這些讓人相見恨晚的高效代碼小技巧你聽過嗎?
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
Python出圈了,似乎現在人人都在學Python,朋友圈的課程廣告遍地跑,小學生都看起了編程入門。的確,Python是目前公認的最通用的編程語言,以其易理解易操作的優勢攻占了每一個職場人大學生必備技能榜單。
學會Python確實能協助你高效工作。但學了是一回事兒,會了是另一回事兒,不是每個人學過Python的人都能玩得轉它。以下幾個小技巧,能讓你離玩轉Python更進一步。
把不常用的類別整合成一個
有時你會得到元素分布不均的欄,少有的類別也是僅僅存在而已。通常會希望能將這些類別合并為一個。
- df.artists.value_counts()
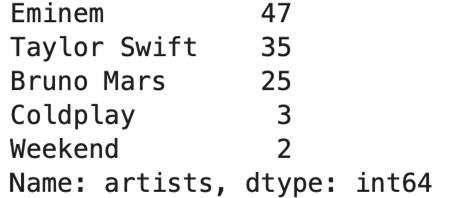
要將Coldplay和Weekend合并到一個類別中,因為它們對數據集的影響微乎其微。該怎么做?
首先,找到不想改變的元素,比如Eminem,TaylorSwift和BrunoMars:
- myList =df.artists.value_counts().nlargest(3).index
使用where()函數替換其他元素
- dfdf_new = df.where(df.artists.isin(myList),other='otherartists')
- df_new.artists.value_counts()

這便是按要求修改后的更新列。
查找列表的新元素
給定兩個不同的列表,要求找到一個列表中有但另一個列表中沒有的元素時,參照這兩個列表:
- A = [ 1, 3, 5, 7, 9 ]
- B = [ 4, 5, 6, 7, 8 ]
為了找到列表A中的新元素,我們取列表A與列表B的集合差:
- set(A) - set(B)
![]()
值1、3和9只出現在列表A而不出現在列表B中。
擺脫警告
運行代碼時,經常會收到很多警告。沒過多久它就開始使人惱火。例如每當導入朝代時,可能會收到警告(FutureWarning)消息

可以用下述代碼隱藏所有警告。請確保其寫在代碼頂部。
- import warnings
- warnings.filterwarnings(action='ignore')
- import keras
這將有助于在整個代碼中隱藏所有警告。
Map() 函數
map()函數接受函數(function)和序列(iterable)兩個參數,返回包含結果的映射:
- map(func,itr)
func 是指接收來自映射傳遞的給定序列元素的函數。
itr是指可以被映射的序列。
- def product(n1,n2):
- return n1 *n2 list1 = (1, 2, 3, 4)
- list2 = (10,20,30,40)result = map(product, list1,list2)
- list(result)
![]()
開始解碼。
Product函數接受兩個列表,并反饋兩個列表的乘積。列表1和列表2是充當map函數序列的兩個列表。map()集product函數和序列于一身→列表1和列表2,以及反饋兩個列表的乘積作為結果。
Map + Lambda組合
可以使用lambda表達式修改上述代碼,以替換product函數:
- list1 = (1, 2, 3, 4)
- list2 = (10,20,30,40)
- result = map(lambda x,y: x * y, list1,list2)
- print(list(result))
Lambda表達式有助于降低單獨編寫函數的成本。
啟動、停止和設置
Slice(start:stop[:step])是通常包含部分序列的對象。
- 如果只提供停止,則從索引0開始生成部分序列直到停止。
- 如果只提供開始,則在索引開始之后生成部分序列直到最后一個元素。
- 如果同時提供開始和停止,則在索引開始之后生成部分序列直到停止。
- 如果起始、停止和步驟三者同時提供,則在索引開始之后生成部分序列直到停止,并增加索引步驟。
- x = [ 1, 2, 3, 4, 5, 6, 7, 8 ]
- x[ 1: 6: 2]
![]()
上面的代碼中,1是開始索引,6是停止索引,2是步驟索引。這意味著從指數1開始到指數6停止,步長為2。
還可以使用[::-1]操作翻轉列表:
- x[::-1]
![]()
沒錯,通過開始、停止和步驟操作,很容易就可以將整個列表進行逆轉。
組合Zip和Enumerate
zip和enumerate函數常用于for循環,兩個一起用就更精彩了。它不僅可以在單個循環中迭代多個值,而且可以同時獲得索引。
- NAME = ['Sid','John','David']
- BIRD = ['Eagle','Sparrow','Vulture']
- CITY =['Mumbai','US','London']for i,(name,bird,city) inenumerate(zip(NAME,BIRD,CITY)):
- print(i,' represents ',name,' ,',bird,' and ',city)

Zip函數可以將所有列表合并為一個,以便同時訪問每個列表,而Enumerate函數協助獲得索引以及附加到該索引的元素。
隨機抽樣
有時會遇到非常大的數據集,因而決定處理數據的隨機子集。pandas數據框的sample函數可以實現更多的功能。不妨看看在上面已經創建過的歌星數據模型。
- df.sample(n=10)
這有助于獲取數據集里隨機的10行。
- df.sample(frac=0.5).reset_index(drop=True)
分解上面的代碼,frac參數取值在0到1之間,包括1。它占用分配給它的數據流的一部分。在上面的代碼片段中指定了0.5,因此它將返回size→0.5*的隨機子集
你能看到前面的reset_index函數。它有助于適當地重排索引,因為獲取隨機子集時,索引也會被重新排列。
保留內存
隨著編程的深入,你將意識到記住內存高效代碼的重要性。生成器是返回我們可以遍歷的對象的函數。這有助于有效利用內存,因此它主要用于當在無限長的序列上迭代。
- def SampleGenerator(n):
- yield n
- nn = n+1
- yield n
- nn = n+1
- yield ngen = SampleGenerator(1)
Yield 語句暫停函數,保存其所有狀態,并在以后的連續調用中繼續執行。
- print(next(gen))
- print(next(gen))
- print(next(gen))
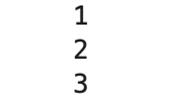
如你所見,yield保存了前一個狀態,而每當我們調用下一個函數時,它都會繼續到下一個返回其新輸出的yield。
通過添加在generator函數內無限運行的while循環,可以迭代單個yield。
- def updatedGenerator(n):
- while(1):
- yield n
- nn = n + 1
- a = updatedGenerator(1)for i in range(5):
- print(next(a))
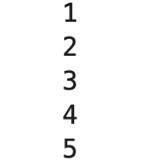
While語句可以反復迭代相同的yield語句。
救世主Skiprows
重頭戲壓軸出場!要讀取的csv文件過大,以至于內存不夠用?Skiprows可以輕松解決。
圖源:unsplash
它可以指定需要在數據框中跳過的行數。
假設有個100萬行的數據集,不適合你的內存。如果分配skiprows=0.5 million(跳讀50萬行),在讀取數據集的時候就會跳過50萬行,這樣就可以輕松地讀取數據集的子集。
- df = pd.read_csv('artist.csv')
- df_new = pd.read_csv('artist.csv',skiprows=50)df.shape,
- df_new.shape
![]()
在上面的代碼片段中,df表示包含112行的數據集。在添加了skiprows=50(跳讀50行)之后,它跳過了數據集中的50行,從而讀取了62行作為新數據集。
破案啦!編碼效率提升一大截的秘密就在于此。