













我終于搞懂了微服務,太不容易了...
微服務是什么?拋去教條性質的解釋,從巨石應用到微服務應用,耦合度是其中最大的變化。
圖片來自 Pexels
或是將多個模塊中重復的部分進行拆分,或是純粹為了拆分膨脹的單體應用,這些拆分出來的部分獨立成一個服務單獨部署與維護,便是微服務了。
拆分后自然而然會催生出一些必要的需求:
- 從本地方法調用的關系衍變成遠程過程調用的關系,那么可靠的通信功能是首要的。
- 隨著拆分工作的推進,資源調度關系會變得錯綜復雜,這時候需要完善的服務治理。
- 調用關系網的整體復雜化還會給我們帶來更大的風險,即鏈式反應導致服務雪崩的可能性,所以如何保障服務穩定性也是微服務架構中需要考慮的。
- 這點就不是內需而算是自我演進了,服務化后,如果能結合容器化、Devops 技術實現服務運維一體化,將大大降低微服務維護的成本,不管是現在還是將來。
微服務是什么樣的
從目前常見網站架構的宏觀角度看,微服務處在中間的層次。紅框圈出的部分都屬于微服務的范疇。
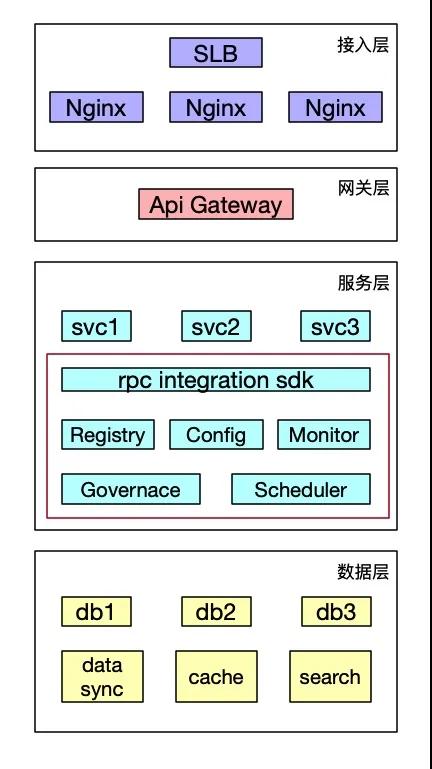
包括最基礎的 RPC 框架、注冊中心、配置中心,以及更廣義角度的監控追蹤、治理中心、調度中心等。
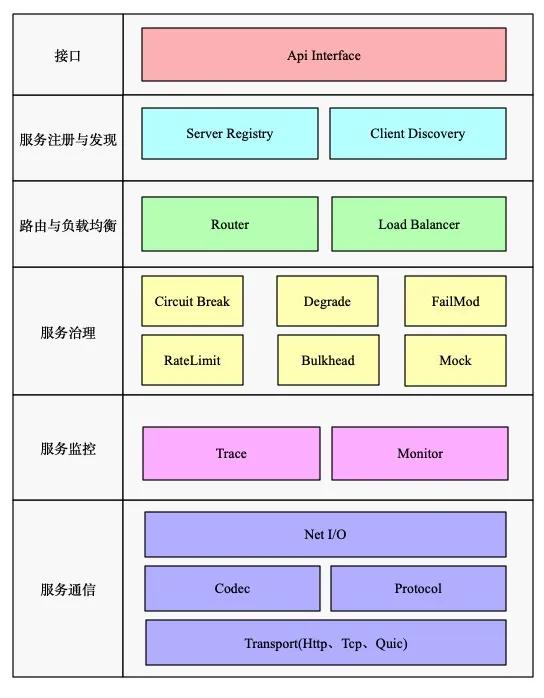
從微服務自身角度來看,則大致會包含以下這些模塊:
- 服務注冊與發現
- RPC 遠程調用
- 路由與負載均衡
- 服務監控
- 服務治理
服務化的前提
是不是只要套上微服務框架就算是一個微服務了呢?雖然這樣有了微服務的表,但卻沒有微服務的實質,即“微”。
微服務化的前提是服務拆分到足夠”微“,足夠單一職責,當然拆分程度與服務邊界都需要結合業務自行把握。
廣義的服務拆分即包含了應用拆分,也包含了數據拆分。應用拆分后需要引入微服務框架來進行服務通信與服務治理,這也就是傳統定義上的微服務。
數據拆分后同樣需要引入一系列手段來進行保障,由于不是與微服務強相關的話題,在此只做簡單闡述:
- 分布式 ID
- 新表優化
- 數據遷移與數據同步
- SQL 調用方案改造
- 切庫方案
- 數據一致性
具體的微服務請求背后
在我們對微服務架構有了整體的認識,并且具備了服務化的前提后,一個完整的微服務請求需要涉及到哪些內容呢?
這其中包括了微服務框架所具備的三個基本功能:
- 服務的發布與引用
- 服務的注冊與發現
- 服務的遠程通信
服務的發布與引用
首先我們面臨的第一個問題是,如何發布服務和引用服務。具體一點就是,這個服務的接口名是啥,有哪些參數,返回值是什么類型等等,通常也就是接口描述信息。
常見的發布和引用的方式包括:
- RESTful API/聲明式 Restful API
- XML
- IDL
一般來講,不管使用哪種方式,服務端定義接口與實現接口都是必要的,例如:
- @exa(id = "xxx")
- public interface testApi {
- @PostMapping(value = "/soatest/{id}")
- String getResponse(@PathVariable(value = "id") final Integer index, @RequestParam(value = "str") final String Data);
- }
具體實現如下:
- public class testApiImpl implements testApi{
- @Override
- String getResponse(final Integer index, final String Data){
- return "ok";
- }
- }
聲明式 Restful API:這種常使用 HTTP 或者 HTTPS 協議調用服務,相對來說,性能稍差。
首先服務端如上定義接口并實現接口,隨后服務提供者可以使用類似 restEasy 這樣的框架通過 Servlet 的方式發布服務,而服務消費者直接引用定義的接口調用。
除此之外還有一種類似 Feign 的方式,即服務端的發布依賴于 SpringMVC Controller,框架只基于客戶端模板化 HTTP 請求調用。
這種情況下需接口定義與服務端 Controller 協商一致,這樣客戶端直接引用接口發起調用即可。
XML:使用私有 RPC 協議的都會選擇 XML 配置的方式來描述接口,比較高效,例如 Dubbo、Motan 等。
同樣服務端如上定義接口并實現接口,服務端通過 server.xml 將文件接口暴露出去。服務消費者則通過 client.xml 引用需要調用的接口。
但這種方式對業務代碼入侵較高,XML 配置有變更時候,服務消費者和服務提供者都需要更新。
IDL:是接口描述語言,常用于跨語言之間的調用,最常用的 IDL 包括 Thrift 協議以及 gRpc 協議。
例如 gRpc 協議使用 Protobuf 來定義接口,寫好一個 proto 文件后,利用語言對應的 protoc 插件生成對應 server 端與 client 端的代碼,便可直接使用。
但是如果參數字段非常多,proto 文件會顯得非常大難以維護。并且如果字段經常需要變更,例如刪除字段,PB 就無法做到向前兼容。
一些 Tips:不管哪種方式,在接口變更的時候都需要通知服務消費者。消費者對api的強依賴性是很難避免的,接口變更引起的各種調用失敗也十分常見。
所以如果有變更,盡量使用新增接口的方式,或者給每個接口定義好版本號吧。在使用上,大多數人的選擇是對外 Restful,對內 XML,跨語言 IDL。
一些問題:在實際的服務發布與引用的落地上,還會存在很多問題,大多和配置信息相關。
例如一個簡單的接口調用超時時間配置,這個配置應該配在服務級別還是接口級別?是放在服務提供者這邊還是服務消費者這邊?
在實踐中,大多數服務消費者會忽略這些配置,所以服務提供者自身提供默認的配置模板是有必要的,相當于一個預定義的過程。
每個服務消費者在繼承服務提供者預定義好的配置后,還需要能夠進行自定義的配置覆蓋。
但是,比方說一個服務有 100 個接口,每個接口都有自身的超時配置,而這個服務又有 100 個消費者,當服務節點發生變更的時候,就會發生 100*100 次注冊中心的消息通知,這是比較可怕的,就有可能引起網絡風暴。
服務的注冊與發現
假設你已經發布了服務,并在一臺機器上部署了服務,那么消費者該怎樣找到你的服務的地址呢?
也許有人會說是 DNS,但 DNS 有許多缺陷:
- 維護麻煩,更新延遲
- 無法在客戶端做負載均衡
- 不能做到端口級別的服務發現
其實在分布式系統中,有個很重要的角色,叫注冊中心,便是用于解決該問題。
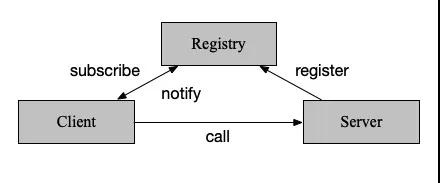
使用注冊中心尋址并調用的過程如下:
- 服務啟動時,向注冊中心注冊自身,并定期發送心跳匯報存活狀態。
- 客戶端調用服務時,向注冊中心訂閱服務,并將節點列表緩存至本地,再與服務端建立連接(當然這兒可以 lazy load)。發起調用時,在本地緩存節點列表中,基于負載均衡算法選取一臺服務端發起調用。
- 當服務端節點發生變更,注冊中心能感知到后通知到客戶端。
注冊中心的實現主要需要考慮以下這些問題:
- 自身一致性與可用性
- 注冊方式
- 存儲結構
- 服務健康監測
- 狀態變更通知
①一致性與可用性
一個老舊的命題,即分布式系統中的 CAP(一致性、可用性、分區容錯性)。
我們知道同時滿足 CAP 是不可能的,那么便需要有取舍。常見的注冊中心大致分為 CP 注冊中心以及 AP 注冊中心。
CP 注冊中心:比較典型的就是 Zookeeper、etcd 以及 Consul 了,犧牲可用性來保證了一致性,通過 Zab 協議或者 Raft 協議來保證一致性。
AP 注冊中心:犧牲一致性來保證可用性,感覺只能列出 Eureka 了。Eureka 每個服務器單獨保存節點列表,可能會出現不一致的情況。
從理論上來說,僅用于注冊中心,AP 型是遠比 CP 型合適的。可用性的需求遠遠高于一致性,一致性只要保證最終一致即可,而不一致的時候還可以使用各種容錯策略進行彌補。
保障高可用性其實還有很多辦法,例如集群部署或者多 IDC 部署等。Consul 就是多 IDC 部署保障可用性的典型例子,它使用了 wan gossip 來保持跨機房狀態同步。
②注冊方式
有兩種與注冊中心交互的方式,一種是通過應用內集成 SDK,另一種則是通過其他方式在應用外間接與注冊中心交互。
應用內:這應該就是最常見的方式了,客戶端與服務端都集成相關sdk與注冊中心進行交互。
例如選擇 Zookeeper 作為注冊中心,那么就可以使用 Curator SDK 進行服務的注冊與發現。
應用外:Consul 提供了應用外注冊的解決方案,Consul Agent 或者第三方 Registrator 可以監聽服務狀態,從而負責服務提供者的注冊或銷毀。
而 Consul Template 則可以做到定時從注冊中心拉取節點列表,并刷新 LB 配置(例如通過 Nginx 的 upstream),這樣就相當于完成了服務消費者端的負載均衡。
③存儲結構
注冊中心存儲相關信息一般采取目錄化的層次結構,一般分為服務-接口-節點信息。
同時注冊中心一般還會進行分組,分組的概念很廣,可以是根據機房劃分也可以根據環境劃分。
節點信息主要會包括節點的地址(ip 和端口號),還有一些節點的其他信息,比如請求失敗的重試次數、超時時間的設置等等。
當然很多時候,其實可能會把接口這一層給去掉,因為考慮到接口數量很多的情況下,過多的節點會造成很多問題,比如之前說的網絡風暴。
④服務健康監測
服務存活狀態監測也是注冊中心的一個必要功能。在 Zookeeper 中,每個客戶端都會與服務端保持一個長連接,并生成一個 Session。
在 Session 過期周期內,通過客戶端定時向服務端發送心跳包來檢測鏈路是否正常,服務端則重置下次 Session 的過期時間。
如果 Session 過期周期內都沒有檢測到客戶端的心跳包,那么就會認為它已經不可用了,將其從節點列表中移除。
⑤狀態變更通知
在注冊中心具備服務健康檢測能力后,還需要將狀態變更通知到客戶端。在 Zookeeper 中,可以通過監聽器 Watcher 的 Process 方法來獲取服務變更。
服務的遠程通信
在上面,服務消費者已經正確引用了服務,并發現了該服務的地址,那么如何向這個地址發起請求呢?
要解決服務間的遠程通信問題,我們需要考慮一些問題:
- 網絡 I/O 的處理
- 傳輸協議
- 序列化方式
①網絡 I/O 的處理
簡單來說,就是客戶端是怎么處理請求?服務端又是怎么處理請求的?
先從客戶端來說,我們創建連接的時機可以是從注冊中心獲取到節點信息的時候,但更多時候,我們會選擇在第一次請求發起調用的時候去創建連接。此外,我們往往會為該節點維護一個連接池,進行連接復用。
如果是異步的情況下,我們還需要為每一個請求編號,并維護一個請求池,從而在響應返回時找到對應的請求。當然這并不是必須的,很多框架會幫我們干好這些事情,比如 rxNetty。
從服務端來說,處理請求的方式就可以追溯到 Unix 的 5 種 IO 模型了。我們可以直接使用 Netty、MINA 等網絡框架來處理服務端請求,或者如果你有十分的興趣,可以自己實現一個通信框架。
②傳輸協議
最常見的當然是直接使用 HTTP 協議,使用雙方無需關注和了解協議內容,方便直接,但自然性能上會有所折損。
還有就是目前比較火熱的 HTTP2 協議,擁有二進制數據、頭部壓縮、多路復用等許多優良特性。
但從自身的實踐上看,HTTP2 要走到生產仍有一段距離,一個最簡單的例子,升級到 HTTP2 后所有的 header names 都變成小寫,同時不是 case-insenstive 了,這時候就會有兼容性問題。
當然如果追求更高效與可控的傳輸,可以定制私有協議并基于 TCP 進行傳輸。私有協議的定制需要通信雙方都了解其特性,設計上還需要注意預留好擴展字段,以及處理好粘包分包等問題。
③序列化方式
在網絡傳輸的前后,往往都需要在發送端進行編碼,在服務端進行解碼,這樣主要是為了在網絡傳輸時候減少數據傳輸量。
常用的序列化方式包括文本類的,例如 XML/JSON,還有二進制類型的,例如 Protobuf/Thrift 等。
在選擇序列化的考慮上:
一是性能,Protobuf 的壓縮大小和壓縮速度都會比 JSON 快很多,性能也更好。
二是兼容性上,相對來說,JSON 的前后兼容性會強一些,可以用于接口經常變化的場景。
在此還是需要強調,使用每一種序列化都需要了解過其特性,并在接口變更的時候拿捏好邊界。
例如 jackson 的 FAIL_ON_UNKNOW_PROPERTIES 屬性、kryo 的 CompatibleFieldSerializer、jdk 序列化會嚴格比較 serialVersionUID 等等。
微服務的穩定性
當一個單體應用改造成多個微服務之后,在請求調用過程中往往會出現更多的問題,通信過程中的每一個環節都可能出現問題。
而在出現問題之后,如果不加處理,還會出現鏈式反應導致服務雪崩。服務治理功能就是用來處理此類問題的。
我們將從微服務的三個角色:注冊中心、服務消費者以及服務提供者一一說起。
注冊中心如何保障穩定性
注冊中心主要是負責節點狀態的維護,以及相應的變更探測與通知操作。
一方面,注冊中心自身的穩定性是十分重要的。另一方面,我們也不能完全依賴注冊中心,需要時常進行類似注冊中心完全宕機后微服務如何正常運行的故障演練。
這一節,我們著重講的并不是注冊中心自身可用性保證,而更多的是與節點狀態相關的部分。
①節點信息的保障
我們說過,當注冊中心完全宕機后,微服務框架仍然需要有正常工作的能力。這得益于框架內處理節點狀態的一些機制。
本機內存:首先服務消費者會將節點狀態保持在本機內存中。
一方面由于節點狀態不會變更得那么頻繁,放在內存中可以減少網絡開銷。另一方面,當注冊中心宕機后,服務消費者仍能從本機內存中找到服務節點列表從而發起調用。
本地快照:我們說,注冊中心宕機后,服務消費者仍能從本機內存中找到服務節點列表。那么如果服務消費者重啟了呢?
這時候我們就需要一份本地快照了,即我們保存一份節點狀態到本地文件,每次重啟之后會恢復到本機內存中。
②服務節點的摘除
現在無論注冊中心工作與否,我們都能順利拿到服務節點了。但是不是所有的服務節點都是正確可用的呢?
在實際應用中,這是需要打問號的。如果我們不校驗服務節點的正確性,很有可能就調用到了一個不正常的節點上。所以我們需要進行必要的節點管理。
對于節點管理來說,我們有兩種手段,主要是去摘除不正確的服務節點。
注冊中心摘除機制:一是通過注冊中心來進行摘除節點。服務提供者會與注冊中心保持心跳,而一旦超出一定時間收不到心跳包,注冊中心就認為該節點出現了問題,會把節點從服務列表中摘除,并通知到服務消費者,這樣服務消費者就不會調用到有問題的節點上。
服務消費者摘除機制:二是在服務消費者這邊拆除節點。因為服務消費者自身是最知道節點是否可用的角色,所以在服務消費者這邊做判斷更合理,如果服務消費者調用出現網絡異常,就將該節點從內存緩存列表中摘除。
當然調用失敗多少次之后才進行摘除,以及摘除恢復的時間等等細節,其實都和客戶端熔斷類似,可以結合起來做。
一般來說,對于大流量應用,服務消費者摘除的敏感度會高于注冊中心摘除,兩者之間也不用刻意做同步判斷,因為過一段時間后注冊中心摘除會自動覆蓋服務消費者摘除。
③服務節點是可以隨便摘除/變更的么
上一節我們講可以摘除問題節點,從而避免流量調用到該節點上。但節點是可以隨便摘除的么?同時,這也包含"節點是可以隨便更新的么?"疑問。
頻繁變動:當網絡抖動的時候,注冊中心的節點就會不斷變動。這導致的后果就是變更消息會不斷通知到服務消費者,服務消費者不斷刷新本地緩存。
如果一個服務提供者有 100 個節點,同時有 100 個服務消費者,那么頻繁變動的效果可能就是 100*100,引起帶寬打滿。
這時候,我們可以在注冊中心這邊做一些控制,例如經過一段時間間隔后才能進行變更消息通知,或者打開開關后直接屏蔽不進行通知,或者通過一個概率計算來判斷需要向哪些服務消費者通知。
增量更新:同樣是由于頻繁變動可能引起的網絡風暴問題,一個可行的方案是進行增量更新,注冊中心只會推送那些變化的節點信息而不是全部,從而在頻繁變動的時候避免網絡風暴。
可用節點過少:當網絡抖動,并進行節點摘除過后,很可能出現可用節點過少的情況。
這時候過大的流量分配給過少的節點,導致剩下的節點難堪重負,罷工不干,引起惡化。
而實際上,可能節點大多數是可用的,只不過由于網絡問題與注冊中心未能及時保持心跳而已。
這時候,就需要在服務消費者這邊設置一個開關比例閾值,當注冊中心通知節點摘除,但緩存列表中剩下的節點數低于一定比例后(與之前一段時間相比),不再進行摘除,從而保證有足夠的節點提供正常服務。
這個值其實可以設置的高一些,例如百分之 70,因為正常情況下不會有頻繁的網絡抖動。當然,如果開發者確實需要下線多數節點,可以關閉該開關。
服務消費者如何保障穩定性
一個請求失敗了,最直接影響到的是服務消費者,那么在服務消費者這邊,有什么可以做的呢?
①超時
如果調用一個接口,但遲遲沒有返回響應的時候,我們往往需要設置一個超時時間,以防自己被遠程調用拖死。
超時時間的設置也是有講究的,設置的太長起的作用就小,自己被拖垮的風險就大,設置的太短又有可能誤判一些正常請求,大幅提升錯誤率。
在實際使用中,我們可以取該應用一段時間內的 P999 的值,或者取 p95 的值*2,具體情況需要自行定奪。
在超時設置的時候,對于同步與異步的接口也是有區分的。對于同步接口,超時設置的值不僅需要考慮到下游接口,還需要考慮上游接口。
而對于異步來說,由于接口已經快速返回,可以不用考慮上游接口,只需考慮自身在異步線程里的阻塞時長,所以超時時間也放得更寬一些。
②容錯機制
請求調用永遠不能保證成功,那么當請求失敗時候,服務消費者可以如何進行容錯呢?
通常容錯機制分為以下這些:
- FailTry:失敗重試。就是指最常見的重試機制,當請求失敗后視圖再次發起請求進行重試。
這樣從概率上講,失敗率會呈指數下降。對于重試次數來說,也需要選擇一個恰當的值,如果重試次數太多,就有可能引起服務惡化。
另外,結合超時時間來說,對于性能有要求的服務,可以在超時時間到達前的一段提前量就發起重試,從而在概率上優化請求調用。當然,重試的前提是冪等操作。
- FailOver:失敗切換。和上面的策略類似,只不過 FailTry 會在當前實例上重試。而 FailOver 會重新在可用節點列表中根據負載均衡算法選擇一個節點進行重試。
- FailFast:快速失敗。請求失敗了就直接報一個錯,或者記錄在錯誤日志中,這沒什么好說的。
另外,還有很多形形色色的容錯機制,大多是基于自己的業務特性定制的,主要是在重試上做文章,例如每次重試等待時間都呈指數增長等。
第三方框架也都會內置默認的容錯機制,例如 Ribbon 的容錯機制就是由 retry 以及 retry next 組成,即重試當前實例與重試下一個實例。
這里要多說一句,Ribbon 的重試次數與重試下一個實例次數是以笛卡爾乘積的方式提供的噢!
③熔斷
上一節將的容錯機制,主要是一些重試機制,對于偶然因素導致的錯誤比較有效,例如網絡原因。
但如果錯誤的原因是服務提供者自身的故障,那么重試機制反而會引起服務惡化。
這時候我們需要引入一種熔斷的機制,即在一定時間內不再發起調用,給予服務提供者一定的恢復時間,等服務提供者恢復正常后再發起調用。這種保護機制大大降低了鏈式異常引起的服務雪崩的可能性。
在實際應用中,熔斷器往往分為三種狀態,打開、半開以及關閉。引用一張 MartinFowler 畫的原理圖:
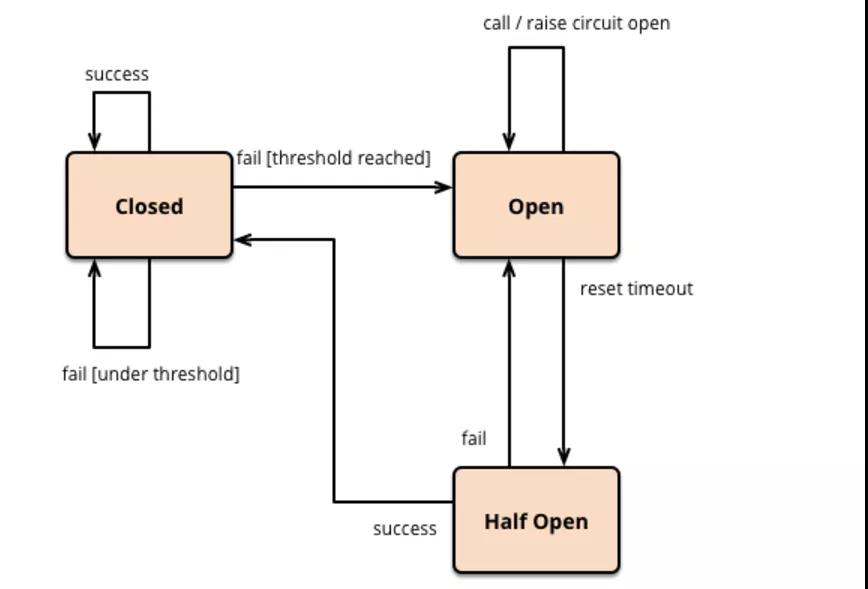
在普通情況下,斷路器處于關閉狀態,請求可以正常調用。當請求失敗達到一定閾值條件時,則打開斷路器,禁止向服務提供者發起調用。
當斷路器打開后一段時間,會進入一個半開的狀態,此狀態下的請求如果調用成功了則關閉斷路器,如果沒有成功則重新打開斷路器,等待下一次半開狀態周期。
斷路器的實現中比較重要的一點是失敗閾值的設置。可以根據業務需求設置失敗的條件為連續失敗的調用次數,也可以是時間窗口內的失敗比率,失敗比率通過一定的滑動窗口算法進行計算。
另外,針對斷路器的半開狀態周期也可以做一些花樣,一種常見的計算方法是周期長度隨著失敗次數呈指數增長。
具體的實現方式可以根據具體業務指定,也可以選擇第三方框架例如 Hystrix。
④隔離
隔離往往和熔斷結合在一起使用,還是以 Hystrix 為例,它提供了兩種隔離方式:
信號量隔離:使用信號量來控制隔離線程,你可以為不同的資源設置不同的信號量以控制并發,并相互隔離。當然實際上,使用原子計數器也沒什么不一樣。
線程池隔離:通過提供相互隔離的線程池的方式來隔離資源,相對來說消耗資源更多,但可以更好地應對突發流量。
⑤降級
降級同樣大多和熔斷結合在一起使用,當服務調用者這方斷路器打開后,無法再對服務提供者發起調用了,這時候可以通過返回降級數據來避免熔斷造成的影響。
降級往往用于那些錯誤容忍度較高的業務。同時降級的數據如何設置也是一門學問。
一種方法是為每個接口預先設置好可接受的降級數據,但這種靜態降級的方法適用性較窄。
還有一種方法,是去線上日志系統/流量錄制系統中撈取上一次正確的返回數據作為本次降級數據,但這種方法的關鍵是提供可供穩定抓取請求的日志系統或者流量采樣錄制系統。
另外,針對降級我們往往還會設置操作開關,對于一些影響不大的采取自動降級,而對于一些影響較大的則需進行人為干預降級。
服務提供者如何保障穩定性
①限流
限流就是限制服務請求流量,服務提供者可以根據自身情況(容量)給請求設置一個閾值,當超過這個閾值后就丟棄請求,這樣就保證了自身服務的正常運行。
閾值的設置可以針對兩個方面考慮:
- QPS,即每秒請求數
- 并發線程數
從實踐來看,我們往往會選擇后者,因為 QPS 高往往是由于處理能力高,并不能反映出系統"不堪重負"。
除此之外,我們還有許多針對限流的算法。例如令牌桶算法以及漏桶算法,主要針對突發流量的狀況做了優化。
第三方的實現中例如 guava rateLimiter 就實現了令牌桶算法。在此就不就細節展開了。
②重啟與回滾
限流更多的起到一種保障的作用,但如果服務提供者已經出現問題了,這時候該怎么辦呢?
這時候就會出現兩種狀況:一是本身代碼有 Bug,這時候一方面需要服務消費者做好熔斷降級等操作,一方面服務提供者這邊結合 DevOps 需要有快速回滾到上一個正確版本的能力。
更多的時候,我們可能僅僅碰到了與代碼無強關聯的單機故障,一個簡單粗暴的辦法就是自動重啟。
例如觀察到某個接口的平均耗時超出了正常范圍一定程度,就將該實例進行自動重啟。
當然自動重啟需要有很多注意事項,例如重啟時間是否放在晚上,以及自動重啟引起的與上述節點摘除一樣的問題,都需要考慮和處理。
在事后復盤的時候,如果當時沒有保護現場,就很難定位到問題原因。所以往往在一鍵回滾或者自動重啟之前,我們往往需要進行現場保護。
現場保護可以是自動的,例如:
- 一開始就給 jvm 加上打印 gc 日志的參數 -XX:+PrintGCDetails
- 或者輸出 oom 文件 -XX:+HeapDumpOnOutOfMemoryError
- 也可以配合 DevOps 自動腳本完成,當然手動也可以
一般來說我們會如下操作:
- 打印堆棧信息,jstak -l 'java進程PID'
- 打印內存鏡像,jmap -dump:format=b,file=hprof 'java進程PID'
- 保留 gc 日志,保留業務日志
③調度流量
除了以上這些措施,通過調度流量來避免調用到問題節點上也是非常常用的手段。
當服務提供者中的一臺機器出現問題,而其他機器正常時,我們可以結合負載均衡算法迅速調整該機器的權重至 0,避免流量流入,再去機器上進行慢慢排查,而不用著急第一時間重啟。
如果服務提供者分了不同集群/分組,當其中一個集群出現問題時,我們也可以通過路由算法將流量路由到正常的集群中。這時候一個集群就是一個微服務分組。
而當機房炸了、光纜被偷了等 IDC 故障時,我們又部署了多 IDC,也可以通過一些方式將流量切換到正常的 IDC,以供服務繼續正常運行。
切換流量同樣可以通過微服務的路由實現,但這時候一個 IDC 對應一個微服務分組了。
除此之外,使用 DNS 解析進行流量切換也是可以的,將對外域名的 VIP 從一個 IDC 切換到另一個 IDC。
作者:fredalxin
編輯:陶家龍
出處:https://fredal.xin/


















