面試被問分布式事務(2PC、3PC、TCC),這樣解釋沒毛病!
絮絮叨叨
還記得剛入行開始寫Java時,接觸的第一個項目是國家電網的一個業務系統,這個系統據說投資了5億人民幣進行研發,鼎盛時期研發人員一度達到過500人。項目采用當時最流行的ssh(Struts+Spring+Hibernate)框架,典型的三層架構(controller - > service -> dao)簡單又粗暴,所有人寫的代碼都放在一個大工程里,項目文件大小達到幾百M,解決代碼沖突是當時最大的工作量。
然而戲劇性的是,交測當天五人同時上線,項目崩 崩 崩潰了。。。哎!你永遠想象不到甲方憤怒的樣子,項目組每個人的祖宗都被問候到了。
說了一些沒用的,腦子里總想起這個事,不說不痛快,大家姑且就當笑話聽吧,下邊我們進入正題
背景
前兩天有個學弟公眾號留言,說讓講講分布式事務,面試就掛在這個問題上。時下隨著微服務架構體系的流行,面試的題目也都慢慢開始升級,不再是早些年單純的問點SSH框架知識、數據結構了。高并發、高可用、分布式服務治理、分布式文件系統、分布式xxx,反正和分布式沾邊的都會問點, 項目實際用不用不要緊,關鍵你得了解,是不是總有一種學不動了的感覺?
什么是分布式事務?
我們看看百度上對于分布式事務的定義:分布式事務是指事務的參與者、支持事務的服務器、資源服務器以及事務管理器分別位于不同的分布式系統的不同節點之上。
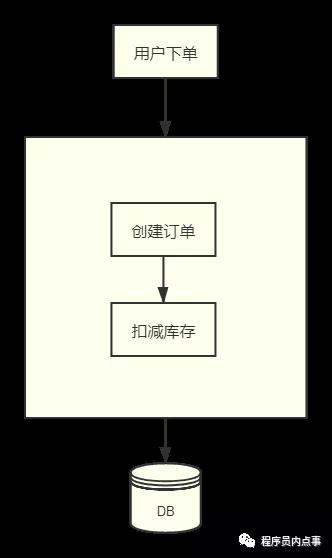
額~ 看了反而更懵逼了,簡單的畫個圖好讓大家理解一下,拿下單減庫存來說舉例:當系統的業務量很小時,“一站式”的系統完全可以滿足現有業務需求,所有的業務都共用一個數據庫,整個下單流程或許只用在一個方法里同一個事務下操作數據庫即可。
此時所有操作都在一個事務里,要么全部提交,要么全部回滾 。
圖糙理不糙
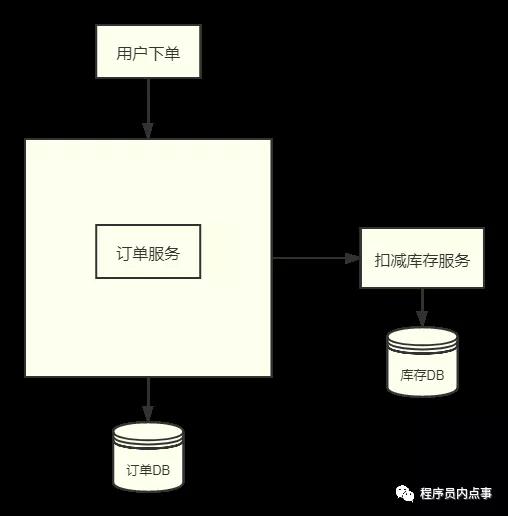
但隨著業務量不斷增長,“一站式”系統漸漸扛不住巨大的流量,就需要對數據庫進行分庫分表,將業務服務化拆分(SOA),就會分離出了訂單中心、用戶中心、庫存中心。而這樣就造成業務間相互隔離,每個業務都維護著自己的數據庫,數據的交換只能進行RPC調用。
用戶再下單時,創建訂單和扣減庫存,需要同時對訂單DB和庫存DB進行操作。兩步操作必須同時成功,否則就會造成業務混亂,可此時我們只能保證自己服務的數據一致性,無法保證調用其他服務的操作是否成功,所以為了保證整個下單流程的數據一致性,就需要分布式事務介入。
圖糙理不糙
在說分布式事務之前,先回憶一下事務的基本概念:事務是一個程序執行單元,里面的所有操作要么全部執行成功,要么全部執行失敗。
一個事務有四個基本特性,也就是我們常說的(ACID)。
Atomicity(原子性) :事務是一個不可分割的整體,事務內所有操作要么全做成功,要么全失敗。
Consistency(一致性) :務執行前后,數據從一個狀態到另一個狀態必須是一致的(A向B轉賬,不能出現A扣了錢,B卻沒收到)。
Isolation(隔離性):多個并發事務之間相互隔離,不能互相干擾。
Durablity(持久性) :事務完成后,對數據庫的更改是永久保存的,不能回滾。
上面這些知識點都是反反復復念叨的概念,面試必背的東西。
分布式事務解決方案
有困難就一定會有解決問題的辦法,什么都難不倒聰明的程序員。
XA協議是一個基于數據庫的分布式事務協議,其分為兩部分:事務管理器和本地資源管理器。事務管理器作為一個全局的調度者,負責對各個本地資源管理器統一號令提交或者回滾。二階提交協議(2PC)和三階提交協議(3PC)就是根據此協議衍生出來而來。如今Oracle、Mysql等數據庫均已實現了XA接口。
1、兩段提交(2PC)
兩段提交顧名思義就是要進行兩個階段的提交:第一階段,準備階段(投票階段) ;第二階段,提交階段(執行階段)。
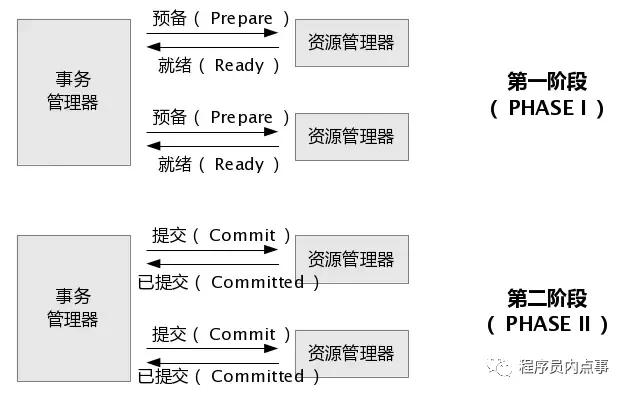
上邊圖片源自網絡,如有侵權聯系刪除
下面還拿下單扣庫存舉例子,簡單描述一下兩段提交(2PC)的原理:
之前說過業務服務化(SOA)以后,一個下單流程就會用到多個服務,各個服務都無法保證調用的其他服務的成功與否,這個時候就需要一個全局的角色(協調者)對各個服務(參與者)進行協調。
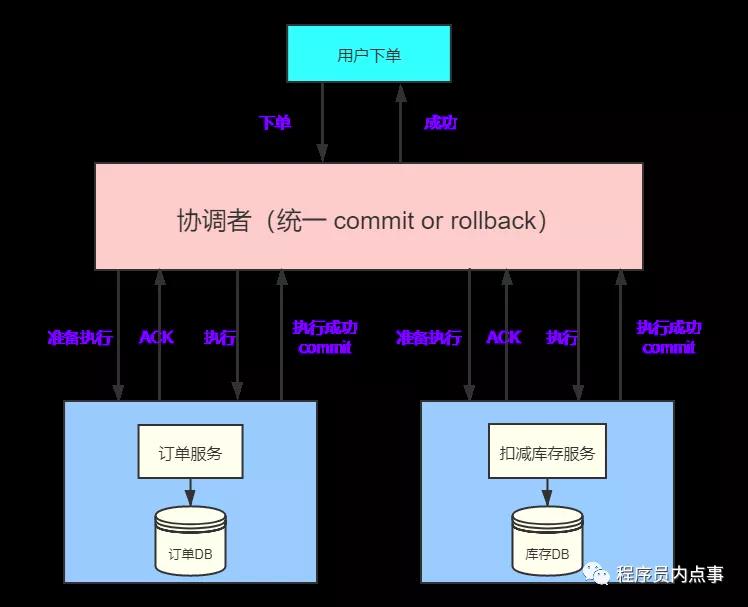
一個下單請求過來通過協調者,給每一個參與者發送Prepare消息,執行本地數據腳本但不提交事務。
如果協調者收到了參與者的失敗消息或者超時,直接給每個參與者發送回滾(Rollback)消息;否則,發送提交(Commit)消息;參與者根據協調者的指令執行提交或者回滾操作,釋放所有事務處理過程中被占用的資源,顯然2PC做到了所有操作要么全部成功、要么全部失敗。
兩段提交(2PC)的缺點
二階段提交看似能夠提供原子性的操作,但它存在著嚴重的缺陷
- 網絡抖動導致的數據不一致: 第二階段中協調者向參與者發送commit命令之后,一旦此時發生網絡抖動,導致一部分參與者接收到了commit請求并執行,可其他未接到commit請求的參與者無法執行事務提交。進而導致整個分布式系統出現了數據不一致。
- 超時導致的同步阻塞問題: 2PC中的所有的參與者節點都為事務阻塞型,當某一個參與者節點出現通信超時,其余參與者都會被動阻塞占用資源不能釋放。
- 單點故障的風險: 由于嚴重的依賴協調者,一旦協調者發生故障,而此時參與者還都處于鎖定資源的狀態,無法完成事務commit操作。雖然協調者出現故障后,會重新選舉一個協調者,可無法解決因前一個協調者宕機導致的參與者處于阻塞狀態的問題。
2、三段提交(3PC)
三段提交(3PC)是對兩段提交(2PC)的一種升級優化,3PC在2PC的第一階段和第二階段中插入一個準備階段。保證了在最后提交階段之前,各參與者節點的狀態都一致。同時在協調者和參與者中都引入超時機制,當參與者各種原因未收到協調者的commit請求后,會對本地事務進行commit,不會一直阻塞等待,解決了2PC的單點故障問題,但3PC 還是沒能從根本上解決數據一致性的問題。
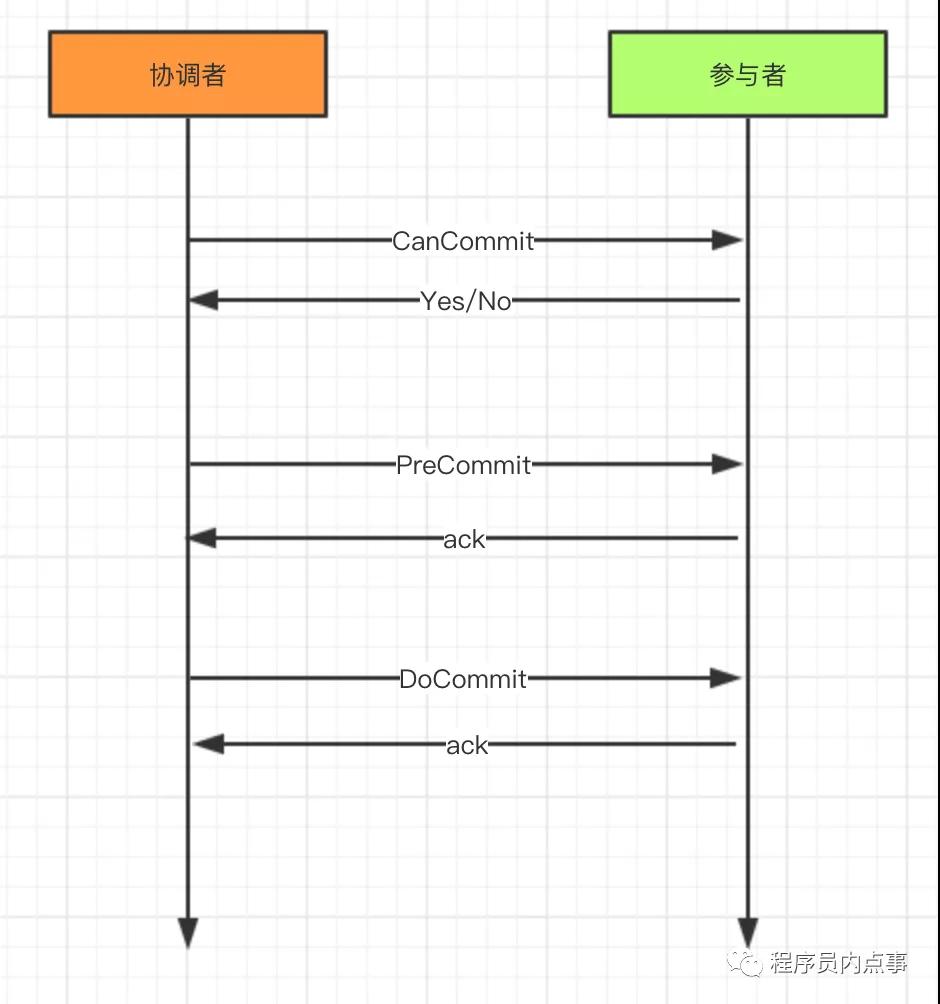
上邊圖片源自網絡,如有侵權聯系刪除
3PC 的三個階段分別是CanCommit、PreCommit、DoCommit
CanCommit:協調者向所有參與者發送CanCommit命令,詢問是否可以執行事務提交操作。如果全部響應YES則進入下一個階段。
PreCommit:協調者向所有參與者發送PreCommit命令,詢問是否可以進行事務的預提交操作,參與者接收到PreCommit請求后,如參與者成功的執行了事務操作,則返回Yes響應,進入最終commit階段。一旦參與者中有向協調者發送了No響應,或因網絡造成超時,協調者沒有接到參與者的響應,協調者向所有參與者發送abort請求,參與者接受abort命令執行事務的中斷。
DoCommit:在前兩個階段中所有參與者的響應反饋均是YES后,協調者向參與者發送DoCommit命令正式提交事務,如協調者沒有接收到參與者發送的ACK響應,會向所有參與者發送abort請求命令,執行事務的中斷。
3、補償事務(TCC)
很多初學者總是被TCC、2PC、3PC這幾個概念搞混淆,傻傻分不清,實際上 TCC與 2PC、3PC一樣,都只是實現分布式事務的一種方案而已。
TCC(Try-Confirm-Cancel)又被稱補償事務,TCC與2PC的思想很相似,事務處理流程也很相似,但2PC 是應用于在DB層面,TCC則可以理解為在應用層面的2PC,是需要我們編寫業務邏輯來實現。
TCC它的核心思想是:"針對每個操作都要注冊一個與其對應的確認(Try)和補償(Cancel)"。
還拿下單扣庫存解釋下它的三個操作:
Try階段:
下單時通過Try操作去扣除庫存預留資源。
Confirm階段:
確認執行業務操作,在只預留的資源基礎上,發起購買請求。
Cancel階段:
只要涉及到的相關業務中,有一個業務方預留資源未成功,則取消所有業務資源的預留請求。
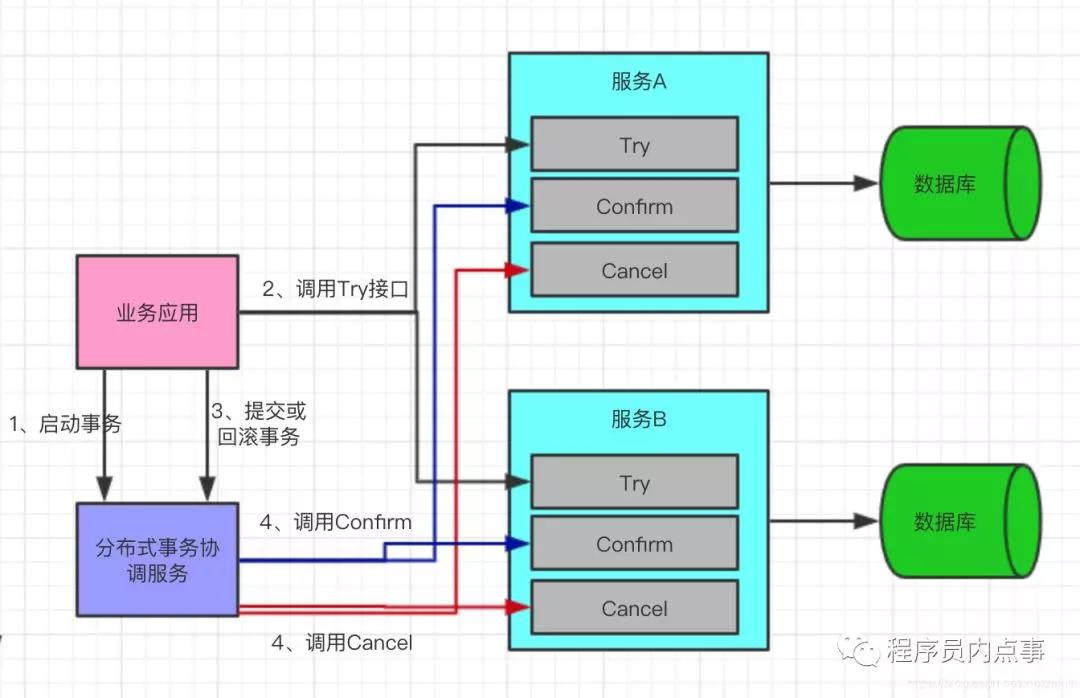
上邊圖片源自網絡,如有侵權聯系刪除
TCC的缺點:
- 應用侵入性強:TCC由于基于在業務層面,至使每個操作都需要有 try、confirm、cancel三個接口。
- 開發難度大:代碼開發量很大,要保證數據一致性 confirm 和 cancel 接口還必須實現冪等性。
總結
很淺顯的介紹了一下2PC、3PC、TCC的概念,如有錯誤還望溫柔指正,分布式事務一直都是面試中比較熱點的問題,也是進階高級Java工程師必備的知識點。