老板要搞微服務,只能硬著頭皮上了...
微服務越來越火。很多互聯網公司,甚至一些傳統行業的系統都采用了微服務架構。
圖片來自 Pexels
體會到微服務帶來好處的同時,很多公司也明顯感受到微服務化帶來的一系列讓人頭疼的問題。
本文是筆者對自己多年微服務化經歷的總結。如果你正準備做微服務轉型,或者在微服務化過程中遇到了困難。此文很可能會幫到你!
正文開始前,為了讓各位讀友更好的理解本文內容,先花兩分鐘了解一下微服務的優缺點。
聊起微服務,很多朋友都了解微服務帶來的好處,羅列幾點:
- 模塊化,降低耦合。將單體應用按業務模塊拆分成多個服務,如果某個功能需要改動,大多數情況,我們只需要弄清楚并改動對應的服務即可。
只改動一小部分就能滿足要求,降低了其他業務模塊受影響的可能性。從而降低了業務模塊間的耦合性。
- 屏蔽與自身業務無關技術細節。例如,很多業務需要查詢用戶信息,在單體應用的情況下,所有業務場景都通過 DAO 去查詢用戶信息,隨著業務發展,并發量增加,用戶信息需要加緩存。
這樣所有業務場景都需要關注緩存,微服務化之后,緩存由各自服務維護,其他服務調用相關服務即可,不需要關注類似的緩存問題。
- 數據隔離,避免不同業務模塊間的數據耦合。不同的服務對應不同數據庫表,服務之間通過服務調用的方式來獲取數據。
- 業務邊界清晰,代碼邊界清晰。單體架構中不同的業務,代碼耦合嚴重,隨著業務量增長,業務復雜后,一個小功能點的修改就可能影響到其他業務點,開發質量不可控,測試需要回歸,成本持續提高。
- 顯著減少代碼沖突。在單體應用中,很多人在同一個工程上開發,會有大量的代碼沖突問題。微服務化后,按業務模塊拆分成多個服務,每個服務由專人負責,有效減少代碼沖突問題。
- 可復用,顯著減少代碼拷貝現象。
微服務確實帶來不少好處,那么微服務有沒有什么問題呢?答案是肯定的!
例如:
- 微服務系統穩定性問題。微服務化后服務數量大幅增加,一個服務故障就可能引發大面積系統故障。比如服務雪崩,連鎖故障。當一個服務故障后,依賴他的服務受到牽連也發生故障。
- 服務調用關系錯綜復雜,鏈路過長,問題難定位。微服務化后,服務數量劇增,大量的服務管理起來會變的更加復雜。由于調用鏈路變長,定位問題也會更加困難。
- 數據一致性問題。微服務化后單體系統被拆分成多個服務,各服務訪問自己的數據庫。而我們的一次請求操作很可能要跨多個服務,同時要操作多個數據庫的數據,我們發現以前用的數據庫事務不好用了。跨服務的數據一致性和數據完整性問題也就隨之而來了。
- 微服務化過程中,用戶無感知數據庫拆分、數據遷移的挑戰。
如何保障微服務系統穩定性?
互聯網系統為大量的 C 端用戶提供服務,如果隔三差五的出問題宕機,會嚴重影響用戶體驗,甚至導致用戶流失。所以穩定性對互聯網系統非常重要!
接下來筆者根據自己的實際經驗來聊聊基于微服務的互聯網系統的穩定性。
①雪崩效應產生原因,如何避免?
微服務化后,服務變多,調用鏈路變長,如果一個調用鏈上某個服務節點出問題,很可能引發整個調用鏈路崩潰,也就是所謂的雪崩效應。
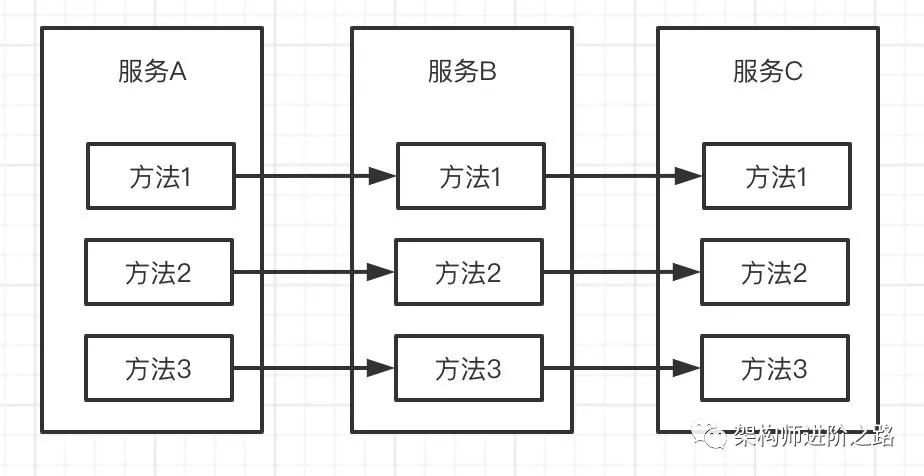
舉個例子,詳細理解一下雪崩。如上圖,現在有 A,B,C 三個服務,A 調 B,B 調 C。
假如 C 發生故障,B 方法 1 調用 C 方法 1 的請求不能及時返回,B 的線程會發生阻塞等待。
B 會在一定時間后因為線程阻塞耗盡線程池所有線程,這時 B 就會無法響應 A 的請求。
A 調用 B 的請求不能及時返回,A 的線程池線程資源也會逐漸被耗盡,最終 A 也無法對外提供服務。這樣就引發了連鎖故障,發生了雪崩。
縱向:C 故障引發 B 故障,B 故障引發 A 故障,最終發生連鎖故障。橫向:方法 1 出問題,導致線程阻塞,進而線程池線程資源耗盡,最終服務內所有方法都無法訪問,這就是“線程池污染”。
為了避免雪崩效應,我們可以從兩個方面考慮:
在服務間加熔斷:解決服務間縱向連鎖故障問題。比如在 A 服務加熔斷,當 B 故障時,開啟熔斷,A 調用 B 的請求不再發送到 B,直接快速返回。這樣就避免了線程等待的問題。
當然快速返回什么,Fallback 方案是什么,也需要根據具體場景,比如返回默認值或者調用其他備用服務接口。
如果你的場景適合異步通信,可以采用消息隊列,這樣也可以有效避免同步調用的線程等待問題。
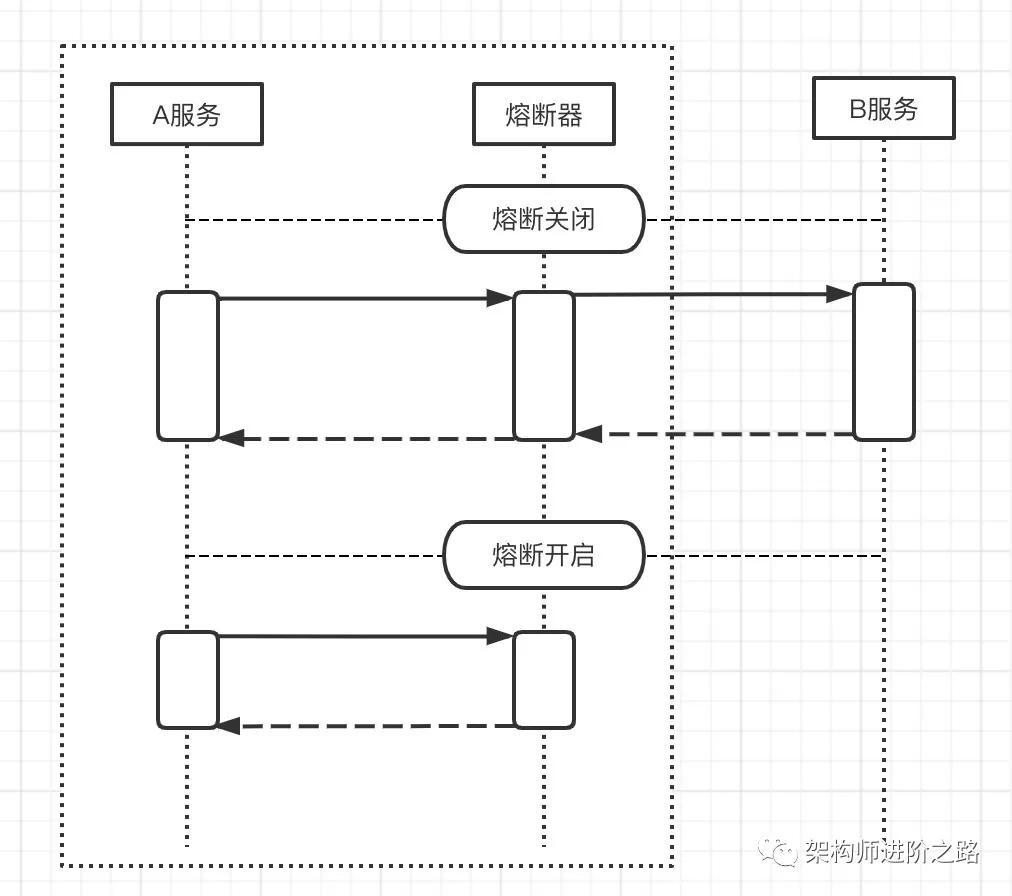
服務內(JVM 內)線程隔離:解決橫向線程池污染的問題。為了避免因為一個方法出問題導致線程等待最終引發線程資源耗盡的問題,我們可以對 Tomcat,Dubbo 等的線程池分成多個小線程組,每個線程組服務于不同的類或方法。
一個方法出問題,只影響自己不影響其他方法和類。常用開源熔斷隔離組件:Hystrix,Resilience4j。
②如何應對突發流量對服務的巨大壓力?
促銷活動或秒殺時,訪問量往往會猛增數倍。技術團隊在活動開始前一般都會根據預估訪問量適當增加節點,但是假如流量預估少了(實際訪問量遠大于預估的訪問量),系統就可能會被壓垮。
所以我們可以在網關層(Zuul,Gateway,Nginx 等)做限流,如果訪問量超出系統承載能力,就按照一定策略拋棄超出閾值的訪問請求(也要注意用戶體驗,可以給用戶返回一個友好的頁面提示)。
可以從全局,IP,userID 等多維度做限流。限流的兩個主要目的:
- 應對突發流量,避免系統被壓垮(全局限流和 IP 限流)
- 防刷,防止機器人腳本等頻繁調用服務(userID 限流和 IP 限流)
③數據冗余
在核心鏈路上,服務可以冗余它依賴的服務的數據,依賴的服務故障時,服務盡量做到自保。
比如訂單服務依賴庫存服務。我們可以在訂單服務冗余庫存數據(注意控制合理的安全庫存,防超賣)。
下單減庫存時,如果庫存服務掛了,我們可以直接從訂單服務取庫存。可以結合熔斷一起使用,作為熔斷的 Fallback(后備)方案。
④服務降級
可能很多人都聽過服務降級,但是又不知道降級是怎么回事。實際上,上面說的熔斷,限流,數據冗余,都屬于服務降級的范疇。
還有手動降級的例子,比如大促期間我們會關掉第三方物流接口,頁面上也關掉物流查詢功能,避免拖垮自己的服務。
這種降級的例子很多。不管什么降級方式,目的都是讓系統可用性更高,容錯能力更強,更穩定。關于服務降級詳見本文后面的內容。
⑤緩存要注意什么?
主要有如下三點:
緩存穿透:對于數據庫中根本不存在的值,請求緩存時要在緩存記錄一個空值,避免每次請求都打到數據庫
緩存雪崩:在某一時間緩存數據集中失效,導致大量請求穿透到數據庫,將數據庫壓垮。
可以在初始化數據時,差異化各個 key 的緩存失效時間,失效時間=一個較大的固定值+較小的隨機值。
緩存熱點。有些熱點數據訪問量會特別大,單個緩存節點(例如 Redis)無法支撐這么大的訪問量。
如果是讀請求訪問量大,可以考慮讀寫分離,一主多從的方案,用從節點分攤讀流量;如果是寫請求訪問量大,可以采用集群分片方案,用分片分攤寫流量。
以秒殺扣減庫存為例,假如秒殺庫存是 100,可以分成 5 片,每片存 20 個庫存。
⑥關于隔離的考慮
需要考慮如下幾點:
部署隔離:我們經常會遇到秒殺業務和日常業務依賴同一個服務,以及 C 端服務和內部運營系統依賴同一個服務的情況,比如說都依賴訂單服務。
而秒殺系統的瞬間訪問量很高,可能會對服務帶來巨大的壓力,甚至壓垮服務。內部運營系統也經常有批量數據導出的操作,同樣會給服務帶來一定的壓力。
這些都是不穩定因素。所以我們可以將這些共同依賴的服務分組部署,不同的分組服務于不同的業務,避免相互干擾。
數據隔離:極端情況下還需要緩存隔離,數據庫隔離。以秒殺為例,庫存和訂單的緩存(Redis)和數據庫需要單獨部署!
數據隔離后,秒殺訂單和日常訂單不在相同的數據庫,之后的訂單查詢怎么展示?可以采用相應的數據同步策略。
比如,在創建秒殺訂單后發消息到消息隊列,日常訂單服務收到消息后將訂單寫入日常訂單庫。注意,要考慮數據的一致性,可以使用事務型消息。
業務隔離:還是以秒殺為例。從業務上把秒殺和日常的售賣區分開來,把秒殺做為營銷活動,要參與秒殺的商品需要提前報名參加活動,這樣我們就能提前知道哪些商家哪些商品要參與秒殺。
可以根據提報的商品提前生成商品詳情靜態頁面并上傳到 CDN 預熱,提報的商品庫存也需要提前預熱,可以將商品庫存在活動開始前預熱到 Redis,避免秒殺開始后大量訪問穿透到數據庫。
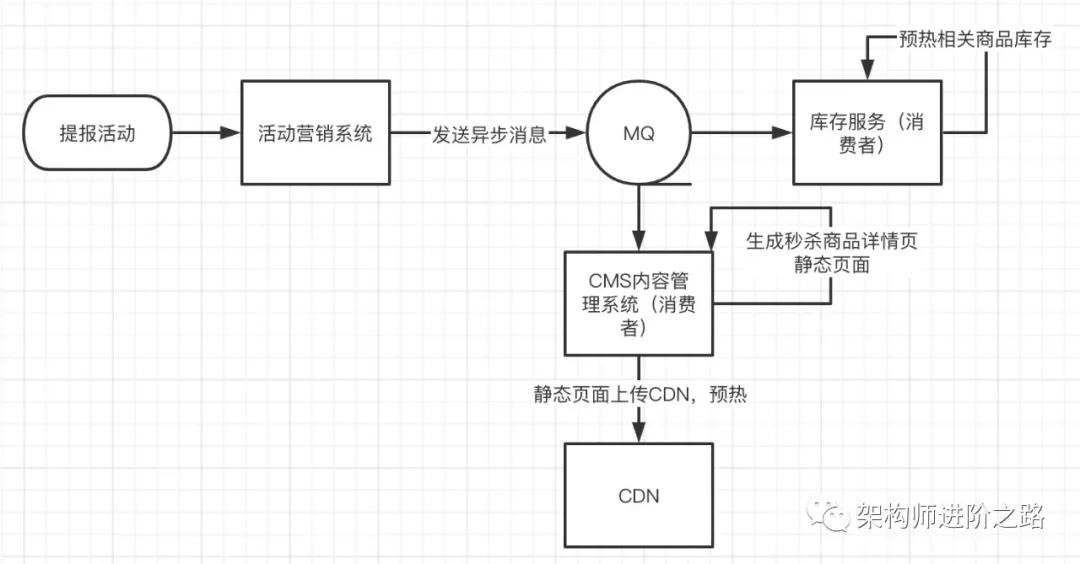
⑦CI 測試&性能測試
CI 測試,持續集成測試,在我們每次提交代碼到發布分支前自動構建項目并執行所有測試用例,如果有測試用例執行失敗,拒絕將代碼合并到發布分支,本次集成失敗。CI 測試可以保證上線質量,適用于用例不會經常變化的穩定業務。
性能測試,為了保證上線性能,所有用戶側功能需要進行性能測試。上線前要保證性能測試通過。而且要定期做全鏈路壓測,有性能問題可以及時發現。
⑧監控
我們需要一套完善的監控系統,系統出問題時能夠快速告警,最好是系統出問題前能提前預警。
包括系統監控(CPU,內存,網絡 IO,帶寬等監控),數據庫監控(QPS,TPS,慢查詢,大結果集等監控),緩存中間件監控(如 Redis),JVM 監控(堆內存,GC,線程等監控),全鏈路監控(pinpoint,skywaking,cat等),各種接口監控(QPS,TPS 等)
⑨CDN
可以充分利用 CDN。除了提高用戶訪問速度之外,頁面靜態化之后存放到 CDN,用 CDN 扛流量,可以大幅減少系統(源站)的訪問壓力。同時也減少了網站帶寬壓力。對系統穩定性非常有好處。
⑩避免單點問題
除了服務要多點部署外,網關,數據庫,緩存也要避免單點問題,至少要有一個 Backup,而且要可以自動發現上線節點和自動摘除下線和故障節點。
⑪網絡帶寬
避免帶寬成為瓶頸,促銷和秒殺開始前提前申請帶寬。不光要考慮外網帶寬,還要考慮內網帶寬,有些舊服務器網口是千兆網口,訪問量高時很可能會打滿。
此外,一套完善的灰度發布系統,可以讓上線更加平滑,避免上線大面積故障。DevOps 工具,CI,CD 對系統穩定性也有很大意義。
關于服務降級
提起服務降級,估計很多人都聽說過,但是又因為親身經歷不多,所以可能不是很理解。下面結合具體實例從多方面詳細闡述服務降級。
互聯網分布式系統中,經常會有一些異常狀況導致服務器壓力劇增,比如促銷活動時訪問量會暴增,為了保證系統核心功能的穩定性和可用性,我們需要一些應對策略。
這些應對策略也就是所謂的服務降級。下面根據筆者的實際經歷,跟大家聊聊服務降級那些事兒。希望對大家有所啟發!
①關閉次要功能
在服務壓力過大時,關閉非核心功能,避免核心功能被拖垮。
例如,電商平臺基本都支持物流查詢功能,而物流查詢往往要依賴第三方物流公司的系統接口。
物流公司的系統性能往往不會太好。所以我們經常會在雙 11 這種大型促銷活動期間把物流接口屏蔽掉,在頁面上也關掉物流查詢功能。這樣就避免了我們自己的服務被拖垮,也保證了重要功能的正常運行。
②降低一致性之讀降級
對于讀一致性要求不高的場景。在服務和數據庫壓力過大時,可以不讀數據庫,降級為只讀緩存數據。以這種方式來減小數據庫壓力,提高服務的吞吐量。
例如,我們會把商品評論評價信息緩存在 Redis 中。在服務和數據庫壓力過大時,只讀緩存中的評論評價數據,不在緩存中的數據不展示給用戶。
當然評論評價這種不是很重要的數據可以考慮用 NOSQL 數據庫存儲,不過我們曾經確實用 MySQL 數據庫存儲過評論評價數據。
③降低一致性之寫入降級
在服務壓力過大時,可以將同步調用改為異步消息隊列方式,來減小服務壓力并提高吞吐量。
既然把同步改成了異步也就意味著降低了數據一致性,保證數據最終一致即可。
例如,秒殺場景瞬間生成訂單量很高。我們可以采取異步批量寫數據庫的方式,來減少數據庫訪問頻次,進而降低數據庫的寫入壓力。
詳細步驟:后端服務接到下單請求,直接放進消息隊列,消費端服務取出訂單消息后,先將訂單信息寫入 Redis,每隔 100ms 或者積攢 100 條訂單,批量寫入數據庫一次。
前端頁面下單后定時向后端拉取訂單信息,獲取到訂單信息后跳轉到支付頁面。用這種異步批量寫入數據庫的方式大幅減少了數據庫寫入頻次,從而明顯降低了訂單數據庫寫入壓力。
不過,因為訂單是異步寫入數據庫的,就會存在數據庫訂單和相應庫存數據暫時不一致的情況,以及用戶下單后不能及時查到訂單的情況。
因為是降級方案,可以適當降低用戶體驗,所以我們保證數據最終一致即可。流程如下圖:
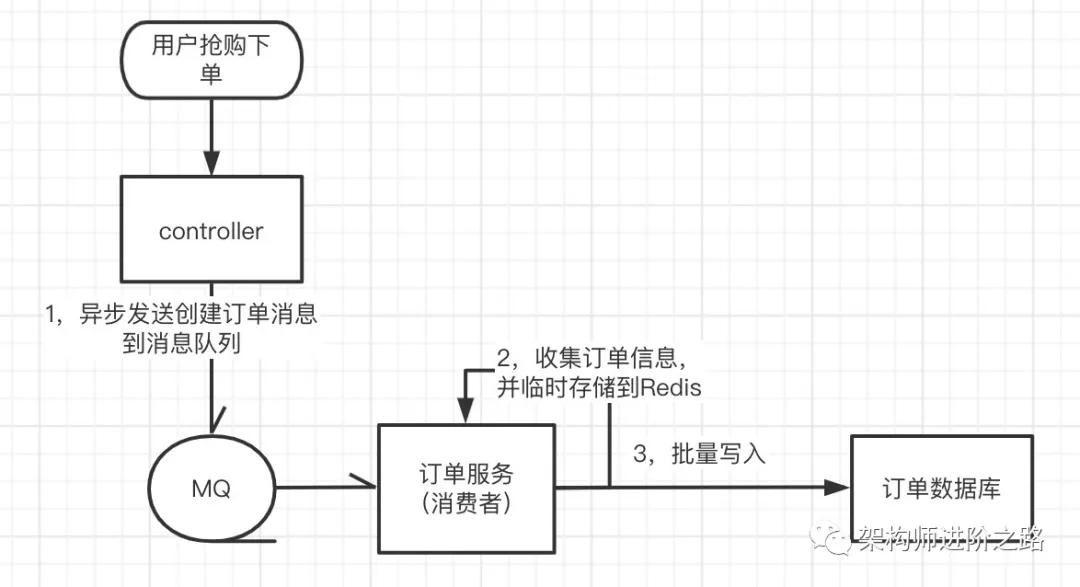
④屏蔽寫入
很多高并發場景下,查詢請求都會走緩存,這時數據庫的壓力主要是寫入壓力。所以對于某些不重要的服務,在服務和數據庫壓力過大時,可以關閉寫入功能,只保留查詢功能。這樣可以明顯減小數據庫壓力。
例如,商品的評論評價功能。為了減小壓力,大促前可以關閉評論評價功能,關閉寫接口,用戶只能查看評論評價。而大部分查詢請求走查詢緩存,從而大幅減小數據庫和服務的訪問壓力。
⑤數據冗余
服務調用者可以冗余它所依賴服務的數據。當依賴的服務故障時,服務調用者可以直接使用冗余數據。
例如,我之前在某家自營電商公司。當時的商品服務依賴于價格服務,獲取商品信息時,商品服務要調用價格服務獲取商品價格。
因為是自營電商,商品和 SKU 數量都不太多,一兩萬的樣子。所以我們在商品服務冗余了價格數據。當價格服務故障后,商品服務還可以從自己冗余的數據中取到價格。
當然這樣做價格有可能不是最新的,但畢竟這是降級方案,犧牲一些數據準確性,換來系統的可用性還是很有意義的!
注:由于一個商品會有多個價格,比如普通價,會員價,促銷直降價,促銷滿減價,所以我們把價格做成了單獨的服務。
數據冗余可以結合熔斷一起使用,實現自動降級。下面的熔斷部分會詳細說明。
⑥熔斷和 Fallback
熔斷是一種自動降級手段。當服務不可用時,用來避免連鎖故障,雪崩效應。發生在服務調用的時候,在調用方做熔斷處理。
熔斷的意義在于,調用方快速失敗(Fail Fast),避免請求大量阻塞。并且保護被調用方。
詳細解釋一下,假設 A 服務調用 B 服務,B 發生故障后,A 開啟熔斷:
- 對于調用方 A:請求在 A 直接快速返回,快速失敗,不再發送到 B。 避免因為 B 故障,導致 A 的請求線程持續等待,進而導致線程池線程和 CPU 資源耗盡,最終導致 A 無法響應,甚至整條調用鏈故障。
- 對于被調用方 B:熔斷后,請求被 A 攔截,不再發送到 B,B 壓力得到緩解,避免了仍舊存活的 B 被壓垮,B 得到了保護。
還是以電商的商品和價格服務為例。獲取商品信息時,商品服務要調用價格服務獲取商品價格。為了提高系統穩定性,我們要求各個服務要盡量自保。
所以我們在商品服務加了熔斷,當價格服務故障時,商品服務請求能夠快速失敗返回,保證商品服務不被拖垮,進而避免連鎖故障。
看到這,可能有讀者會問,快速失敗后價格怎么返回呢?因為是自營電商,商品和 SKU 數量都不太多,一兩萬的樣子。所以我們做了數據冗余,在商品服務冗余了價格數據。
這樣我們在熔斷后獲取價格的 Fallback 方案就變成了從商品服務冗余的數據去取價格。
下圖為商品服務熔斷關閉和開啟的對比圖:
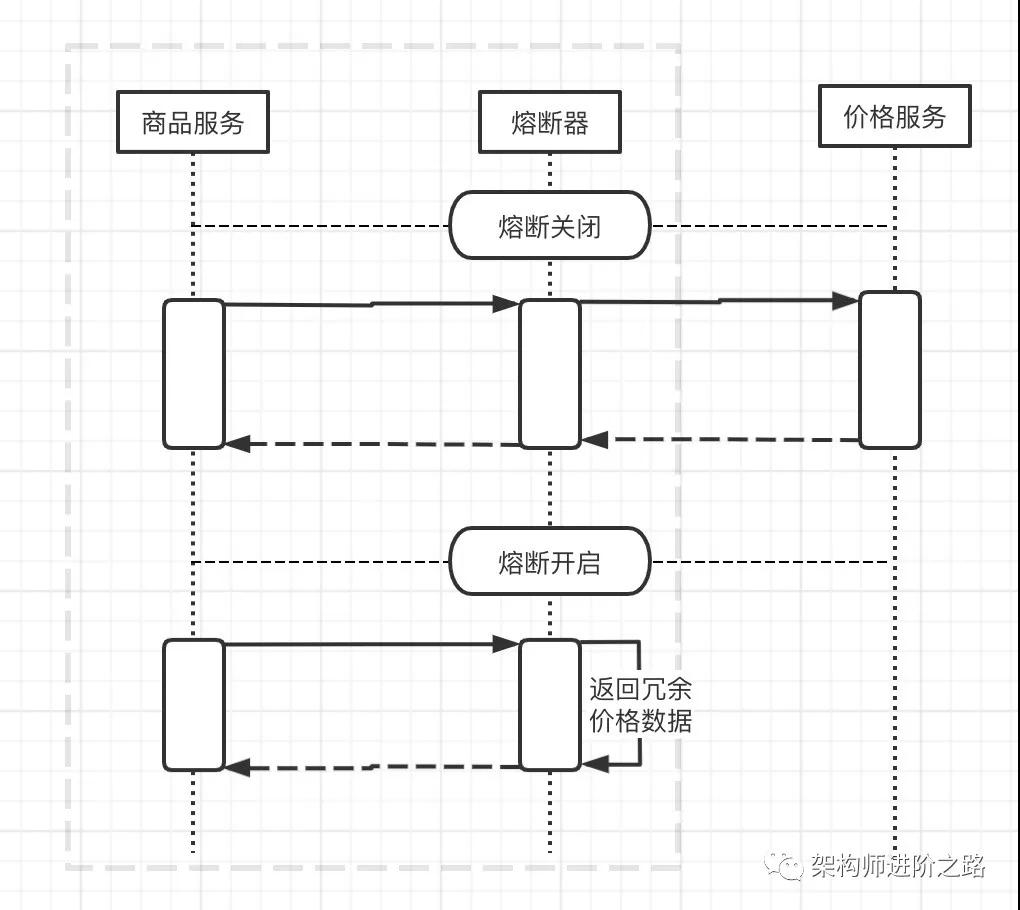
開源熔斷組件:Hystrix,Resilience4j 等。
⑦限流
說起服務降級,就不可避免的要聊到限流。我們先考慮一個場景,例如電商平臺要搞促銷活動,我們按照預估的峰值訪問量,準備了 30 臺機器。
但是活動開始后,實際參加的人數比預估的人數翻了 5 倍,這就遠遠超出了我們的服務處理能力,給后端服務、緩存、數據庫等帶來巨大的壓力。
隨著訪問請求的不斷涌入,最終很可能造成平臺系統崩潰。對于這種突發流量,我們可以通過限流來保護后端服務。
因為促銷活動流量來自于用戶,用戶的請求會先經過網關層再到后端服務,所以網關層是最合適的限流位置,如下圖:
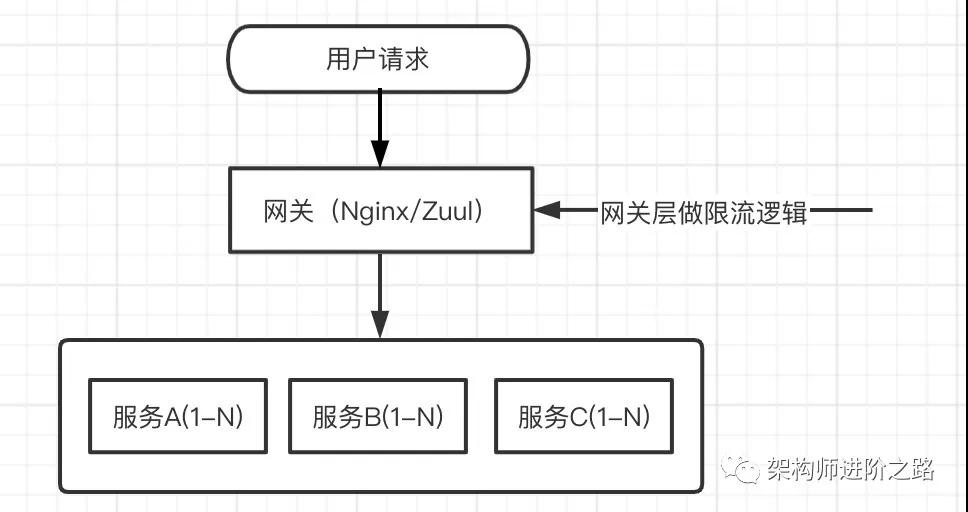
另外,考慮到用戶體驗問題,我們還需要相應的限流頁面。當某些用戶的請求被限流攔截后,把限流頁面返回給用戶。頁面如下圖:

另外一個場景,假如有一個核心服務,有幾十個服務都調用他。如果其中一個服務調用者出了 Bug,頻繁調用這個核心服務,可能給這個核心服務造成非常大的壓力,甚至導致這個核心服務無法響應。
同時也會影響到調用他的幾十個服務。所以每個服務也要根據自己的處理能力對調用者進行限制。
對于服務層的限流,我們一般可以利用 Spring AOP,以攔截器的方式做限流處理。這種做法雖然可以解決問題,但是問題也比較多。
比如一個服務中有 100 個接口需要限流,我們就要寫 100 個攔截器。而且限流閾值經常需要調整,又涉及到動態修改的問題。
為了應對這些問題,很多公司會有專門的限流平臺,新增限流接口和閾值變動可以直接在限流平臺上配置。
關于限流,還有很多細節需要考慮,比如限流算法、毛刺現象等。篇幅原因,這些問題就不在本文討論了。
開源網關組件:Nginx,Zuul,Gateway,阿里 Sentinel 等。
⑧服務降級總結和思考
上面我們結合具體案例解釋了多種降級方式。實際上,關于服務降級的方式和策略,并沒有什么定式,也沒有標準可言。
上面的降級方式也沒有涵蓋所有的情況。不同公司不同平臺的做法也不完全一樣。
不過,所有的降級方案都要以滿足業務需求為前提,都是為了提高系統的可用性,保證核心功能正常運行。
⑨降級分類
一般我們可以把服務降級分為手動和自動兩類。手動降級應用較多,可以通過開關的方式開啟或關閉降級。
自動降級,比如熔斷和限流等屬于自動降級的范疇。大多手動降級也可以做成自動的方式,可以根據各種系統指標設定合理閾值,在相應指標達到閾值上限自動開啟降級。
在很多場景下,由于業務過于復雜,需要參考的指標太多,自動降級實現起來難度會比較大,而且也很容易出錯。
所以在考慮做自動降級之前一定要充分做好評估,相應的自動降級方案也要考慮周全。
⑩大規模分布式系統如何降級?
在大規模分布式系統中,經常會有成百上千的服務。在大促前往往會根據業務的重要程度和業務間的關系批量降級。
這就需要技術和產品提前對業務和系統進行梳理,根據梳理結果確定哪些服務可以降級,哪些服務不可以降級,降級策略是什么,降級順序怎么樣。
大型互聯網公司基本都會有自己的降級平臺,大部分降級都在平臺上操作,比如手動降級開關,批量降級順序管理,熔斷閾值動態設置,限流閾值動態設置等等。
本節的主要目的是通過具體實例,讓大家了解服務降級,并提供一些降級的思路。具體的降級方式和方案還是要取決于實際的業務場景和系統狀況。
微服務架構下數據一致性問題
服務化后單體系統被拆分成多個服務,各服務訪問自己的數據庫。而我們的一次請求操作很可能要跨多個服務,同時要操作多個數據庫的數據,我們發現以前用的數據庫事務不好用了。那么基于微服務的架構如何保證數據一致性呢?
好,咱們這次就盤一盤分布式事務,最終一致,補償機制,事務型消息!
提起這些,大家可能會想到兩階段提交,XA,TCC,Saga,還有最近阿里開源的 Seata(Fescar),這些概念網上一大堆文章,不過都太泛泛,不接地氣,讓人看了云里霧里。
我們以 TCC 分布式事務和 RocketMQ 事務型消息為例,做詳細分享!這個弄明白了,也就清楚分布式事務,最終一致,補償機制這些概念啦!
①TCC 分布式事務
TCC(Try-Confirm-Cancel)是分布式事務的一種模式,可以保證不同服務的數據最終一致。
目前有不少 TCC 開源框架,比如 Hmily,ByteTCC,TCC-Transaction (我們之前用過 Hmily 和公司架構組自研組件)。下面以電商下單流程為例對 TCC 做詳細闡述。
流程圖如下:
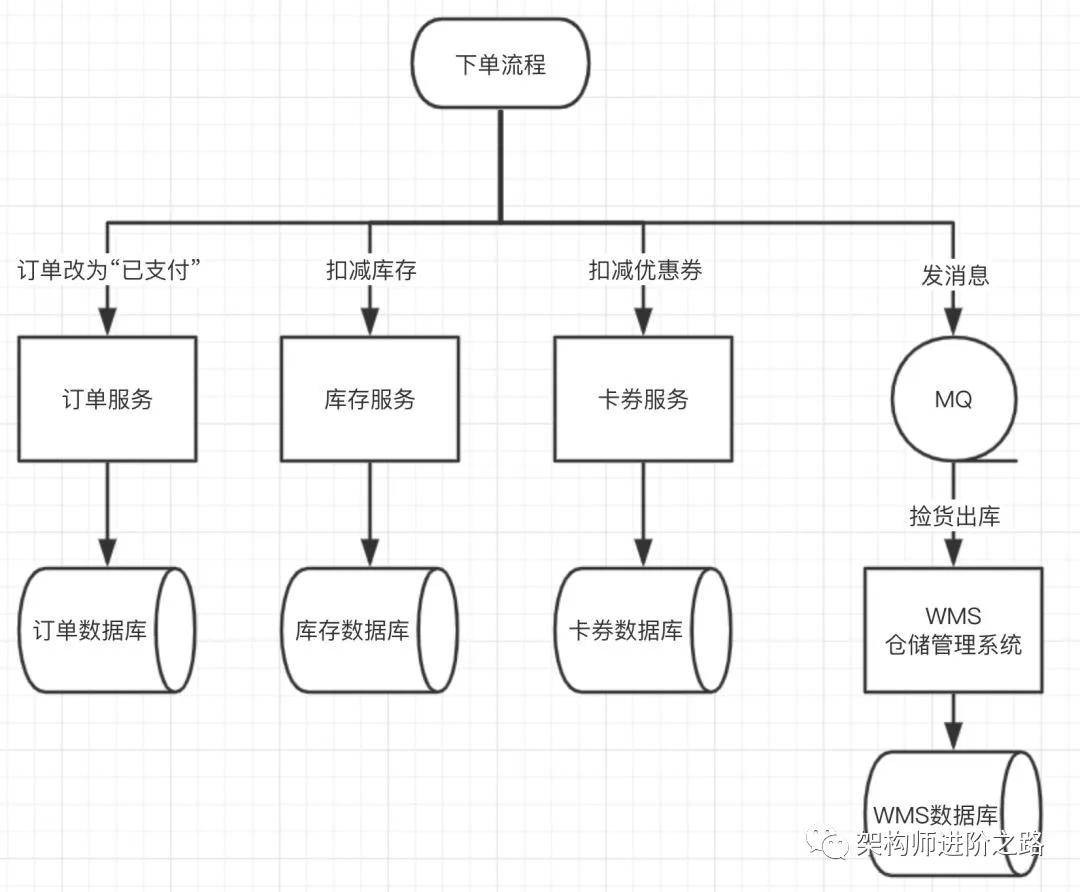
基本步驟如下:
- 修改訂單狀態為“已支付”
- 扣減庫存
- 扣減優惠券
- 通知 WMS(倉儲管理系統)撿貨出庫(異步消息)
我們先看扣減庫存,更新訂單狀態和扣減優惠券這三步同步調用,通知 WMS 的異步消息會在后面的“基于消息的最終一致”部分詳細闡述!
下面是偽代碼,不同公司的產品邏輯會有差異,相關代碼邏輯也可能會有不同,大家不用糾結代碼邏輯正確性。
- public void makePayment() {
- orderService.updateStatus(OrderStatus.Payed); //訂單服務更新訂單為已支付狀態
- inventoryService.decrStock(); //庫存服務扣減庫存
- couponService.updateStatus(couponStatus.Used); //卡券服務更新優惠券為已使用狀態
- }
看完這段代碼,大家可能覺得很簡單!那么有什么問題嗎?答案是肯定的。沒法保證數據一致性,也就是說不能保證這幾步操作全部成功或者全部失敗!
因為這幾步操作是在分布式環境下進行的,每個操作分布在不同的服務中,不同的服務又對應不同的數據庫,本地事務已經用不上了!
假如第一步更新訂單為“已支付”成功了,第二步扣減庫存時,庫存服務掛了或者網絡出問題了,導致扣減庫存失敗。你告訴用戶支付成功了,但是庫存沒扣減。這怎么能行!
接下來,我們來看看TCC是如何幫我們解決這個問題并保證數據最終一致的。
TCC 分為兩個階段:
- Try(預留凍結相關業務資源,設置臨時狀態,為下個階段做準備)
- Confirm 或者 Cancel(Confirm:對資源進行最終操作,Cancel:取消資源)
第一階段 Try:
- 更新訂單狀態:此時因為還沒真正完成整個流程,訂單狀態不能直接改成已支付狀態。可以加一個臨時狀態 Paying,表明訂單正在支付中,支付結果暫時還不清楚!
- 凍結庫存:假設現在可銷售庫存 stock 是 10,這單扣減 1 個庫存,別直接把庫存減掉,而是在表中加一個凍結字段 locked_stock,locked_stock 加 1,再給 stock 減 1,這樣就相當于凍結了 1 個庫存。兩個操作放在一個本地事務里。
- 更新優惠券狀態:優惠券加一個臨時狀態 Inuse,表明優惠券正在使用中,具體有沒有正常被使用暫時還不清楚!
第二階段 Confirm:假如第一階段幾個 Try 操作都成功了!既然第一階段已經預留了庫存,而且訂單狀態和優惠券狀態也設置了臨時狀態,第二階段的確認提交從業務上來說應該沒什么問題了。
Confirm 階段我們需要做下面三件事:
- 先將訂單狀態從 Paying 改為已支付 Payed,訂單狀態也完成了。
- 再將凍結的庫存恢復 locked_stock 減 1,stock 第一階段已經減掉 1 是 9 了,到此扣減庫存就真正完成了。
- 再將優惠券狀態從 Inuse 改為 Used,表明優惠券已經被正常使用。
第二階段 Cancel,假如第一階段失敗了:
- 先將訂單狀態從 Paying 恢復為待支付 UnPayed。
- 再將凍結的庫存還回到可銷售庫存中,stock 加 1 恢復成 10,locked_stock 減 1,可以放在一個本地事務完成。
- 再將優惠券狀態從 Inuse 恢復為未使用 Unused。
基于 Hmily 框架的代碼:
- //訂單服務
- public class OrderService{
- //tcc接口
- @Hmily(confirmMethod = "confirmOrderStatus", cancelMethod = "cancelOrderStatus")
- public void makePayment() {
- 更新訂單狀態為支付中
- 凍結庫存,rpc調用
- 優惠券狀態改為使用中,rpc調用
- }
- public void confirmOrderStatus() {
- 更新訂單狀態為已支付
- }
- public void cancelOrderStatus() {
- 恢復訂單狀態為待支付
- }
- }
- //庫存服務
- public class InventoryService {
- //tcc接口
- @Hmily(confirmMethod = "confirmDecr", cancelMethod = "cancelDecr")
- public void lockStock() {
- //防懸掛處理(下面有說明)
- if (分支事務記錄表沒有二階段執行記錄)
- 凍結庫存
- else
- return;
- }
- public void confirmDecr() {
- 確認扣減庫存
- }
- public void cancelDecr() {
- 釋放凍結的庫存
- }
- }
- //卡券服務
- public class CouponService {
- //tcc接口
- @Hmily(confirmMethod = "confirm", cancelMethod = "cancel")
- public void handleCoupon() {
- //防懸掛處理(下面有說明)
- if (分支事務記錄表沒有二階段執行記錄)
- 優惠券狀態更新為臨時狀態Inuse
- else
- return;
- }
- public void confirm() {
- 優惠券狀態改為Used
- }
- public void cancel() {
- 優惠券狀態恢復為Unused
- }
- }
問題 1:有些朋友可能會問了,這些關于流程的邏輯也要手動編碼嗎?這也太麻煩了吧!
實際上 TCC 分布式事務框架幫我們把這些事都干了。比如我們前面提到的 Hmily,ByteTCC,TCC-transaction 這些框架。
因為 Try,Confirm,Cancel 這些操作都在 TCC 分布式事務框架控制范圍之內,所以 Try 的各個步驟成功了或者失敗了。
框架本身都知道,Try 成功了框架就會自動執行各個服務的 Confirm,Try 失敗了框架就會執行各個服務的 Cancel(各個服務內部的 TCC 分布式事務框架會互相通信)。所以我們不用關心流程,只需要關注業務代碼就可以啦!
問題 2:仔細想想,好像還有問題!假如 Confirm 階段更新訂單狀態成功了,但是扣減庫存失敗了怎么辦呢?
比如網絡出問題了或者庫存服務(宕機,重啟)出問題了。當然,分布式事務框架也會考慮這些場景,框架會記錄操作日志。
假如 Confirm 階段扣減庫存失敗了,框架會不斷重試調用庫存服務直到成功(考慮性能問題,重試次數應該有限制)。Cancel 過程也是一樣的道理。
注意,既然需要重試,我們就要保證接口的冪等性。什么?不太懂冪等性。簡單說:一個操作不管請求多少次,結果都要保證一樣。這里就不詳細介紹啦!
再考慮一個場景,Try 階段凍結庫存的時候,因為是 RPC 遠程調用,在網絡擁塞等情況下,是有可能超時的。
假如凍結庫存時發生超時,TCC 框架會回滾(Cancel)整個分布式事務,回滾完成后凍結庫存請求才到達參與者(庫存服務)并執行,這時被凍結的庫存就沒辦法處理(恢復)了。
這種情況稱之為“懸掛”,也就是說預留的資源后續無法處理。解決方案:第二階段已經執行,第一階段就不再執行了,可以加一個“分支事務記錄表”,如果表里有相關第二階段的執行記錄,就不再執行 Try(上面代碼有防懸掛處理)。
有人可能注意到還有些小紕漏,對,加鎖,分布式環境下,我們可以考慮對第二階段執行記錄的查詢和插入加上分布式鎖,確保萬無一失。
②基于消息的最終一致
還是以上面的電商下單流程為例:
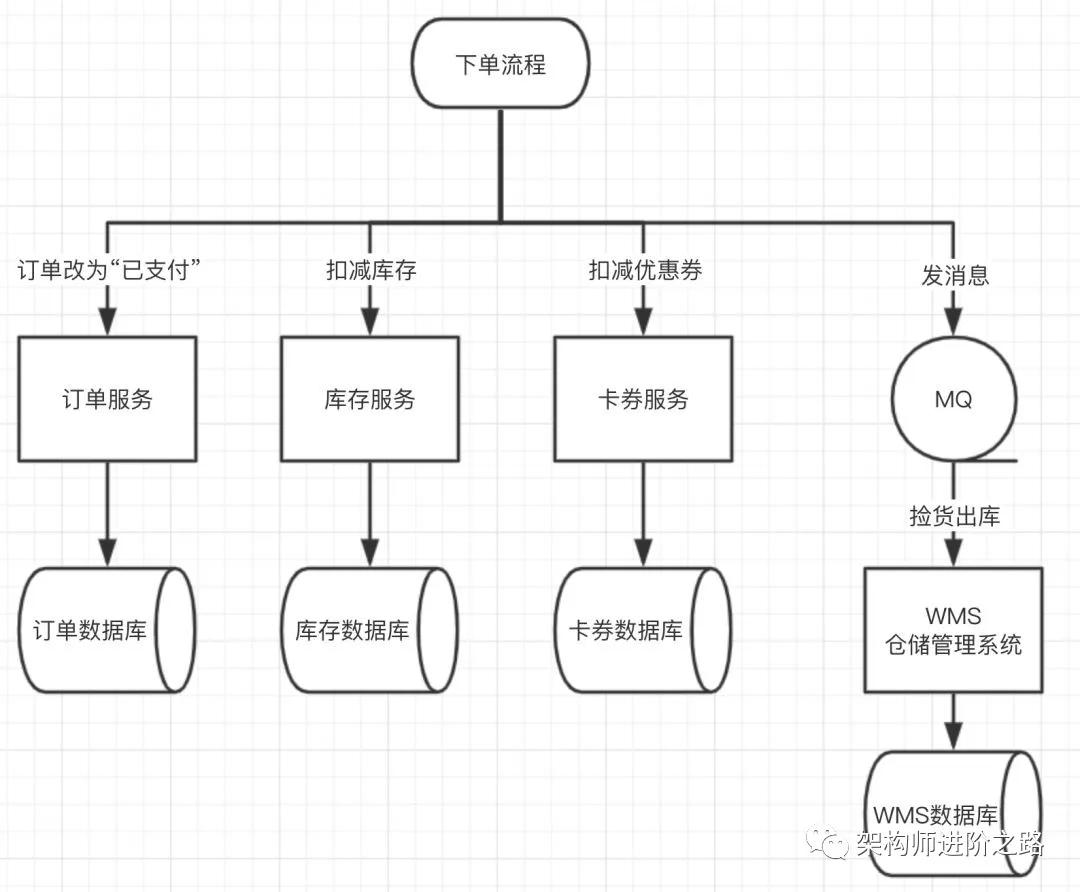
上圖,下單流程最后一步,通知 WMS 撿貨出庫,是異步消息走消息隊列。
- public void makePayment() {
- orderService.updateStatus(OrderStatus.Payed); //訂單服務更新訂單為已支付狀態
- inventoryService.decrStock(); //庫存服務扣減庫存
- couponService.updateStatus(couponStatus.Used); //卡券服務更新優惠券為已使用狀態
- 發送MQ消息撿貨出庫; //發送消息通知WMS撿貨出庫
- }
按上面代碼,大家不難發現問題!如果發送撿貨出庫消息失敗,數據就會不一致!
有人說我可以在代碼上加上重試邏輯和回退邏輯,發消息失敗就重發,多次重試失敗所有操作都回退。
這樣一來邏輯就會特別復雜,回退失敗要考慮,而且還有可能消息已經發送成功了,但是由于網絡等問題發送方沒得到 MQ 的響應,這些問題都要考慮進來!
幸好,有些消息隊列幫我們解決了這些問題。比如阿里開源的 RocketMQ(目前已經是 Apache 開源項目),4.3.0 版本開始支持事務型消息(實際上早在貢獻給 Apache 之前曾經支持過事務消息,后來被閹割了,4.3.0 版本重新開始支持事務型消息)。
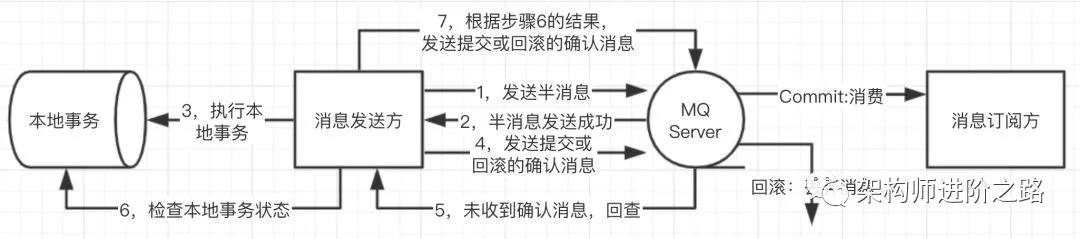
先看看 RocketMQ 發送事務型消息的流程:
- 發送半消息(所有事務型消息都要經歷確認過程,從而確定最終提交或回滾(拋棄消息),未被確認的消息稱為“半消息”或者“預備消息”,“待確認消息”)。
- 半消息發送成功并響應給發送方。
- 執行本地事務,根據本地事務執行結果,發送提交或回滾的確認消息。
- 如果確認消息丟失(網絡問題或者生產者故障等問題),MQ 向發送方回查執行結果。
- 根據上一步驟回查結果,確定提交或者回滾(拋棄消息)。
看完事務型消息發送流程,有些讀者可能沒有完全理解,不要緊,我們來分析一下!
問題 1:假如發送方發送半消息失敗怎么辦?
半消息(待確認消息)是消息發送方發送的,如果失敗,發送方自己是知道的并可以做相應處理。
問題 2:假如發送方執行完本地事務后,發送確認消息通知 MQ 提交或回滾消息時失敗了(網絡問題,發送方重啟等情況),怎么辦?
沒關系,當 MQ 發現一個消息長時間處于半消息(待確認消息)的狀態,MQ 會以定時任務的方式主動回查發送方并獲取發送方執行結果。
這樣即便出現網絡問題或者發送方本身的問題(重啟,宕機等),MQ 通過定時任務主動回查發送方基本都能確認消息最終要提交還是回滾(拋棄)。
當然出于性能和半消息堆積方面的考慮,MQ 本身也會有回查次數的限制。
問題 3:如何保證消費一定成功呢?
RocketMQ 本身有 Ack 機制,來保證消息能夠被正常消費。如果消費失敗(消息訂閱方出錯,宕機等原因),RocketMQ 會把消息重發回 Broker,在某個延遲時間點后(默認 10 秒后)重新投遞消息。
結合上面幾個同步調用 Hmily 完整代碼如下:
- //TransactionListener是rocketmq接口用于回調執行本地事務和狀態回查
- public class TransactionListenerImpl implements TransactionListener {
- //執行本地事務
- @Override
- public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
- 記錄orderID,消息狀態鍵值對到共享map中,以備MQ回查消息狀態使用;
- return LocalTransactionState.COMMIT_MESSAGE;
- }
- //回查發送者狀態
- @Override
- public LocalTransactionState checkLocalTransaction(MessageExt msg) {
- String status = 從共享map中取出orderID對應的消息狀態;
- if("commit".equals(status))
- return LocalTransactionState.COMMIT_MESSAGE;
- else if("rollback".equals(status))
- return LocalTransactionState.ROLLBACK_MESSAGE;
- else
- return LocalTransactionState.UNKNOW;
- }
- }
- //訂單服務
- public class OrderService{
- //tcc接口
- @Hmily(confirmMethod = "confirmOrderStatus", cancelMethod = "cancelOrderStatus")
- public void makePayment() {
- 1,更新訂單狀態為支付中
- 2,凍結庫存,rpc調用
- 3,優惠券狀態改為使用中,rpc調用
- 4,發送半消息(待確認消息)通知WMS撿貨出庫 //創建producer時這冊TransactionListenerImpl
- }
- public void confirmOrderStatus() {
- 更新訂單狀態為已支付
- }
- public void cancelOrderStatus() {
- 恢復訂單狀態為待支付
- }
- }
- //庫存服務
- public class InventoryService {
- //tcc接口
- @Hmily(confirmMethod = "confirmDecr", cancelMethod = "cancelDecr")
- public void lockStock() {
- //防懸掛處理
- if (分支事務記錄表沒有二階段執行記錄)
- 凍結庫存
- else
- return;
- }
- public void confirmDecr() {
- 確認扣減庫存
- }
- public void cancelDecr() {
- 釋放凍結的庫存
- }
- }
- //卡券服務
- public class CouponService {
- //tcc接口
- @Hmily(confirmMethod = "confirm", cancelMethod = "cancel")
- public void handleCoupon() {
- //防懸掛處理
- if (分支事務記錄表沒有二階段執行記錄)
- 優惠券狀態更新為臨時狀態Inuse
- else
- return;
- }
- public void confirm() {
- 優惠券狀態改為Used
- }
- public void cancel() {
- 優惠券狀態恢復為Unused
- }
- }
如果執行到 TransactionListenerImpl.executeLocalTransaction 方法,說明半消息已經發送成功了。
也說明 OrderService.makePayment 方法的四個步驟都執行成功了,此時 TCC 也到了 Confirm 階段。
所以在 TransactionListenerImpl.executeLocalTransaction 方法里可以直接返回 LocalTransactionState.COMMIT_MESSAGE 讓 MQ 提交這條消息。
同時將該訂單信息和對應的消息狀態保存在共享 map 里,以備確認消息發送失敗時 MQ 回查消息狀態使用。
微服務化過程,無感知數據遷移
微服務化,其中一個重要意義在于數據隔離,即不同的服務對應各自的數據庫表,避免不同業務模塊間數據的耦合。
這也就意味著微服務化過程要拆分現有數據庫,把單體數據庫根據業務模塊拆分成多個,進而涉及到數據遷移。
數據遷移過程我們要注意哪些關鍵點呢?
- 第一,保證遷移后數據準確不丟失,即每條記錄準確而且不丟失記錄。
- 第二,不影響用戶體驗(尤其是訪問量高的C端業務需要不停機平滑遷移)。
- 第三,保證遷移后的性能和穩定性。
數據遷移我們經常遇到的兩個場景:
- 業務重要程度一般或者是內部系統,數據結構不變,這種場景下可以采用掛從庫,數據同步完找個訪問低谷時間段,停止服務,然后將從庫切成主庫,再啟動服務。簡單省時,不過需要停服避免切主庫過程數據丟失。
- 重要業務,并發高,數據結構改變。這種場景一般需要不停機平滑遷移。下面就重點介紹這部分經歷。
互聯網行業,很多業務訪問量很大,即便凌晨低谷時間,仍然有相當的訪問量,為了不影響用戶體驗,很多公司對這些業務會采用不停機平滑遷移的方式。
因為對老數據遷移的同時,線上還不斷有用戶訪問,不斷有數據產生,不斷有數據更新,所以我們不但要考慮老數據遷移的問題,還要考慮數據更新和產生新數據的問題。下面介紹一下我們之前的做法。
關鍵步驟如下:
①開啟雙寫,新老庫同時寫入(涉及到代碼改動)。注意:任何對數據庫的增刪改都要雙寫。
對于更新操作,如果新庫沒有相關記錄,先從老庫查出記錄更新后寫入數據庫;為了保證寫入性能,老庫寫完后,可以采用消息隊列異步寫入新庫。
同時寫兩個庫,不在一個本地事務,有可能出現數據不一致的情況,這樣就需要一定的補償機制來保證兩個庫數據最終一致。下一篇文章會分享最終一致性解決方案
②將某時間戳之前的老數據遷移到新庫(需要腳本程序做老數據遷移,因為數據結構變化比較大的話,從數據庫層面做數據遷移就很困難了)。
注意兩點:
- 時間戳一定要選擇開啟雙寫后的時間點,避免部分老數據被漏掉。
- 遷移過程遇到記錄沖突直接忽略(因為第一步有更新操作,直接把記錄拉到了新庫);遷移過程一定要記錄日志,尤其是錯誤日志。
③第二步完成后,我們還需要通過腳本程序檢驗數據,看新庫數據是否準確以及有沒有漏掉的數據。
④數據校驗沒問題后,開啟雙讀,起初新庫給少部分流量,新老兩庫同時讀取,由于時間延時問題,新老庫數據可能有些不一致,所以新庫讀不到需要再讀一遍老庫。
逐步將讀流量切到新庫,相當于灰度上線的過程。遇到問題可以及時把流量切回老庫。
⑤讀流量全部切到新庫后,關閉老庫寫入(可以在代碼里加上可熱配開關),只寫新庫。
⑥遷移完成,后續可以去掉雙寫雙讀相關無用代碼。
第二步的老數據遷移腳本程序和第三步的檢驗程序可以工具化,以后再做類似的數據遷移可以復用。
目前各云服務平臺也提供數據遷移解決方案,大家有興趣也可以了解一下!
全鏈路 APM 監控
在體會到微服務帶來好處的同時,很多公司也會明顯感受到微服務化后那些讓人頭疼的問題。
比如,服務化之后調用鏈路變長,排查性能問題可能要跨多個服務,定位問題更加困難。
服務變多,服務間調用關系錯綜復雜,以至于很多工程師不清楚服務間的依賴和調用關系,之后的系統維護過程也會更加艱巨。諸如此類的問題還很多!
這時就迫切需要一個工具幫我們解決這些問題,于是 APM 全鏈路監控工具就應運而生了。
有開源的 Pinpoint、Skywalking 等,也有收費的 Saas 服務聽云、OneAPM 等。有些實力雄厚的公司也會自研 APM。
下面我們介紹一下如何利用開源 APM 工具 Pinpoint 應對上述問題。
拓撲圖:
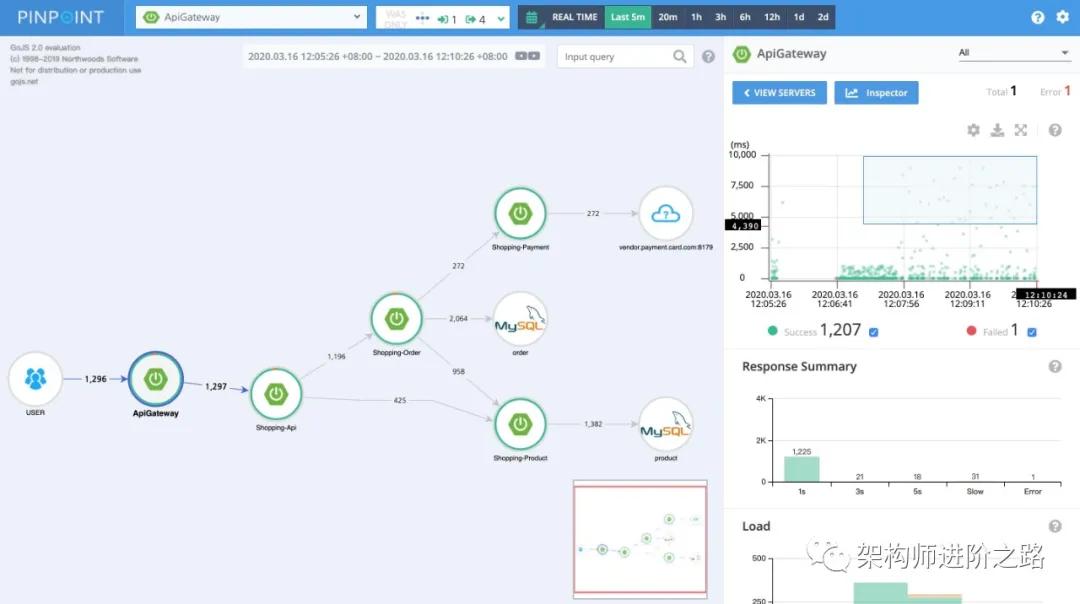
微服務化后,服務數量變多,服務間調用關系也變得更復雜,以至于很多工程師不清楚服務間的依賴和調用關系,給系統維護帶來很多困難。
通過拓撲圖我們可以清晰地看到服務與服務,服務與數據庫,服務與緩存中間件的調用和依賴關系。對服務關系了如指掌之后,也可以避免服務間循依賴、循環調用的問題。
請求調用棧(Call Stack)監控:
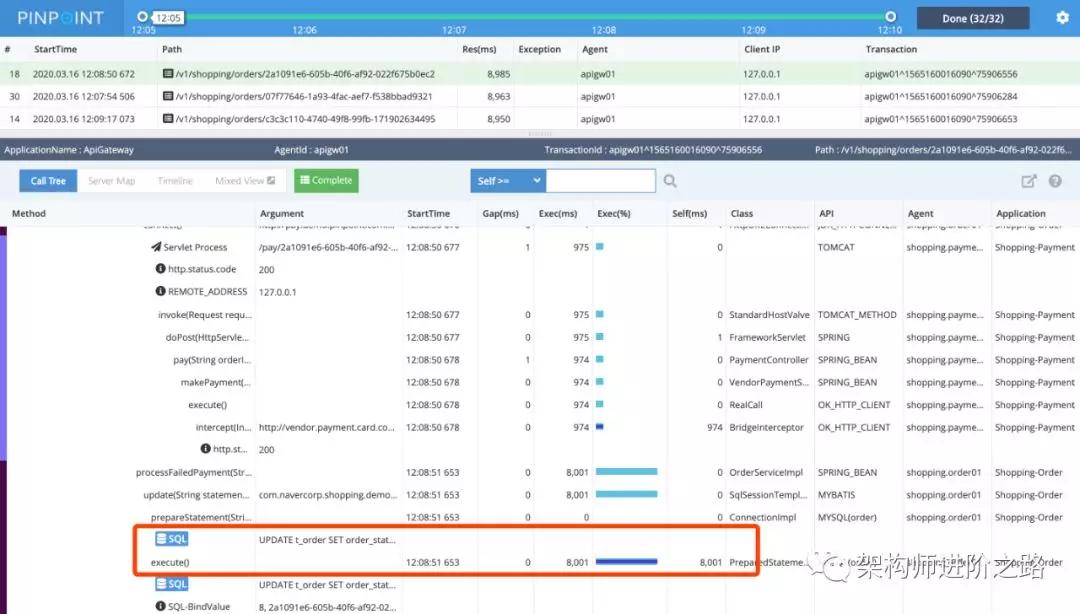
微服務化后,服務變多,調用鏈路變長,跨多個服務排查問題會更加困難。上圖是一個請求的調用棧,我們可以清晰看到一次請求調用了哪些服務和方法、各個環節的耗時以及發生在哪個服節點。
上圖的請求耗時過長,根據監控(紅框部分)我們可以看到時間主要消耗在數據庫 SQL 語句上。
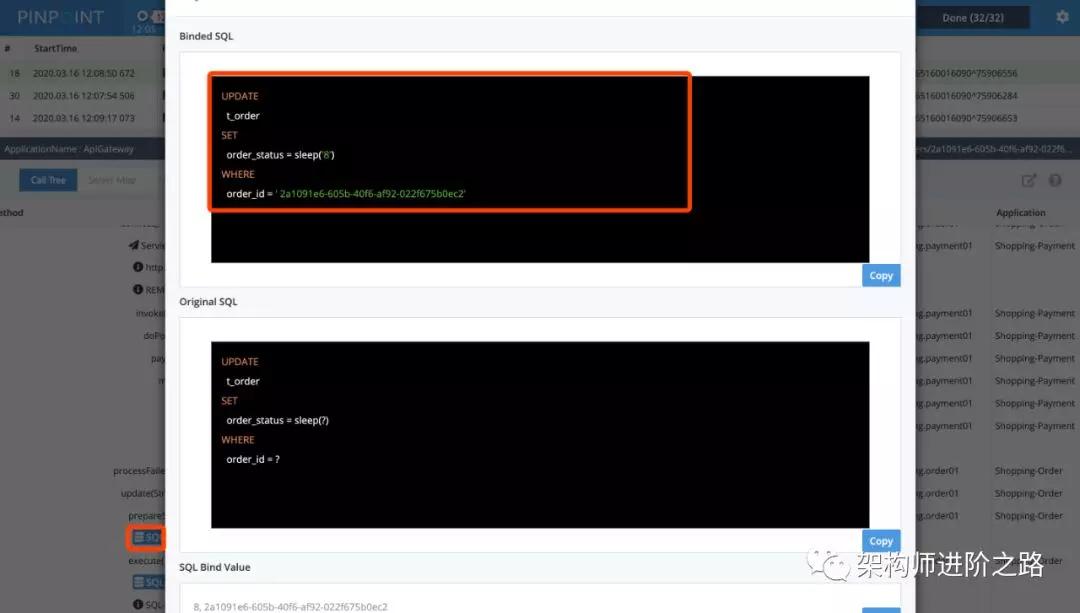
點擊數據庫圖表還可以看詳細 SQL 語句,如下圖:
如果發生錯誤,會顯示為紅色,錯誤原因也會直接顯示出來。如下圖:
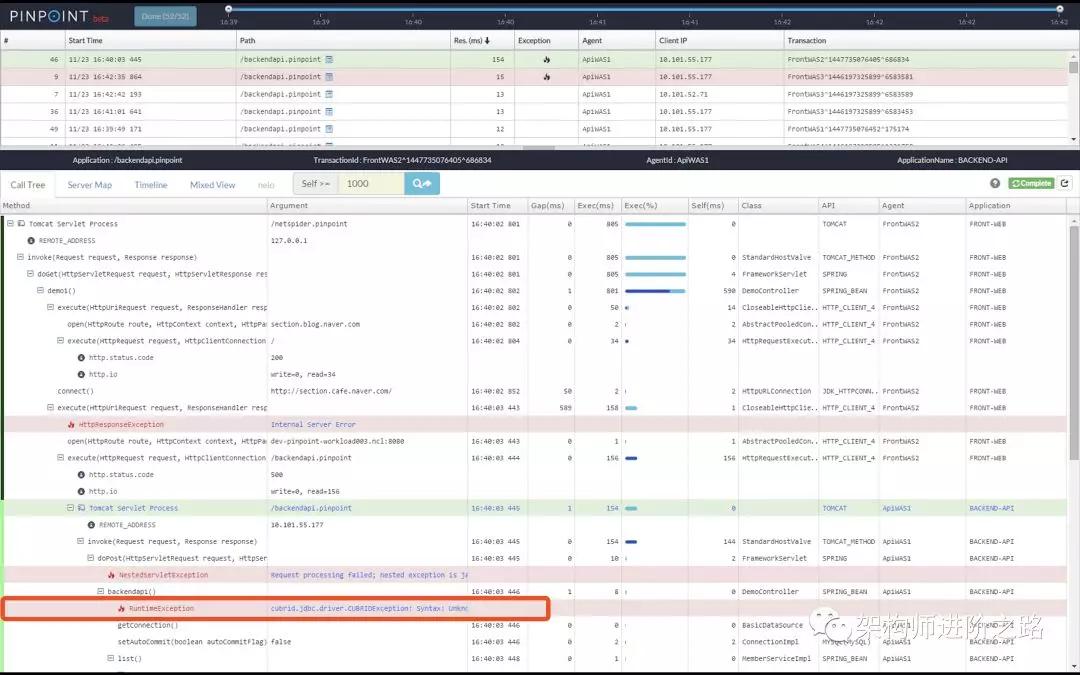
類似性能問題和錯誤的線上排查。我們如果通過查日志的傳統辦法,可能會耗費大量的時間。但是通過 APM 工具分分鐘就可以搞定了!
請求 Server Map:
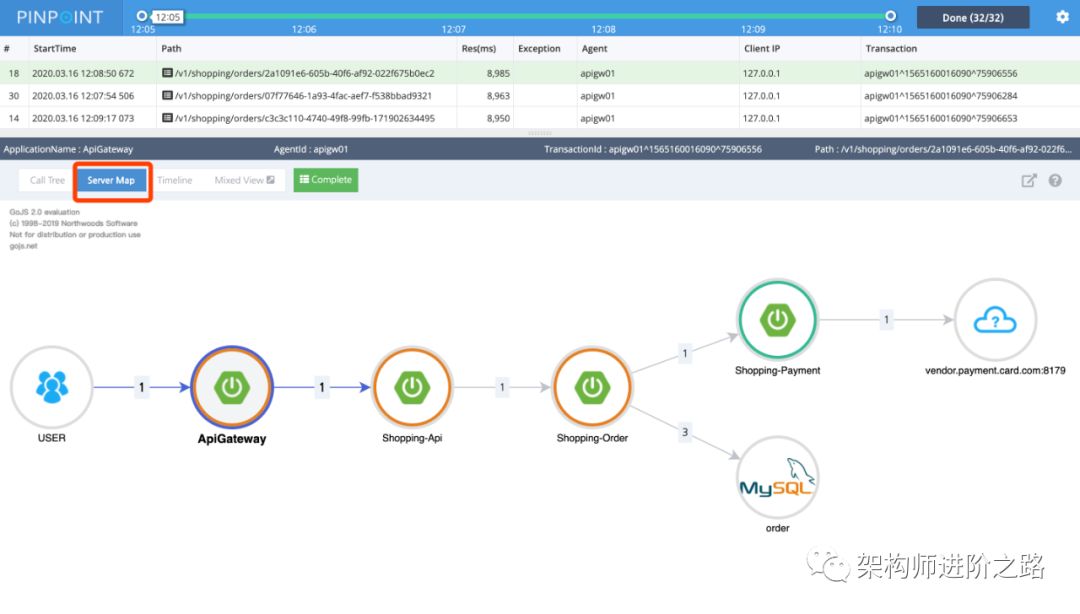
Server Map 是 Pinpoint 另一個比較重要的功能。如上圖,我們不但能清晰地看到一個請求的訪問鏈路,而且還能看到每個節點的訪問次數,為系統優化提供了有力的依據。
如果一次請求訪問了多次數據庫,說明代碼邏輯可能有必要優化了!
JVM 監控:
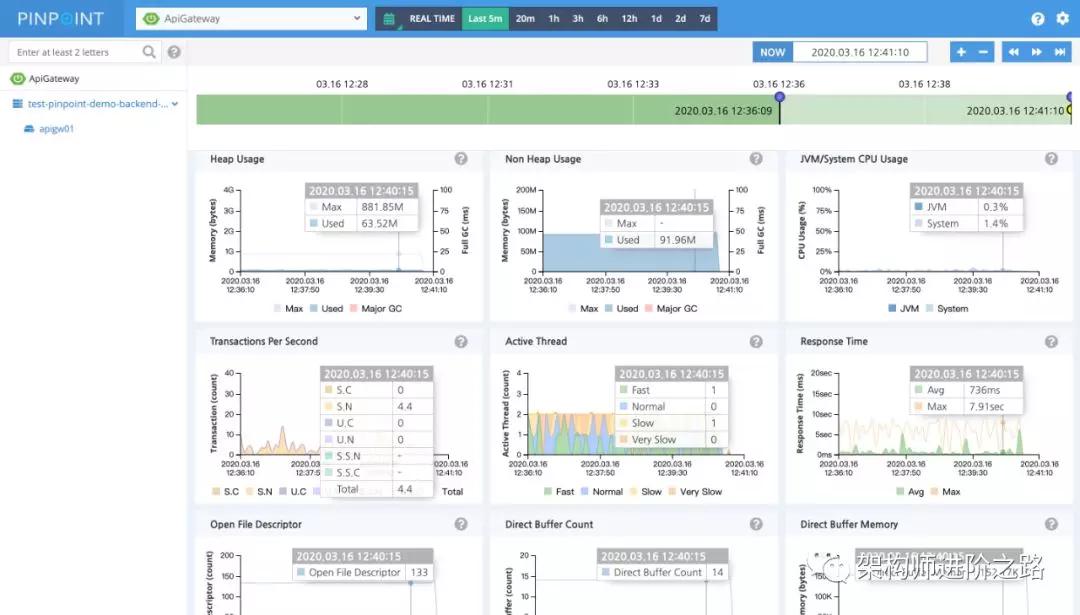
此外,Pinpoint 還支持堆內存,活躍線程,CPU,文件描述符等監控。
關于微服務化,我們就分享這么多。希望對大家有幫助。
作者:二馬讀書
簡介:曾任職于阿里巴巴,每日優鮮等互聯網公司,任技術總監,15 年電商互聯網經歷。
編輯:陶家龍
出處:轉載自微信公眾號架構師進階之路(ID:ermadushu)