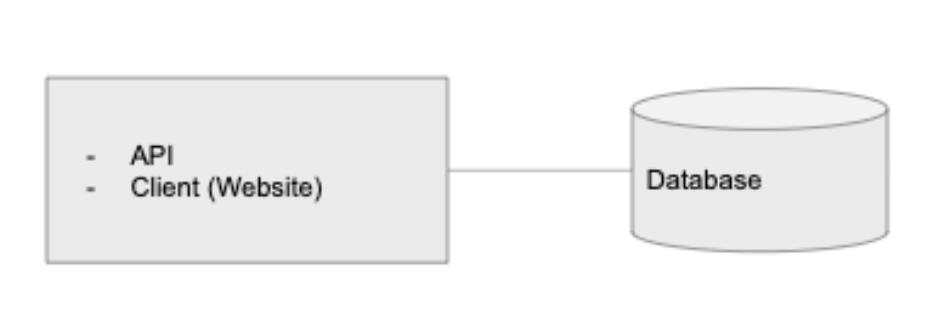
無(wú)論是網(wǎng)站還是移動(dòng)應(yīng)用,應(yīng)用程序幾乎都包括這三個(gè)關(guān)鍵組件:API、數(shù)據(jù)庫(kù)和客戶端,其中數(shù)據(jù)庫(kù)用來(lái)存儲(chǔ)持久數(shù)據(jù),API 服務(wù)于數(shù)據(jù)及與其有關(guān)的請(qǐng)求,而客戶端負(fù)責(zé)將數(shù)據(jù)呈現(xiàn)給用戶。
在現(xiàn)代應(yīng)用程序開(kāi)發(fā)中,客戶端往往會(huì)被視為一個(gè)獨(dú)立于 API 的實(shí)體,這樣一來(lái)就可以更輕松地?cái)U(kuò)展應(yīng)用程序了。
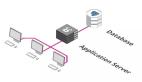
當(dāng)剛開(kāi)始構(gòu)建應(yīng)用程序時(shí),可以讓這三個(gè)組件都運(yùn)行在一個(gè)服務(wù)器上,類似于我們的開(kāi)發(fā)環(huán)境,一位工程師在同一臺(tái)計(jì)算機(jī)上運(yùn)行數(shù)據(jù)庫(kù)、API 和客戶端。
當(dāng)然,理論上我們可以把它部署到云上的單個(gè) DigitalOcean Droplet 或 AWS EC2 實(shí)例上,如下所示:

但是,當(dāng)我們的用戶未來(lái)不止 1 個(gè)的時(shí)候,其實(shí)剛開(kāi)始就應(yīng)該考慮是否要將數(shù)據(jù)層拆分出來(lái)。
2. 10 個(gè)用戶:拆分?jǐn)?shù)據(jù)層
拆分?jǐn)?shù)據(jù)層,并將其作為一個(gè)類似于 Amazon 的 RDS 或 Digital Ocean 的托管數(shù)據(jù)庫(kù)的托管服務(wù)。這樣做的話,雖然成本會(huì)比在一臺(tái)機(jī)器上或 EC2 實(shí)例上自托管高一些,但是我們可以獲得很多現(xiàn)成且方便的東西,例如多區(qū)域冗余、只讀副本、自動(dòng)備份等等。
Graminsta 現(xiàn)在的系統(tǒng)如下所示:
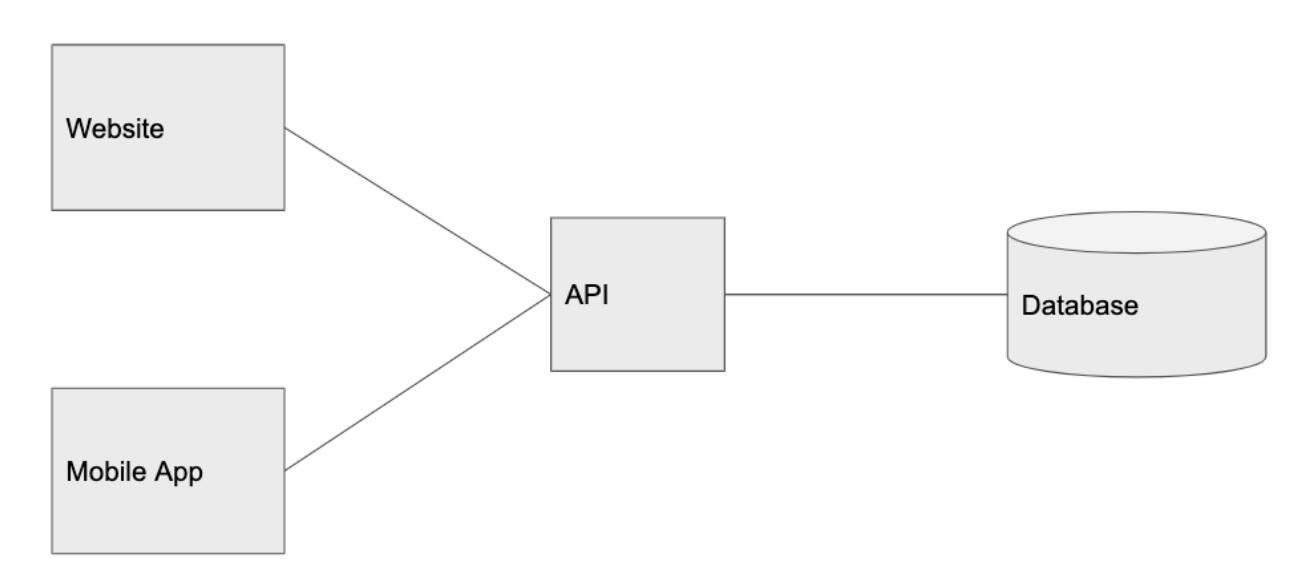
3. 100 個(gè)用戶:拆分客戶端
當(dāng)網(wǎng)站流量變得穩(wěn)定之后,就到了拆分客戶端的時(shí)候了。
需要注意的是,拆分實(shí)體是構(gòu)建可擴(kuò)展應(yīng)用程序的關(guān)鍵所在。當(dāng)系統(tǒng)中的某一部分獲得了更多流量,那么就應(yīng)該把它拆分出來(lái),根據(jù)其自身的特定流量模式來(lái)處理服務(wù)的擴(kuò)展。這也是我會(huì)把客戶端和 API 看作是相互獨(dú)立的組件的原因,這樣,我們就可以輕松為多平臺(tái)構(gòu)建產(chǎn)品,例如 web、移動(dòng) web、iOS、Android、桌面應(yīng)用、第三方服務(wù)等,它們都是使用相同 API 的客戶端。
現(xiàn)在,Graminsta 的系統(tǒng)如下所示:
4. 1000 個(gè)用戶:負(fù)載均衡器
當(dāng)新用戶越來(lái)越多,如果只有一個(gè) API 實(shí)例可能滿意滿足所有的流量,這時(shí)我們需要更多的計(jì)算能力。
這時(shí),負(fù)載均衡器該上場(chǎng)了,我們?cè)?API 前面添加一個(gè)負(fù)載均衡器,它會(huì)把流量路由到該服務(wù)的一個(gè)實(shí)例上,我們就可以進(jìn)行水平擴(kuò)展(通過(guò)添加更多運(yùn)行相同代碼的服務(wù)器來(lái)增加可以處理的請(qǐng)求數(shù)量)。
我們?cè)?web 端和 API 前面添加了一個(gè)獨(dú)立的負(fù)載均衡器,這意味著我們擁有了多個(gè)運(yùn)行 API 和 web 客戶端代碼的實(shí)例。該負(fù)載均衡器會(huì)把請(qǐng)求路由到任何一個(gè)流量最小的實(shí)例上。并且,我們還可以從中得到冗余,當(dāng)一個(gè)實(shí)例宕機(jī)(過(guò)載或崩潰)時(shí),其他實(shí)例還可以繼續(xù)運(yùn)行,響應(yīng)傳入的請(qǐng)求,而不是整個(gè)系統(tǒng)宕機(jī)。
負(fù)載均衡器還支持自動(dòng)擴(kuò)展,在流量高峰時(shí)可以增加實(shí)例的數(shù)量,當(dāng)流量低谷時(shí),減少實(shí)例數(shù)量。借助負(fù)載均衡器,API 層實(shí)際上可以無(wú)限擴(kuò)展,如果請(qǐng)求增加,我們只需要不斷增加實(shí)例就可以了。
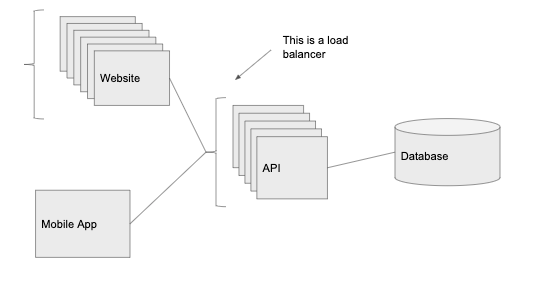
編者注:到目前為止,我們擁有的產(chǎn)品和 PaaS 公司(如 Heroku 或 AWS 的 Elastic Beanstalk)提供的開(kāi)箱即用產(chǎn)品非常類似。Heroku 把數(shù)據(jù)庫(kù)托管在單獨(dú)的主機(jī)上,用自動(dòng)擴(kuò)展來(lái)管理負(fù)載均衡器,并允許我們把 API 和 web 客戶端分開(kāi)托管。對(duì)于早期初創(chuàng)企業(yè)來(lái)說(shuō),使用 Heroku 等服務(wù)來(lái)做項(xiàng)目是一個(gè)不錯(cuò)的選擇,所有必需的、基本的東西都是開(kāi)箱即用。
5. 10000 個(gè)用戶:CDN
對(duì)于 Graminsta 來(lái)說(shuō),處理和上傳圖像為服務(wù)器帶來(lái)了很大的負(fù)擔(dān)。所以,Graminsta 選擇了使用云存儲(chǔ)服務(wù)來(lái)托管靜態(tài)內(nèi)容,例如圖像、視頻等(AWS 的 S3 或 Digital Ocean 的 Spaces),而 API 應(yīng)該避免圖像處理和圖像等業(yè)務(wù)。
另外,使用云存儲(chǔ)服務(wù),我們還可以使用 CDN,可以在遍布全球不同的數(shù)據(jù)中心自動(dòng)緩存圖像。我們的主數(shù)據(jù)中心可能托管在
我們從云存儲(chǔ)服務(wù)得到的另一樣?xùn)|西是 CDN(在 AWS,這是一個(gè)被稱為 Cloudfront 的插件,但是很多云存儲(chǔ)服務(wù)都以開(kāi)箱即用的方式提供它)。CDN 將在遍布全球不同的數(shù)據(jù)中心自動(dòng)緩存我們的圖像。
雖然我們的主數(shù)據(jù)中心可能托管在俄亥俄州,如果有人在日本對(duì)圖像發(fā)出了請(qǐng)求,那么云供應(yīng)商就會(huì)進(jìn)行復(fù)制,將其存儲(chǔ)在位于日本的數(shù)據(jù)中心,下一個(gè)請(qǐng)求該圖像的日本用戶就會(huì)很快收到圖像。
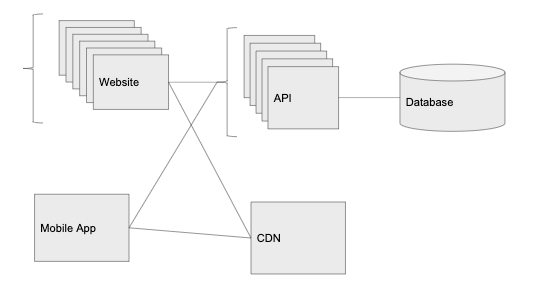
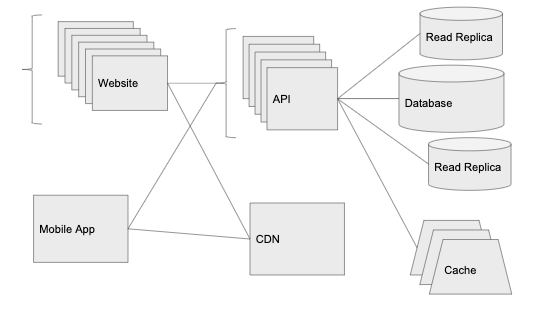
6. 10 萬(wàn)個(gè)用戶:擴(kuò)展數(shù)據(jù)層
負(fù)載均衡器在環(huán)境中添加了 10 個(gè) API 實(shí)例,使得 API 的 CPU 和內(nèi)存消耗都很低,CDN 幫助我們解決了世界各地圖像請(qǐng)求的問(wèn)題。但是現(xiàn)在,我們有一個(gè)問(wèn)題需要解決,那就是請(qǐng)求延遲。
通過(guò)研究,我們發(fā)現(xiàn)數(shù)據(jù)庫(kù) CPU 的消耗占比達(dá)到了 80%-90%,因此擴(kuò)展數(shù)據(jù)層成為了當(dāng)務(wù)之急。數(shù)據(jù)層的擴(kuò)展是一件很棘手的事情,雖然對(duì)于服務(wù)無(wú)狀態(tài)請(qǐng)求的 API 服務(wù)器來(lái)說(shuō),只需要添加更多實(shí)例即可,但是對(duì)于大多數(shù)數(shù)據(jù)庫(kù)系統(tǒng)來(lái)說(shuō),卻不是這樣。
緩存
要從數(shù)據(jù)庫(kù)獲得更多信息的最簡(jiǎn)單方法之一是給系統(tǒng)引入一個(gè)新的組件:緩存層。實(shí)現(xiàn)緩存最常用的方法是使用內(nèi)存中的鍵值存儲(chǔ)(如 Redis 或 Memcached),且大多數(shù)云廠商都會(huì)提供數(shù)據(jù)庫(kù)服務(wù)的托管版本。
當(dāng)該服務(wù)正在進(jìn)行對(duì)數(shù)據(jù)庫(kù)相同信息的大量重復(fù)調(diào)用時(shí),就是緩存大顯身手的時(shí)候了。當(dāng)我們?cè)L問(wèn)數(shù)據(jù)庫(kù)一次時(shí),緩存就會(huì)保存信息,之后再進(jìn)行相同請(qǐng)求時(shí),就不必再訪問(wèn)數(shù)據(jù)庫(kù)了。
例如,如果有人想在 Graminsta 中訪問(wèn) Mavid Mobrick 的個(gè)人資料頁(yè)面時(shí),我們把從數(shù)據(jù)庫(kù)中得到的結(jié)果,緩存在 Redis 中關(guān)鍵字 user:id 下,到期時(shí)間為 30 秒。之后,每當(dāng)有人訪問(wèn) Mavid Mobrick 的個(gè)人資料時(shí),我們會(huì)首先查看 Redis,如果存在相關(guān)資料,那就直接從 Redis 提供數(shù)據(jù)。
大多數(shù)緩存服務(wù)的另一個(gè)優(yōu)點(diǎn)是,與數(shù)據(jù)庫(kù)相比,更容易擴(kuò)展。Redis 有個(gè)內(nèi)建的 Redis 集群(Redis Cluster)模式,用的是跟負(fù)載均衡器類似的方式,可以把我們的 Redis 緩存分布到多臺(tái)機(jī)器上 。
所有高度擴(kuò)展的應(yīng)用程序幾乎都充分利用了緩存的優(yōu)勢(shì),緩存是構(gòu)建快速 API 不可或缺的部分,可以提供更好的查詢和更高效的代碼,如果沒(méi)有緩存,我們可能很難擴(kuò)展到數(shù)百萬(wàn)用戶的規(guī)模。
只讀副本
由于對(duì)數(shù)據(jù)庫(kù)的訪問(wèn)相當(dāng)多,因此我們需要在數(shù)據(jù)庫(kù)管理系統(tǒng)來(lái)添加只讀副本。借助上面提到的托管服務(wù),只需要點(diǎn)擊一下就可以完成。只讀副本將和主數(shù)據(jù)庫(kù)保持一致,并且能夠用于 SELECT 語(yǔ)句。
7. 未來(lái)展望
隨著應(yīng)用的不斷擴(kuò)展,我們會(huì)把重點(diǎn)放在拆分獨(dú)立擴(kuò)展的服務(wù)。例如,如果我們使用了 websockets,那么會(huì)把 websockets 處理代碼抽取出來(lái),放在新的實(shí)例上,同時(shí)安裝負(fù)載均衡器。該負(fù)載均衡器可以根據(jù) websocket 連接打開(kāi)或關(guān)閉的數(shù)量來(lái)上下擴(kuò)展,與我們收到的 HTTP 請(qǐng)求數(shù)量無(wú)關(guān)。
如果未來(lái)還會(huì)遇到數(shù)據(jù)層的限制,我們就會(huì)對(duì)數(shù)據(jù)庫(kù)進(jìn)行分區(qū)和分片。
我們會(huì)使用 New Relic 或 Datadog 等服務(wù)安裝監(jiān)控程序,并通過(guò)監(jiān)控程序發(fā)現(xiàn)比較慢的請(qǐng)求,改進(jìn)它。同時(shí),隨著擴(kuò)展的不斷進(jìn)行,我們希望能夠發(fā)現(xiàn)更多的瓶頸并解決它。