













一邊動,一邊畫,自己就變二次元:實時交互式視頻風格化
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
動畫,動畫,就是你動你的,我畫我的。
就像下面這張GIF,左邊是張靜態圖片,隨著畫者一點一點為其勾勒色彩,右邊的動圖也在實時地變換顏色。
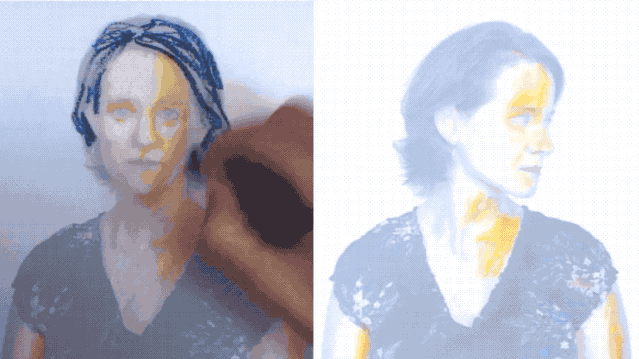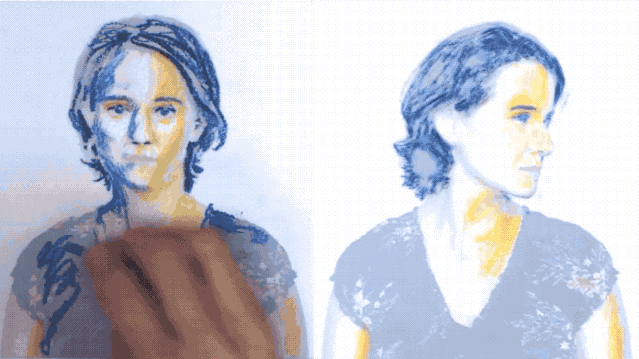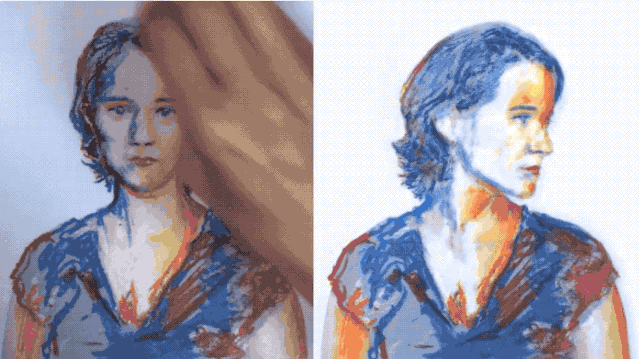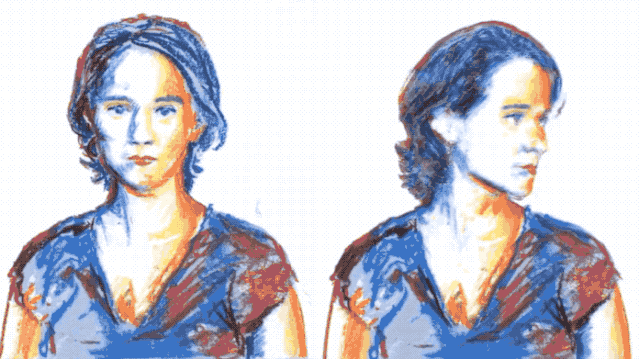
這就是來自布拉格捷克理工大學和Snap研究所的黑科技——**只需要2個特定的幀,就能實時變換視頻中對象的顏色、風格甚至是樣式。
當然,更厲害的還在后面。
拿一張你的卡通頭像圖片,隨意對其修改,頂著這張頭像,坐在鏡頭前的你,也會實時發生改變。

甚至,你還可以一邊畫自己,一邊欣賞自己慢慢變成動畫效果的過程。

真可謂是這邊動著,那邊畫著,動畫就出來了。
而且整個過程無需冗長的訓練過程,也不需要大規模訓練數據集,研究也提交至SIGGRAPH 2020。
那么,這么神奇的效果到底是如何做到的呢?
交互式視頻風格化
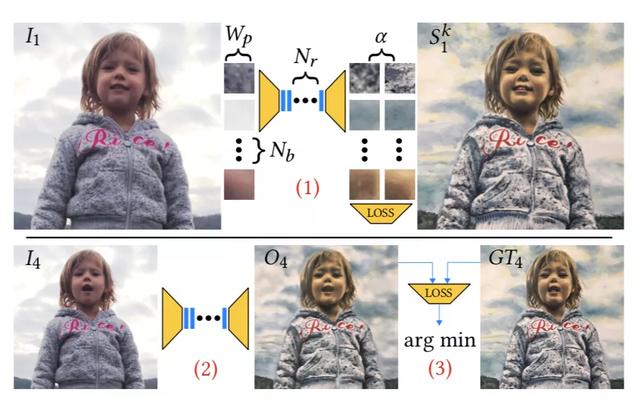
首先,輸入一個由 N 幀組成的視頻序列 I。
如下圖所示,對于任何一幀 Ii,可以選擇用蒙版 Mi來劃定風格遷移的區域,或者是對整一幀進行風格遷移。

用戶需要做的是提供風格化的關鍵幀 Sk,其風格會被以在語義上有意義的方式傳遞到整個視頻序列中。
與此前方法不同的是,這種風格遷移是以隨機順序進行的,不需要等待順序靠前的幀先完成風格化,也不需要對來自不同關鍵幀的風格化內容進行顯式合并。
也就是說,該方法實際上是一種翻譯過濾器,可以快速從幾個異構的手繪示例 Sk 中學習風格,并將其“翻譯”給視頻序列 I 中的任何一幀。
這個圖像轉換框架基于 U-net 實現。并且,研究人員采用基于圖像塊(patch-based)的訓練方式和抑制視頻閃爍的解決方案,解決了少樣本訓練和時間一致性的問題。
基于圖像塊的訓練策略
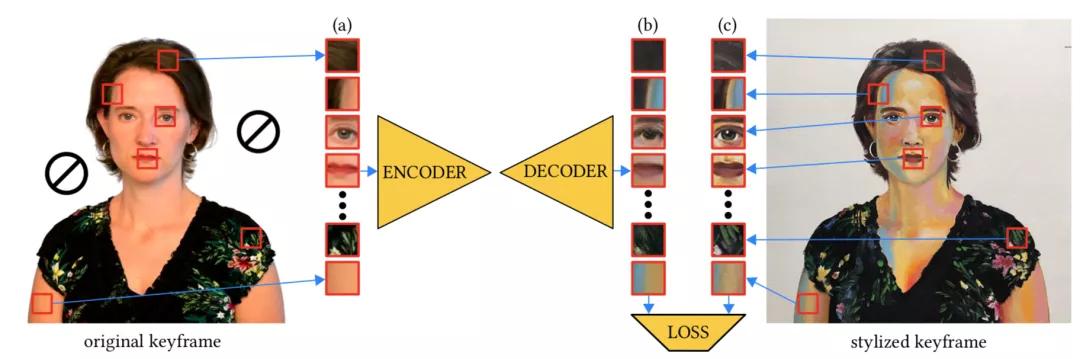
關鍵幀是少樣本數據,為了避免過擬合,研究人員采用了基于圖像塊的訓練策略。
從原始關鍵幀(Ik)中隨機抽取一組圖像塊(a),在網絡中生成它們的風格化對應塊(b)。
然后,計算這些風格化對應塊(b)相對于從風格化關鍵幀(Sk)中取樣對應圖像塊的損失,并對誤差進行反向傳播。
這樣的訓練方案不限于任何特定的損失函數。本項研究中,采用的是L1損失、對抗性損失和VGG損失的組合。
超參數優化
解決了過擬合之后,還有一個問題,就是超參數的優化。不當的超參數可能會導致推理質量低下。
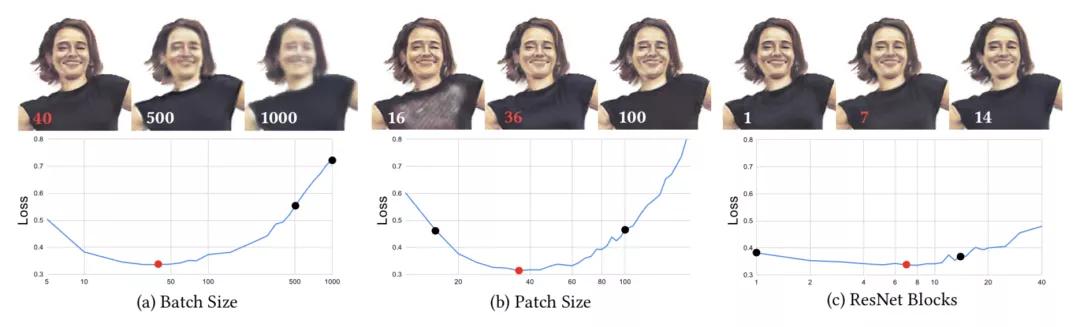
研究人員使用網格搜索法,對超參數的4維空間進行采樣:Wp——訓練圖像塊的大小;Nb——一個batch中圖像塊的數量;α——學習率;Nr——ResNet塊的數量。
對于每一個超參數設置:(1)執行給定時間訓練;(2)對不可見幀進行推理;(3)計算推理出的幀(O4)和真實值(GT4)之間的損失。
而目標就是將這個損失最小化。
提高時間一致性
訓練好了翻譯網絡,就可以在顯卡上實時或并行地實現視頻風格遷移了。
不過,研究人員發現在許多情況下,視頻閃爍仍很明顯。
第一個原因,是原始視頻中存在時態噪聲。為此,研究人員采用了在時域中運行的雙邊濾波器的運動補償變體。
第二個原因,是風格化內容的視覺歧義。解決方法是,提供一個額外的輸入層,以提高網絡的判別能力。
該層由一組隨機2維高斯分布的稀疏集合組成,能幫助網絡識別局部上下文,并抑制歧義。

不過,研究人員也提到了該方法的局限性:
當出現新的沒有被風格化的特征時,該方法通常不能為其生成一致的風格化效果。需要提供額外的關鍵幀來使風格化一致。
處理高分辨率(如4K)關鍵幀比較困難
使用運動補償的雙邊濾波器,以及隨機高斯混合層的創建,需要獲取多個視頻幀,對計算資源的要求更高,會影響實時視頻流中實時推理的效果。(Demo的實時捕獲會話中,沒有采用提高時間一致性的處理方法)
研究團隊
這項研究一作為Ondřej Texler,布拉格捷克理工大學計算機圖形與交互系的三年級博士生。
本科和碩士也均畢業于此。主要研究興趣是計算機圖形學、圖像處理、計算機視覺和深度學習。
除了一作之外,我們還發現一位華人作者——柴蒙磊。博士畢業于浙江大學,目前為Snap Research創意視覺(Creative Vision)組的資深研究科學家。
主要從事計算機視覺和計算機圖形學的研究,主攻人類數字化、圖像處理、三維重建和基于物理的動畫。
傳送門
項目地址:
https://ondrejtexler.github.io/patch-based_training/

















