













聯(lián)合索引在B+樹上的存儲結(jié)構(gòu)
本文主要講解的內(nèi)容有:
- 聯(lián)合索引在B+樹上的存儲結(jié)構(gòu)
- 聯(lián)合索引的查找方式
- 為什么會有最左前綴匹配原則
在分享這篇文章之前,我在網(wǎng)上查了關于MySQL聯(lián)合索引在B+樹上的存儲結(jié)構(gòu)這個問題,翻閱了很多博客和技術文章,其中有幾篇講述的與事實相悖。慶幸的是看到搜索引擎列出的有一條是來自思否社區(qū)的問答,有答主回答了這個問題,貼出一篇文章和一張圖以及一句簡單的描述。
所以在這樣的條件下這篇文章就誕生了。
聯(lián)合索引的存儲結(jié)構(gòu)
下面就引用思否社區(qū)的這個問答來展開我們今天要討論的聯(lián)合索引的存儲結(jié)構(gòu)的問題。
來自思否的提問,聯(lián)合索引的存儲結(jié)構(gòu) (segmentfault.com/q/101000001…) 有碼友回答如下:
聯(lián)合索引 bcd , 在索引樹中的樣子如圖 , 在比較的過程中 ,先判斷 b 再判斷 c 然后是 d ,
由于回答只有一張圖一句話,可能會讓你有點看不懂,所以我們就借助前人的肩膀用這個例子來更加細致的講探尋一下聯(lián)合索引在B+樹上的存儲結(jié)構(gòu)吧。
首先,表T1有字段a,b,c,d,e,其中a是主鍵,除e為varchar其余為int類型,并創(chuàng)建了一個聯(lián)合索引idx_t1_bcd(b,c,d),然后b、c、d三列作為聯(lián)合索引,在B+樹上的結(jié)構(gòu)正如上圖所示。聯(lián)合索引的所有索引列都出現(xiàn)在索引數(shù)上,并依次比較三列的大小。上圖樹高只有兩層不容易理解,下面是假設的表數(shù)據(jù)以及我對其聯(lián)合索引在B+樹上的結(jié)構(gòu)圖的改進。PS:基于InnoDB存儲引擎。
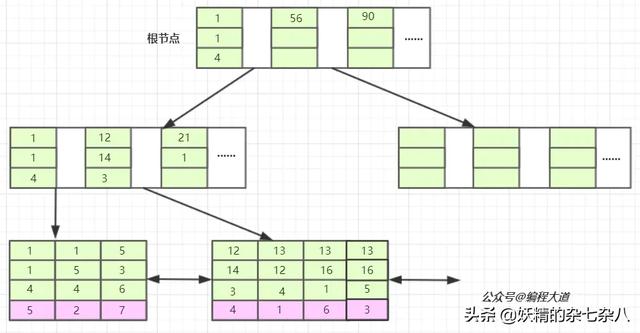
bcd聯(lián)合索引在B+樹上的結(jié)構(gòu)圖
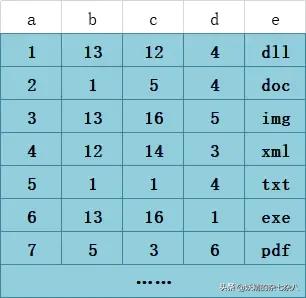
T1表
通過這倆圖我們心里對聯(lián)合索引在B+樹上的存儲結(jié)構(gòu)就有了個大概的認識。下面用我的語言為大家解釋一下吧。
我們先看T1表,他的主鍵暫且我們將它設為整型自增的(PS:至于為什么是整型自增上篇文章有詳細介紹這里不再多說),InnoDB會使用主鍵索引在B+樹維護索引和數(shù)據(jù)文件,然后我們創(chuàng)建了一個聯(lián)合索引(b,c,d)也會生成一個索引樹,同樣是B+樹的結(jié)構(gòu),只不過它的data部分存儲的是聯(lián)合索引所在行的主鍵值(上圖葉子節(jié)點紫色背景部分),至于為什么輔助索引data部分存儲主鍵值上篇文章也有介紹,感興趣或還不知道的可以去看一下。
好了大致情況都介紹完了。下面我們結(jié)合這倆圖來解釋一下。
對于聯(lián)合索引來說只不過比單值索引多了幾列,而這些索引列全都出現(xiàn)在索引樹上。對于聯(lián)合索引,存儲引擎會首先根據(jù)第一個索引列排序,如上圖我們可以單看第一個索引列,如,1 1 5 12 13....他是單調(diào)遞增的;如果第一列相等則再根據(jù)第二列排序,依次類推就構(gòu)成了上圖的索引樹,上圖中的1 1 4 ,1 1 5以及13 12 4,13 16 1,13 16 5就可以說明這種情況。
聯(lián)合索引的查找方式
當我們的SQL語言可以應用到索引的時候,比如 select * from T1 where b = 12 and c = 14 and d = 3; 也就是T1表中a列為4的這條記錄。存儲引擎首先從根節(jié)點(一般常駐內(nèi)存)開始查找,第一個索引的第一個索引列為1,12大于1,第二個索引的第一個索引列為56,12小于56,于是從這倆索引的中間讀到下一個節(jié)點的磁盤文件地址,從磁盤上Load這個節(jié)點,通常伴隨一次磁盤IO,然后在內(nèi)存里去查找。當Load葉子節(jié)點的第二個節(jié)點時又是一次磁盤IO,比較第一個元素,b=12,c=14,d=3完全符合,于是找到該索引下的data元素即ID值,再從主鍵索引樹上找到最終數(shù)據(jù)。
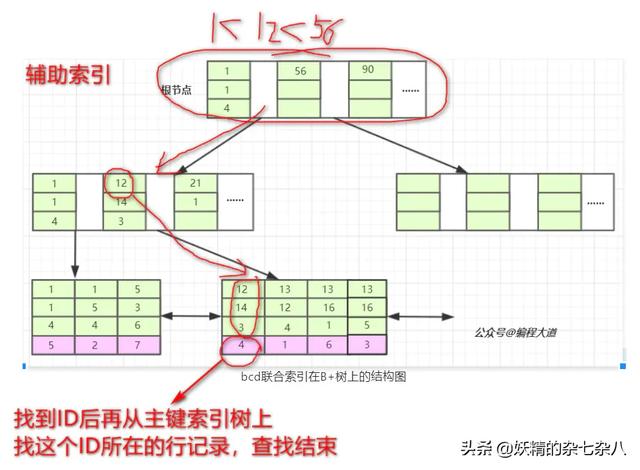
最左前綴匹配原則
之所以會有最左前綴匹配原則和聯(lián)合索引的索引構(gòu)建方式及存儲結(jié)構(gòu)是有關系的。
首先我們創(chuàng)建的idx_t1_bcd(b,c,d)索引,相當于創(chuàng)建了(b)、(b、c)(b、c、d)三個索引,看完下面你就知道為什么相當于創(chuàng)建了三個索引。
我們看,聯(lián)合索引是首先使用多列索引的第一列構(gòu)建的索引樹,用上面idx_t1_bcd(b,c,d)的例子就是優(yōu)先使用b列構(gòu)建,當b列值相等時再以c列排序,若c列的值也相等則以d列排序。我們可以取出索引樹的葉子節(jié)點看一下。
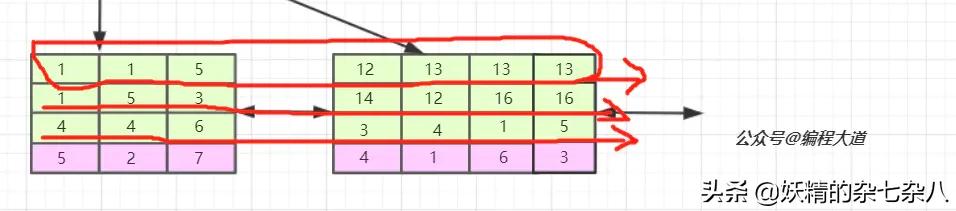
索引的第一列也就是b列可以說是從左到右單調(diào)遞增的,但我們看c列和d列并沒有這個特性,它們只能在b列值相等的情況下這個小范圍內(nèi)遞增,如第一葉子節(jié)點的第1、2個元素和第二個葉子節(jié)點的后三個元素。 由于聯(lián)合索引是上述那樣的索引構(gòu)建方式及存儲結(jié)構(gòu),所以聯(lián)合索引只能從多列索引的第一列開始查找。所以如果你的查找條件不包含b列如(c,d)、(c)、(d)是無法應用緩存的,以及跨列也是無法完全用到索引如(b,d),只會用到b列索引。
這就像我們的電話本一樣,有名和姓以及電話,名和姓就是聯(lián)合索引。在姓可以以姓的首字母排序,姓的首字母相同的情況下,再以名的首字母排序。
如:
- M
- 毛 不易 178********
- 馬 化騰 183********
- 馬 云 188********
- Z
- 張 杰 189********
- 張 靚穎 138********
- 張 藝興 176********
我們知道名和姓是很快就能夠從姓的首字母索引定位到姓,然后定位到名,進而找到電話號碼,因為所有的姓從上到下按照既定的規(guī)則(首字母排序)是有序的,而名是在姓的首字母一定的條件下也是按照名的首字母排序的,但是整體來看,所有的名放在一起是無序的,所以如果只知道名查找起來就比較慢,因為無法用已排好的結(jié)構(gòu)快速查找。
到這里大家是否明白了為啥會有最左前綴匹配原則了吧。
實踐
如下列舉一些SQL的索引使用情況
- select * from T1 where b = 12 and c = 14 and d = 3;-- 全值索引匹配 三列都用到
- select * from T1 where b = 12 and c = 14 and e = 'xml';-- 應用到兩列索引
- select * from T1 where b = 12 and e = 'xml';-- 應用到一列索引
- select * from T1 where b = 12 and c >= 14 and e = 'xml';-- 應用到一列索引及索引條件下推優(yōu)化
- select * from T1 where b = 12 and d = 3;-- 應用到一列索引 因為不能跨列使用索引 沒有c列 連不上
- select * from T1 where c = 14 and d = 3;-- 無法應用索引,違背最左匹配原則
后記
到這里MySQL索引的聯(lián)合索引的存儲結(jié)構(gòu)及查找方式就講完了,本人能力有限,也是站著前人的肩膀上創(chuàng)作的此文,因為看到搜索引擎的搜索結(jié)果前幾個技術文章中有存在講述不清或講述有誤的地方,所以自己才總結(jié)出這篇文章分享給大家,如有不對的地方一定要指正哦,謝謝了。
這篇文章斷斷續(xù)續(xù)利用工作之余畫圖加寫作用了兩三天,主要內(nèi)容就是上面這些了。不可否認,這篇文章在一定程度上有紙上談兵之嫌,因為我本人對MySQL的使用屬于菜鳥級別,更沒有太多數(shù)據(jù)庫調(diào)優(yōu)的經(jīng)驗,在這里高談闊論實屬慚愧。就當是我個人的一篇學習筆記了。
另外,MySQL索引及知識非常廣泛,本文只是涉及到其中一部分。如與排序(ORDER BY)相關的索引優(yōu)化及覆蓋索引(Covering index)的話題本文并未涉及,同時除B-Tree索引外MySQL還根據(jù)不同引擎支持的哈希索引、全文索引等等本文也并未涉及。如果有機會,希望再對本文未涉及的部分進行補充吧。



















